| Boite à outil n°1 | Boite à outil n°2 | Boite à outil n°3 | Boite à outil n°4 |
| HAMRI Nacer ( M1 TAL ) |
|
UNIERSITE
DE PARIS III NOUVELLE SORBENNE FILTRAGE ET ETIQUETAGE |
| Boite à outil Serie 1: |
| Dans cette partie il s'agit
de parcourir l'ensemble de l'arboressence
à la recherche des fichiers fils, puis extraire le contenu des
balises "DESCRIPTION" <description> CONTENU </description> et fourinir en resultat un fichier XML bien forme ou bien constitue à partir du fichier resultat de cette forme avec une feuille de style XSLT de cette forme Pour se faire on s'est servit des differents script fourini gracieusement par nos chers enseignants à savoir le script de parcours , en appliquant le script filteur Pour extraire le contenu des balises en question, et le script netoyeur , pour enlever les caracteres speciaux et les remplacer par les caracteres qu'il faut. tout Ca en apportant les modifications appropriées à ces scripts bien sure. A partir de ces données on a etablit le scripts de parcours, filtrage, et netoyage TPPERL.PL , on exécutant ce script on obtient en resultat ce fichier XML : SORTIE.XML met en forme avec la feuille de style suivante: STYLE.XSL |
| Boite à outil Serie 2: |
|
Dans cette deuxième partie il est demandé d'étiqueter le texte des balises description filttré d'abord avec l'étiqueteur TreeTagger, ensuite avec l'étiqueteur Cordial. ce texte que la boucle de taggage prend en entréé pour nous fournir en sortie un fichier etiqueté et lématisé: RESULTAT-TAGGAGE.TXT , un script perl transforme après cette sortie
texte en fichier XML structuré RESULTAT-TAGGAGE.xml
avec la feuille de style XSLT fournie dans la boite à
outil 2: SORTIE-ETIQUETAGE.XSL aprés on a effectué un autre etiquatage
sur le fichier TEXT.TXT
mais cette fois-ci avec l'étiqueteur Cordial; voici les
resultats: cordial.txt
|
| Boite à outil Serie 3: |
| se basant sur les résultats obtenus dans la
boite à outils 2; a savoir deux fichiers contenant le texte
étiqueté; le premier avec TREETAGGER, et le second avec
CORDIAL. on a effectue une operation de recherche et d'extraction
terminologique. pour realiser cette tache on a utilise un script
Trouve.pl qui prend en entrée un fichier issu de l'etiquetage
soit avec treetagger, ou avec cordial plus un fichier de patron; qui
spécifie les catégories qu'on veut extraire. 1. Sur la base des résultats de treetagger: donc comme on vient de le mentionner en haut; on a utilisé un script: trouve.pl qu'on a modifie en sorte qu'on obtienne une sortie Xml, a qui on appliquer une feuille de style Xsl pour visualiser les resultats. Script utilisé : trouve.pl Argument [0]: outtagger.txt Argument [1]: patron.txt Fichier trace: Trace.txt Resultats txt : resultat.txt Resultats.xml : résultatermino.xml Feuille de style: style.xsl 2. sur la base des résultats de Cordial: Script utilisé : trouve_cordial.pl Argument [0]: Cordial.cnr Argument [1]: patron Resultats.txt : résultatermino1.txt |
| Boite à outil Serie 4: |
| A l'issue du travail
effectué dans la Boîte à Outils Série 3 on est arrivé à extraire des suites de
tokens correspondant à des patrons morpho-syntaxiques
prédéfinis. Dans cette quatrième étape, on
doit construire des graphes donnant à voir ces patrons. la première étape consiste à transformer cette liste de patrons au format graphml. Pour cela on utilise le programme perl patron2graphml.pl, celui-ci prend en entrée une liste de patrons (argument 0 du programme) et il construit en sortie un fichier au format graphml. le fichier obtenu ressemblera à ça: patron-graphml.xml sur lequel on applique la feuille de style suivante : ::::: GraphML2Pajek.xsl la dernière étape consiste à charger le résultat dans Pajek pour obtenir le graphe. 1.sur la base des résultats de treetagger: Le programme patron2graphml.pl prend en entree le resultat d'extraction terminologique: resultpatron.txt on obtient après exécution du programme le fichier xml suivant: graphml.xml fichier Xml sur lequel on applique la feuille de style fourni en cours: graphpajek.xsl par la suite on a charge le fichier Xml sur COOCTOP en appliquant sur la feuille de style en question; et on a eu en résultat un fichier qu'on a enregistré sous forme (.net) : pajek.net et on a obtenu le graphe suivant ( a base des résultat ontebus sur Treetagger): 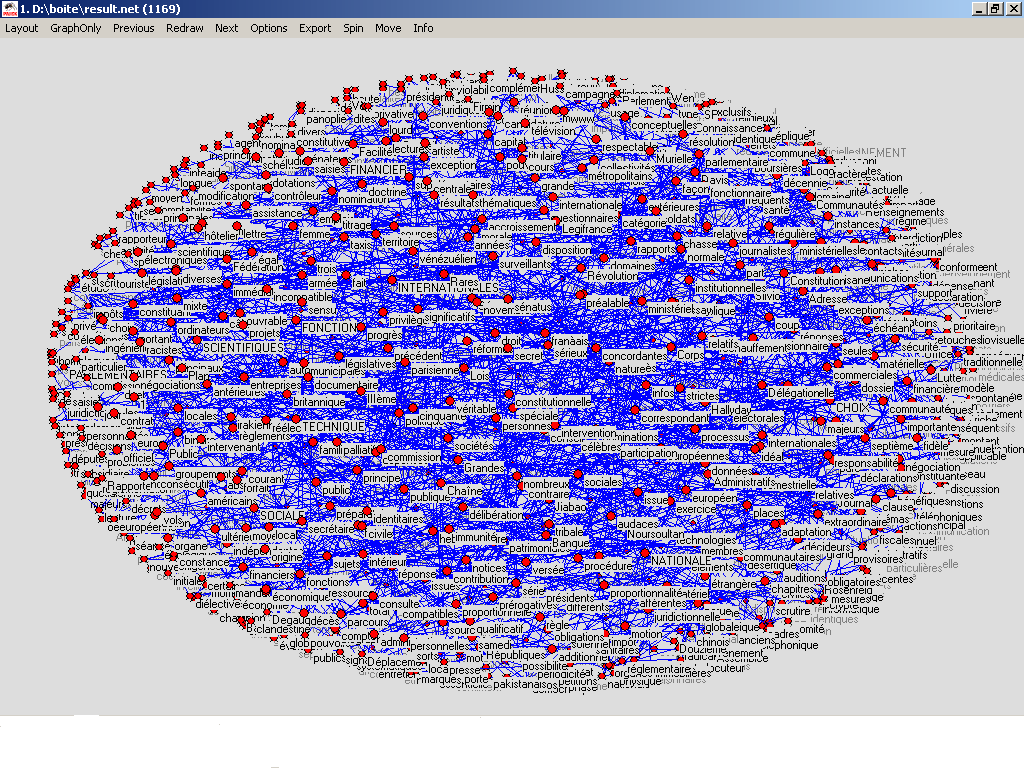 1.sur la base des résultats de cordial: Fichier contenant le resultat d'extraction terminologique sur les données de cordial: resultpatroncordial.txt on obtient après exécution du programme le fichier xml suivant: graphmlcordial.xml fichier Xml sur lequel on applique la feuille de style fourni en cours: graphpajek.xsl par la suite on a charge le fichier Xml sur COOCTOP en appliquant sur la feuille de style en question; et on a eu en résultat un fichier qu'on a enregistré sous forme (.net) : pajek1.net et on a obtenu le graphe suivant ( a base des résultat ontebus sur Treetagger): 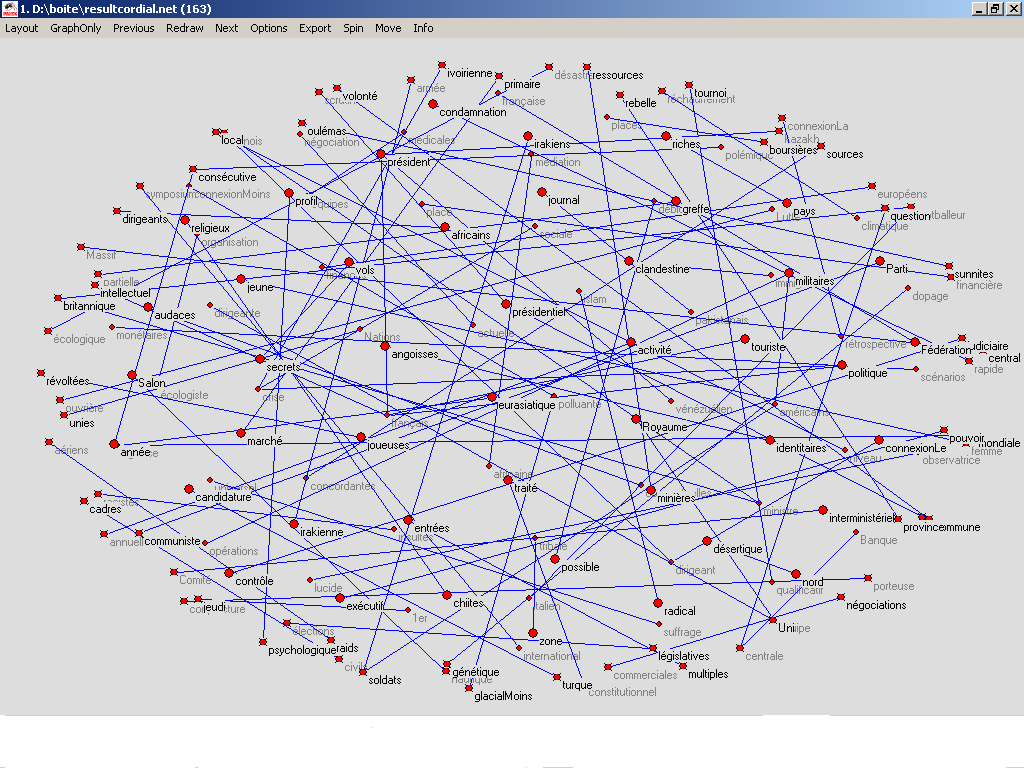 |