
Accueil >> Vie de campus >> Vie du personnel >> Personnels de l'Université
Enseignant et/ou chercheur
M. Serge FLEURY
- Corps :
- MCF - Université Sorbonne Nouvelle - Paris 3
- Coordonnées :
- ILPGA 19 rue des Bernardins 75005 Paris
- Téléphone :
- 0685467347
- Mél :
- serge.fleury@sorbonne-nouvelle.fr
- Adresse site personnel :
- http://www.tal.univ-paris3.fr/sfleury/
- Structure(s) de rattachement :
-
CLESTHIA - Langage, systèmes, discours - EA 7345
ED 622 - Sciences du langage
Département : Institut de linguistique et phonétique générales et appliquées (ILPGA)
Discipline(s) enseignée(s)
Informatique pour la linguistiqueLicence
- Outillage linguistique : Le web en tant que corpus
- Informatique et Industries de la langue
- Outils de traitement de corpus
- Programmation pour le TAL en Perl
- Statistique textuelle
Master "Ingénierie Linguistique" (plurital.org)
Fonction(s)
Maître de Conférences en linguistique informatiqueThèmes de recherche
Activités de recherche
- Textométrie
- Traitement Automatique du Langage
- Analyse automatique
- Langages à prototypes
- Documents Structurés
- Hypertextes
- Analyse du Web
- Web Mining
- Collecte et analyse de corpus sur le Web
- Traitements quantitatifs
Projets en cours
Nouveaux projets :
Publications
Développement de logiciels
Le Trameur : http://www.tal.univ-paris3.fr/trameur/
(version en ligne)
iTrameur : http://www.tal.univ-paris3.fr/trameur/iTrameur/
Dans une perspective lexicométrique / textométrique, représentation du texte en machine sous la forme d'une Trame et d'un Cadre (i.e le métier textométrique), pour ensuite réaliser des calculs textométriques.
L'objectif principal de la textométrie est de compter des éléments (des contenus textuels) dans des ensembles (des contenants regroupant des unités élémentaires d'un texte ou des zones de texte couvrant un certain nombre ou un certain type d'unités élémentaires).
- Les contenus se réalisent sous la forme de ressources textuelles (une séquence de caractères organisée en phrases, en paragraphes etc.).
- Les contenants existent sous la forme de système de masques ou de calques que l'on peut définir sur les contenus. Il s'agit de systèmes d'annotations que l'on peut définir sur tout ou partie des zones textuelles, ces annotations constituant en retour des accès sur les parties textuelles qu'elles définissent (le marquage des phrases ou des paragraphes étant un exemple d'annotation particulier pour décrire un certain niveau de la structure du texte).
Le processus de comptage nécessite au préalable d'identifier les contenus et les contenants. Ce préalable consiste à expliciter une segmentation du texte conduisant à la mise au jour d'une Trame sur laquelle des annotations pourront se greffer ultérieurement.
Trame et Cadre : les objets de la textométrie
A partir d'un texte segmenté, la numérotation des items découpés dans le texte de départ permet de constituer un système de coordonnées sur le texte dans lequel chaque item est repéré par son numéro d'ordre. Nous appelons ce système de coordonnées sur la séquence textuelle : la Trame textométrique. Ce même système de coordonnées permet de définir et de localiser, au sein du corpus, des zones textuelles (zones formées par une suite d'items consécutifs, entre la position x1 et la position x2, réunion d'un certain nombre de zones de ce type, etc.). 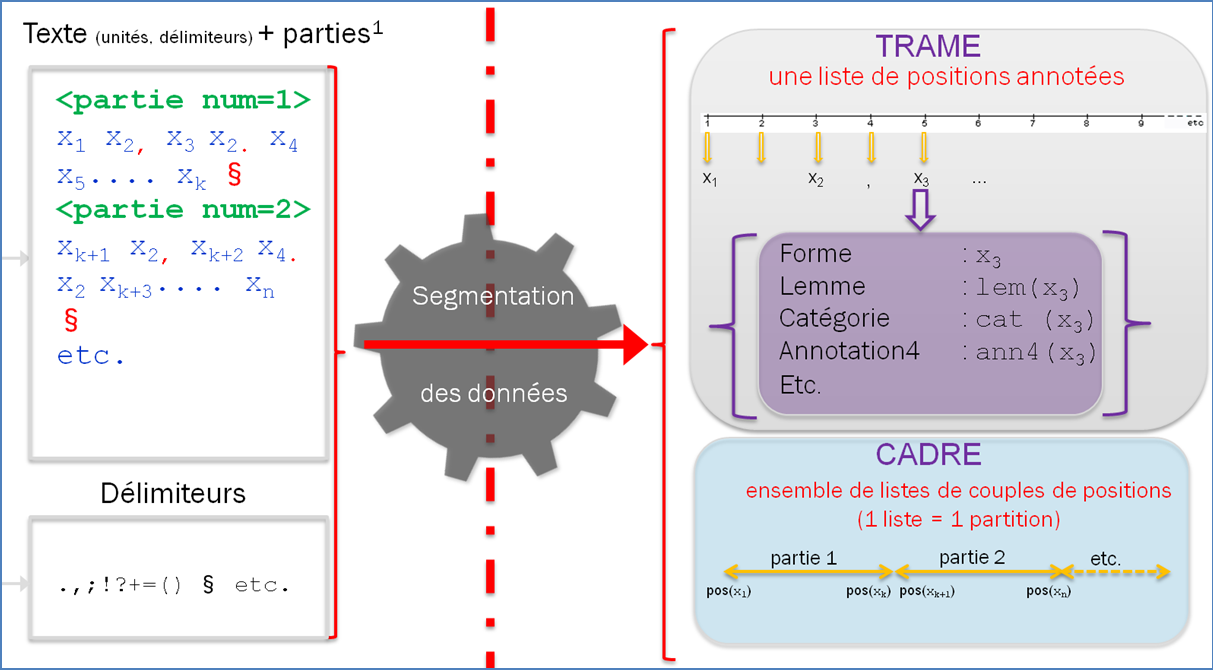
La définition d'une Trame textométrique sur un corpus de textes permet de décrire les systèmes de zones qui correspondent aux contenants de l'analyse textométrique (parties, paragraphes, phrases, sections, chapitres etc.). On peut rassembler les descriptions relatives aux systèmes de contenants dans une structure de données particulière le Cadre textométrique.
La transmission d'une ressource textuelle constituée sous la forme Trame/Cadre (une base textométrique) constitue une solution suffisante pour servir de base à toute exploration textométrique ultérieure.
Le Trameur intègre le programme treetagger : système d'étiquetage automatique des catégories grammaticales des mots avec lemmatisation. Le Trameur est disponible en 2 versions : la " version Tk " et la "version console".
Lectures :
[Söze-Duval, 2008], Keyser Söze-Duval. Pour une textométrie opérationnelle (DOC)
[Fleury, 2013], Serge Fleury. Le Trameur. Propositions de description et d’implémentation des objets textométriques, (PDF), (texte en cours).
Documentation : format PDF, format HTML
mkAlign 2.00 http://www.tal.univ-paris3.fr/mkAlign/
Le programme mkAlign permet de construire ou de corriger un alignement de 2 textes puis de produire une version XML du bi-texte aligné. Version exécutable pour Windows. Doc HTML, Doc PDF
URL projet : http://www.tal.univ-paris3.fr/mkAlign/.
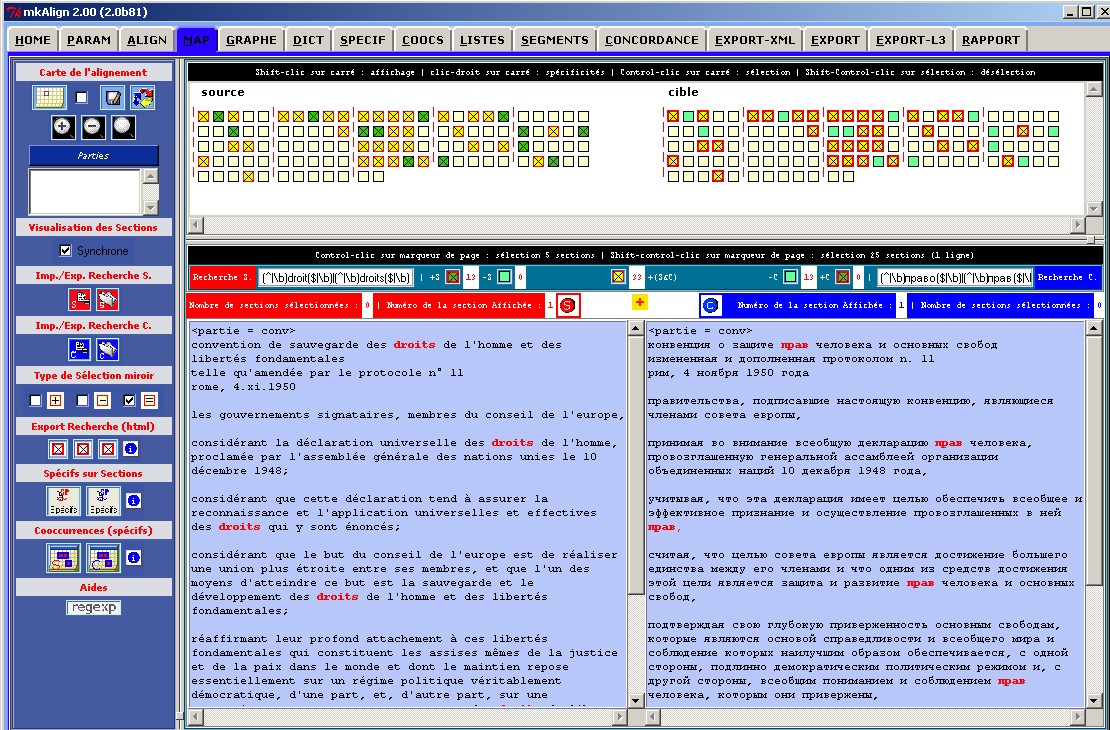
La notion de corpus parallèle, qui émerge actuellement dans les travaux de différents chercheurs comme : corpus comportant plusieurs volets qui correspondent chacun à une version d'un même texte dans deux ou plusieurs langues différentes, renvoie à des situations connues de coexistence de textes présentant des liens forts dans leur structuration. Le traitement de corpus parallèles suppose une phase préalable d'alignement , c'est-à-dire de mise en correspondance dans chacun des volets de différents types d'unités textuelles [Zimina, 2004]. Aligner des corpus de textes originaux et de leurs traductions c'est mettre en relation des unités textuelles qui se correspondent. On peut établir des correspondances entre des unités de différents niveaux : mots, syntagmes, phrases, paragraphes, sections, etc. Le programme mkAlign permet de construire, corriger et visualiser un alignement de deux textes via un éditeur à double entrée. Il permet d'afficher simultanément les textes source et cible pour y rajouter ou corriger des segments équivalents. Ce programme n'est pas (seulement) un aligneur automatique. Il est conçu pour aider l'utilisateur dans la création, l'alignement, la correction et la validation de textes traduits. L'utilisateur garde la maîtrise sur l'ensemble de ces processus, depuis la mise en correspondance initiale des segments équivalents jusqu'à l'export final du bi-texte produit. Il appartient à l'utilisateur de construire l'alignement et de définir son degré de précision (résolution). Cette résolution peut varier pour mettre en évidence les correspondances entre les segments textuels des différents niveaux. La notion de sauvegarde de session de travail (création de fichiers d'export/import de bi-textes au format xml et html) permet de commencer le travail sur un corpus à deux volets textuels, l'exporter au format désiré, puis le réimporter plus tard pour y apporter des modifications. La visualisation de l'alignement dans une représentation cartographique (bi-text map) offre plusieurs possibilités de gestion de corpus qui partagent des similitudes au plan traductionnel.
makeMetadata 2.00
Le programme makeMetadata permet de générer ou de corriger des métadonnées. Version exécutable pour Windows. HTML, Doc PDF
Activités / CV
mise à jour le 21 janvier 2018
Photo
M. Serge FLEURY