|
Aspect informatique
|
|
|
Retour à Page d'acceil |
Réalistion du programme:
Avant de programmer j’ai écrit l'algorithme au
format word.
Les étapes importantes sont:
* Aspiration des pages avec wget
*** La recherche des lignes avec egrep
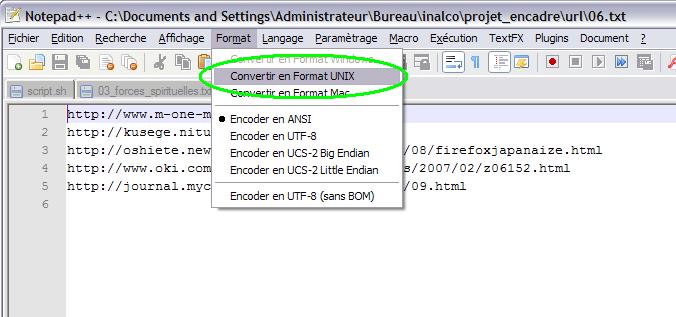
**** La réalisation du tableau en html.Remarque: Les fichiers textes enregistrés au format Windows ne marcheront pas sous l'environnement Unix,
(voir le cours de J.F Perrot). En effet, Les retours à la ligne des fichiers textes (tapés sous Windows XP)
sont interprétés différemment par Cygwin (qui émule un système UNIX).
Notepad++, en particulier, permet de régler ce problème(fiche créée Par Pierre.M):
Le script que j'ai fait:
| #!/bin/bash echo "Bonjour, indiquez ou se trouvent les fichiers URL?" read rep echo "Comment tu veux appeler ton fichier tableau?" read fichierTAB echo "donne le motif a chercher :" read motif echo "voici le motif :" $motif echo "<html><head><title>Sens et traduction du mot procedure</title><body><table border="1" cellspacing="0" cellpadding="0" width="100%"> " > ../tableau/$fichierTAB.html i=1 for dos in `ls ../$rep/` { for fichier in `ls ../$rep/$dos` { echo "<table border=1>" >> ../tableau/$fichierTAB.html echo "<tr><td colspan=\"3\"><b>Fichier $fichier</b></td></tr>" >> ../tableau/$fichierTAB.html for nom in `cat ../$rep/$dos/$fichier` { wget -O ../pagesAspirees/$i.html $nom lynx -dump $nom > ../PAGES_DUMP/$i.txt egrep -i "\b$motif\b" ../PAGES_DUMP/$i.txt > ../PAGES_CONTEXTES/$i.txt echo "<tr><td><a href=\"$nom\">URL_lien $i</a></td><td><a href=\"../pagesAspirees/$i.html\">PagesAspirees $i</a></td><td><a href=\"../PAGES_DUMP/$i.txt\">PAGES_DUMP</a></td><td><a href=\"../PAGES_CONTEXTES/$i.txt\">PAGES_CONTEXTE</a></td></tr>" >> ../tableau/$fichierTAB.html; let "i+=1"; } echo "</table>" >> ../tableau/$fichierTAB.html echo "<br>" >> ../tableau/$fichierTAB.html } } echo "</body></html>" >> ../tableau/$fichierTAB.html |