
Représentation et classification évolutives de mots pour le TALN avec la programmation à prototypes
Serge Fleury
UMR 9952
Ecole Normale Supérieure de Fontenay-St Cloud
31 avenue Lombart
F-92260 Fontenay aux Roses
e-mail : fleury@ens-fcl.fr, http://www.ens-fcl.fr/~fleury
Résumé.
Cet article présente la mise en uvre d'un dispositif expérimental qui porte le nom de GASPAR [Fleury, 1997]. Ce dispositif vise à établir une représentation et un classement évolutifs d'unités lexicales représentées sous la forme d'objets informatiques appelés des prototypes. Les processus de représentation s'appuient sur des savoirs extraits d'un corpus. Nous montrons comment la programmation à prototypes permet de représenter des unités lexicales dynamiquement par apprentissage et par affinements successifs. Elle permet ensuite d'amorcer un début de classement des mots sur la base des contraintes syntaxiques attachées à ces mots en construisant des hiérarchies locales de comportements partagés.
Abstract.
This paper present a NLP system called GASPAR [Fleury, 1997]. This system's aim is first to build evolutive representation for words with objects called prototypes, second to classify these objects according to the linguistic information associated to these objects. This process of representation use data extracted from large corpora. We present the prototype-based paradigm and its applications for the representation and for the classification of lexicals items represented as prototypes. We present process of representation which build words as objects and associate to these objects the syntactic and semantic behaviors of the concerning words. We describe how we can use a prototype-based language to generate automatically objects, defined step by step, for representing lexicals items, and how a prototype-based language allows to classify these objects according to the associated constraints.
1 Introduction
Notre travail vise à la mise au point d'outils de modélisation adaptés à des problèmes fondamentaux de représentation des connaissances dans un dispositif de TALN. L'hypothèse suivie dans ce travail est que ces connaissances ne sont pratiquement jamais complètes et intangibles. Au contraire, il faut gérer leur extension et leur modification. Cet article présente la mise en uvre d'un dispositif expérimental qui porte le nom de GASPAR [Fleury, 1997]. Ce dispositif a pour but de construire des représentations évolutives pour les mots à partir d'informations extraites sur corpus. Il doit aussi conduire à la construction de classes de mots de manière inductive. Les classes de mots produites sont ensuite utilisées pour affiner le travail de représentation des mots. Notre démarche cherche à réaliser une adéquation entre les occurrences linguistiques réalisées et les prédictions de représentations construites. Il ne s'agit pas de produire d'emblée un résultat définitif mais plutôt de tendre vers cette adéquation, par touches successives, en affinant les prédictions construites.
2 Examen de mots en corpus
Notre approche de représentation vise à repérer des informations à partir de réalisations rencontrées sur corpus. Le corpus utilisé est celui qui est constitué dans le cadre du projet MENELAS [Zweigenbaum, 1994] pour la compréhension de textes médicaux. Ce corpus est utilisé par le Groupe de Travail Terminologique et Intelligence Artificielle (PRC-GDR Intelligence Artificielle, CNRS). L'unité thématique de ce corpus a trait aux maladies coronariennes. On utilise donc le corpus MENELAS à partir duquel une chaîne de traitements automatiques extrait des informations. Les informations extraites sont des arbres d'analyse fournis par des analyseurs robustes, ces arbres étant ensuite simplifiés dans le but de déterminer les arbres élémentaires qu'il est possible d'associer aux mots.
3 Un outil pour la représentation et le classement automatiques de mots
L'outil de représentation choisi est la programmation à prototypes [Blascheck, 1994] (désormais notée PàP). Avec la PàP, il ne s'agit pas de partir d'une somme d'informations figées et connues par avance mais de construire progressivement les entités informatiques suivant les informations dont on dispose. Si les informations à représenter ne sont pas connues de manière définitive, il est possible de commencer le processus de représentation en utilisant les informations déjà recensées puis d'affiner dynamiquement les objets construits dès que de nouvelles informations sont disponibles. On peut donc envisager des processus de représentation qui se déroulent de manière continue suivant les flux d'informations disponibles. Self est le langage utilisé pour l'implémentation du système GASPAR. Self est un langage à prototypes qui permet l'héritage multiple et dynamique [Ungar et Smith, 1987]. Les propriétés fondamentales du langage Self et de son interface graphique sont la concrétude, l'uniformité et la flexibilité. La concrétude se manifeste clairement par le fait qu'un utilisateur manipule directement les objets et peut en créer de nouveaux à partir d'objets existants en les dupliquant (via l'opération de clonage) et en les ajustant. L'uniformité se traduit par le fait qu'en Self tout est objet et que tous les objets dialoguent entre eux par envoi de messages. La flexibilité découle directement des aspects de concrétude et d'uniformité de Self. L'héritage en Self se réalise au travers de la notion de délégation qui permet de factoriser localement des comportements partagés. Dans le langage Self, un parent commun à plusieurs prototypes est appelé un objet
traits.4 Acquisition de savoirs en corpus
Les informations utilisées par les processus de représentation informatique des mots et des arbres associés sont issues d'une chaîne de traitements composée des logiciels LEXTER et ZELLIG. LEXTER [Bourigault, 1993] est un outil d'acquisition terminologique conçu et réalisé dans un environnement industriel : la Direction des Etudes et Recherches de EDF, pour aider à la mise au point de terminologie. ZELLIG [Habert et Nazarenko, 1996] est un outil d'acquisition de classes sémantiques et conceptuelles fondé sur l'hypothèse harrissienne selon laquelle il est possible d'induire des catégories propres à un corpus à partir des régularités syntaxiques des contextes dans lesquels figurent les mots de ce corpus [Harris et al., 1989]. Le but de ces outils est d'une part d'extraire des informations à partir de corpus (LEXTER) et d'autre part de simplifier ces informations puis de caractériser leurs fonctionnements (ZELLIG). LEXTER prend en entrée des textes arbitrairement longs et produit des arbres d'analyse de séquences nominales en décomposant ces séquences en Tête et Expansion et ce de manière récursive. Le logiciel ZELLIG a ensuite pour tâche de simplifier les arbres d'analyse fournis ici par LEXTER et de mettre en évidence les dépendances élémentaires entre mots pleins, nom ou adjectif, dans des schémas comme, par exemple,
N Prep N ou N Adj. Les arbres issus de LEXTER sont d'abord transformés en arbres syntagmatiques via le transducteur FRT (un module de ZELLIG) [Habert et Bourigault, 1997]. Le programme CYCLADE (un autre module de ZELLIG) est ensuite chargé de déterminer les arbres élémentaires. Par exemple, si on considère la séquence "alteration severe de la fonction ventriculaire gauche", LEXTER va d'abord produire l'analyse : [T [T alteration] [E severe] [E de la [T [T fonction] [E ventriculaire] [E gauche]], ZELLIG transforme ensuite cet arbre en un arbre syntagmatique puis détermine les arbres élémentaires : (a) alteration severe, (b) alteration de fonction, (c) fonction gauche, (d) fonction ventriculaire.5 Construction inductive des savoirs avec GASPAR
GASPAR dispose, au départ, d'informations extraites à partir d'un corpus (sous la forme d'un fichier texte). À chaque mot sont associées les informations suivantes : (1) une description sous-déterminée du mot ; (2) une suite de contextes : un arbre élémentaire ou une suite d'arbres élémentaires auxquels est associée éventuellement une suite d'arbres d'analyse.
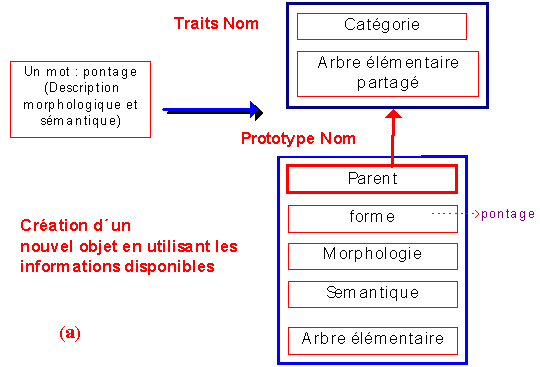
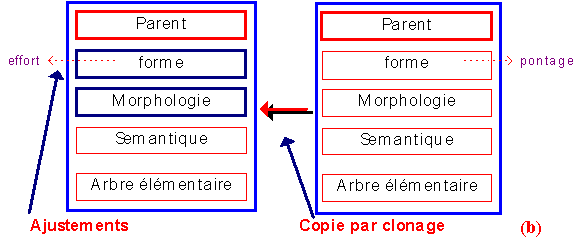
Figure 1. Génération automatique des prototypes de mot " pontage "(a) et " effort "(b).
Pour chaque description de mot, GASPAR vérifie s'il existe un prototype équivalent. S'il existe, GASPAR conserve l'objet trouvé. S'il n'existe pas (figure 1a), et s'il n'existe aucune représentation prototypique de la même famille catégorielle, GASPAR commence par créer automatiquement une représentation prototypique de cette nouvelle famille catégorielle (l'objet
traits), puis il construit un prototype (en tenant compte des informations fournies) pour représenter ce nouveau mot. Si le mot à représenter ne possède pas de représentation prototypique et s'il existe déjà un prototype reprÈsentant un élément de la même famille catégorielle (figure 1b), GASPAR utilise les opérations de clonage et d'ajustement pour représenter ce nouvel élément. GASPAR procède de la même manière pour la représentation des arbres. GASPAR vérifie si ces arbres disposent déjà d'une représentation prototypique. Si elle n'existe pas, il la créé automatiquement en tenant compte des informations fournies : constituants et contraintes (les contraintes associées à un arbre décrivent par exemple des informations qui filtrent ou sélectionnent les constituants possibles pour cet arbre). Dans la figure qui suit, le dispositif GASPAR construit les structures pour représenter les arbres associés à pontage en tenant compte des informations données pour la description de ces arbres.
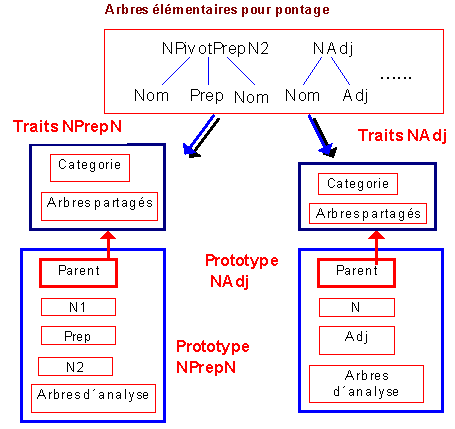
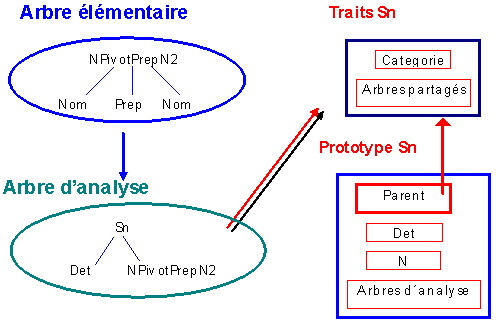
Figure 2. Génération automatique des prototypes d´arbres associés au mot " pontage ".
GASPAR affecte ensuite les prototypes d'arbres aux prototypes de mots auxquels ils sont associés. De même, il associe les prototypes d'arbres d'analyse construits aux prototypes d'arbres élémentaires associés.
6 Classement des prototypes
Les processus de classement ajoutent de manière dynamique des liens de délégation entre les prototypes de mots ou d'arbres et des pôles de comportements partagés construits automatiquement. GASPAR peut tout d'abord rechercher sur tous les mots d'une même catégorie s'il existe des arbres élémentaires en commun. Si tous ces prototypes de mots partagent exactement les mêmes comportements (les mêmes prototypes d'arbres élémentaires), l'objet
traits qui porte les comportements partagés de cette catégorie est mis à jour : il portera ces comportements communs. Dans tous les cas, les prototypes de mots portent, quant à eux, leurs comportements propres. GASPAR peut ensuite rechercher sur les prototypes pris deux à deux s'ils partagent des arbres élémentaires. Si deux prototypes de mots partagent un ou plusieurs comportements (un ou plusieurs prototypes d'arbres élémentaires), un objet traits est automatiquement construit pour porter ces comportements partagés. Dans ce cas, GASPAR ajoute automatiquement aux prototypes concernés un attribut parent qui pointe sur ce nouvel objet porteur de comportements partagés. GASPAR peut aussi évaluer les comportements partagés sur des sous-familles de prototypes de mots de même catégorie. Si plusieurs prototypes de mots partagent exactement les mêmes comportements (les mêmes prototypes d'arbres élémentaires), un objet traits est automatiquement construit pour porter ces comportements partagés. Dans ce cas, GASPAR ajoute automatiquement aux prototypes concernés un attribut parent qui pointe sur ce nouvel objet porteur de comportements partagés. GASPAR permet aussi d'établir une recherche des comportements partagés (arbres d'analyse) par les arbres élémentaires de même catégorie. Ce classement utilise une démarche similaire à celle qui est utilisée pour classer les mots. Si plusieurs prototypes d'arbres élémentaires partagent exactement les mêmes comportements (les mêmes prototypes d'arbres d'analyse), un objet traits est automatiquement construit pour porter ces comportements partagés. Là encore, GASPAR ajoute automatiquement aux prototypes concernés un attribut parent qui pointe sur ce nouvel objet porteur de comportements partagés.7 Une démarche de représentation contrôlée et en spirale
Pour chaque mot, GASPAR est donc amené à construire : (1) un prototype de mot (ce prototype porte une représentation morphologique et sémantique sous-déterminée du mot visé) ; (2) une suite de prototypes d'arbres élémentaires ; (3) à chaque prototype d'arbre élémentaire est associée éventuellement une suite de prototypes d'arbres d'analyse. GASPAR construit aussi les liens qui existent entre chacun des objets construits. GASPAR utilise des informations issues d'un travail d'extraction à partir de corpus pour réaliser la représentation de mots sous la forme de prototypes. Ces informations peuvent être connues avant la phase de génération automatique des objets ou peuvent être utilisées dès qu'elles sont disponibles pour affiner la représentation des objets construits.
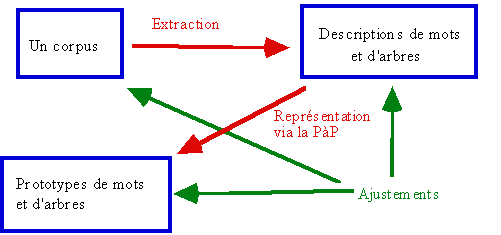
Figure 3. Construction progressive de prototypes.
Pour chaque mot, GASPAR construit un mini-réseau de prototypes décrivant la micro-syntaxe associée à ce mot. La représentation des mots reste bien évidemment sous-déterminée. C'est l'examen des contextes (les arbres associés) qui doit permettre de tracer des pistes de sens. Si de nouvelles informations sont disponibles, on peut ensuite affiner la représentation syntaxico-sémantique des mots et des arbres en utilisant le potentiel dynamique de Self.
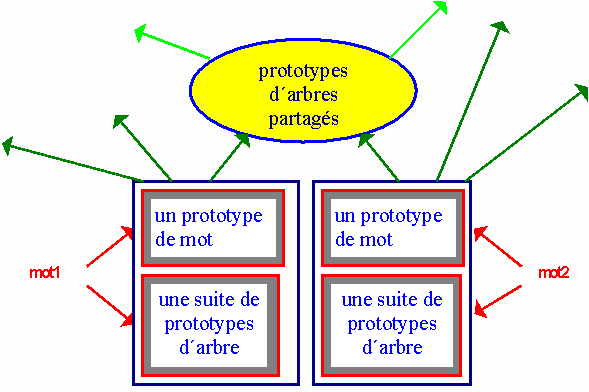
Figure 4. Classement progressif des prototypes.
GASPAR active ensuite des processus de classement qui proposent des regards multiples et croisés sur les savoirs représentés (figure 4). Ces processus construisent des réseaux de hiérarchies locales entre prototypes de mots et prototypes d'arbres ou entre prototypes d'arbres, ces liens multiples constituent autant de pistes de sens à interpréter. Le classement opéré s'appuie essentiellement sur des contraintes syntaxiques. Or la syntaxe ne permet pas à elle seule de délimiter des classes de noms reflétant une notion. Si GASPAR peut automatiser le classement des prototypes de mots sur la base des arbres qui leurs sont associés, les résultats restent à qualifier, à nommer. Dans notre dispositif, c'est l'observateur conscient qui donne le sens. C'est en examinant à la main les rapprochements constatés et les classes de mot construites que l'on pourra leur donner un nom c'est-à-dire nommer les choses. Ce travail d'interprétation est d'ailleurs un passage obligé de toutes les approches en classification automatique, en analyse de données par exemple, mais aussi dans des traitements syntaxiques à la Grefenstette (1994).
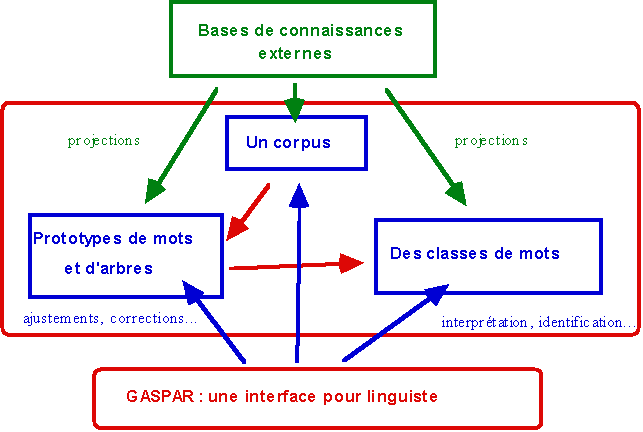
Figure 5. Une interface pour linguiste.
Notre travail de représentation est conçu comme un mécanisme évolutif guidé par le travail interprétatif du linguiste. Notre démarche de représentation passe d´ailleurs par la mise en uvre d´une interface graphique qui permette à l'utilisateur d'évaluer et d'interpréter les résultats. Ce développement constitue une voie de travail de grande ampleur qui ne peut être développé ici. Self offre d'ailleurs des solutions intéressantes pour réaliser cette interface. Dans un premier temps nous avons utilisé le potentiel de Self pour mettre en place des interfaces graphiques pour accéder aux objets disponibles dans le dispositif GASPAR. Nous avons ensuite adapté le browser disponible dans Self-4.0 afin de créer un point d´entrée pour la présentation de GASPAR et de ses composants. Ce browser permet aussi de rendre accessible les données traitées par GASPAR au gré de leurs évolutions. Il permet enfin une présentation des résultats construits par GASPAR. Ces résultats sont mis à jour automatiquement par les programmes développés dans ce dispositif. Les classes de mots construites sur les corpus traités constituent à ce jour les premiers résultats disponibles via cette interface. Toutes les informations manipulées ou produites par GASPAR sont disponibles sur le WEB à l´adresse suivante :
http ://www.ens-fcl.fr/~fleury/gaspar.html.8 GASPAR : un dispositif expérimental
Les résultats produits par GASPAR sont en fait limités actuellement par les contraintes matérielles imposées par ce langage expérimental sur les machines que nous utilisons. Il faut en effet beaucoup de mémoire et d'espace disque sur les machines qui portent le système Self pour mettre en uvre cette représentation de la mouvance. La mise en uvre de ce dispositif peut être considérée comme une expérience pilote qui offre une image partielle, pour le moment, des traitements réalisés et des résultats à venir. La génération automatique des prototypes est largement conditionnée par la somme d'informations issue du travail d'extraction réalisé en amont. Les informations utilisées, à ce stade de notre travail, sont nettement insuffisantes pour produire des résultats significatifs. Le classement opéré prend appui sur des caractéristiques grossières à la fois en raison de contraintes matérielles et de la difficulté à récupérer et organiser les informations à représenter. Pour le travail réalisé sur les gros corpus nous avons restreint le nombre de contraintes syntaxiques associées aux mots. Nous avons travaillé uniquement sur des séquences
NAdj extraites via LEXTER. À partir de 8754 séquences comportant des groupes nominaux, nous avons extraits 586 mots (des noms) auxquels sont attachés 1413 arbres élémentaires de type : Sn1 -> Nom Adj, Sn2 -> Adj Nom, Sn3 -> Adj XX, Sn4 -> XX Adj. Cette première sélection a donc consisté à ne garder que les arbres binaires portant les feuilles Nom/XX et Adj. Le processus de génération conduit à la création des prototypes pour représenter les catégories syntaxiques Nom, Adj, XX, Sn1, Sn2, Sn3, Sn4, des objets traits associés et de plus de 2000 prototypes par copie et ajustement. GASPAR a ensuite cherché à repérer les prototypes de mots qui partageaient exactement les mêmes comportements. Ce processus de classement conduit à la création automatique de 54 pôles de comportements partagés. On présente ci-dessous quelques classes de mots obtenues.
|
Pôles de mots partageant un arbre SN -> Nom Adj |
Adj |
|
(1) occipital bras aisselle epaule |
gauche |
|
(2) exces surcharge |
ponderal |
|
(3) octobre juillet juin mai mars avril |
dernier |
|
(4) besoin tableau |
clinique |
|
(5) staff discussion reunion exerese geste reparation resection revascularisation |
medico-chirurgical |
|
(6) equipe solution oedeme parenchyme plage coeur tuberculose vascularisation |
chirurgical |
|
(7) sommet base |
pulmonaire |
|
(8) bloc sillon |
auriculo-ventriculaire |
|
(9) expression positivite seringue |
electrique |
|
(10) oreillette ventricule retard |
droit, gauche |
|
Pôles de mots partageant un arbre SN -> Adj Nom |
Adj |
|
(17) majorite variabilite |
grand |
|
(28) ballon extension |
petit |
Les classes produites sont, dans l'ensemble, cohérentes mais ne produisent pas encore des résultats pertinents sur le domaine étudié : certaines classes évidentes ou prévisibles sont mises au jour. La classe de mot associée au pôle n°3 est homogène dans sa relation avec l'adjectif
dernier, de même pour la classe n°2 dans sa relation avec l'adjectif ponderal. La classe n°1, où la relation de localisation qualifie un membre ou une région du corps, est elle aussi cohérente ; pour cette classe, on note que les noms qualifiés ne le sont que pour l'adjectif localisant gauche ; à la différence de la classe n°10, celle-ci étant moins homogène. Les classes n°5, 6, 9 regroupent quant à elles des noms sémantiquement plus éloignés. L'examen de la simple relation binaire Nom Adj ne permet pas de décrire complètement le fonctionnement des mots. Pour le moment, à chaque prototype est associée une liste de prototype(s) d'arbre élémentaire ; chacun de ces prototypes décrivant une relation Nom Adj. Pour enrichir ce travail de description du comportement des mots, il convient évidemment de pouvoir examiner d'autres types de relation binaire puis les relations syntaxiques complexes (lien arbre élémentaire / arbre d'analyse). Il convient aussi d'examiner en détail tous les types possibles de regroupements de mots : certains mots partagent individuellement plus de comportements avec d'autres mots.9 Perspectives
Notre travail a porté, dans l'immédiat, sur la mise en uvre de processus automatiques pour la représentation et le classement de mots sous la forme de prototypes. Sur le plan technique, la couverture des gros corpus doit être réalisée. Ce travail doit nous permettre d'améliorer la qualité du travail de représentation initié par les processus construits. La confrontation de ces résultats avec les connaissances du linguiste ou avec des bases de connaissances extérieures est prometteuse. Les aspects conceptuels n'ont pas été articulés aux phénomènes traités dans les processus construits ; une étude théorique et technique de ces articulations avec les autres niveaux de savoirs représentés doit conduire à étendre et affiner le travail de représentation amorcé. Le traitement de connaissances extra-linguistiques peut aussi compléter et affiner les processus mis en place.
Références
(Blascheck 1994]
Blascheck, G., (1994). Object-Oriented Programming with Prototypes, Springer-Verlag, Berlin.
[Bourigault, 1993]
Bourigault, D., (1993). " An endogeneous Corpus-Based Method for Structural Noun Phrase Disambiguation ". Dans Actes EACL.
[Fleury, 1997]
Fleury, S., (1997). La programmation à prototypes, un outil pour une linguistique expérimentale. Mise en uvre de représentations évolutives des connaissances pour le traitement automatique du langage naturel. Thèse de doctorat, Paris 7-Denis Diderot.
[Grefenstette, 1994]
Grefenstette, G., (1994). " Corpus-Derived First, Second and Third-Order Word Affinities ". Dans Actes EURALEX, Amsterdam.
[Habert et Nazarenko, 1996]
Habert, B., Nazarenko, A., (1996). " La syntaxe comme marche-pied de l'acquisition de connaissances : bilan critique d'une expérience ". Dans Actes Journées d'Acquisition de Connaissances.
[Habert et Bourigault, 1997]
Habert, B., Bourigault, D., (1997). " A Frontier to Root Transducer for the Evaluation of Two Noun Phrase Extractors ". Dans Actes Journées Scientifiques et Techniques, FRANCIL, Avignon.
[Harris et al. 1989]
Harris, Z., Gottfried, M., Ryckman, T., Mattick, P., Daladier, A., Harris, T.N., Harris, S. (1989). The form of Information in Science. Analysis of Immunology Sublanguag. Dordrecht : Kluwer Adademic Publishers.
[Ungar et Smith, 1987]
Ungar, D., Smith, R-B., (1987). " SELF : The power of Simplicity ". Dans Actes OOPSLA, SIGPLAN Notices.
[Zweigenbaum, 1994]
Zweigenbaum, P., (1994). " MENELAS : an Access System for Medical Records using Natural Language ". Dans Computer Methods and Programs in Biomedicine, volume 45, pages 117-120.