
Chapitre 8
"C'est ainsi que j'ai pu apprendre que ses navets au jus sont moins bons qu'autrefois mais qu'en revanche ses carottes, au jus egalement, sont meilleures que dans le temps. Le jus n'a pas changé. C'est là un langage que je comprends presque, ce sont là des idées claires et simples sur lesquelles il m'est possible de bâtir, je ne demande pas d'autre nourriture intellectuelle."
"L'innommable", Samuel Beckett, Ed. de Minuit.
Représentation et classification dynamiques
Ce chapitre donne une présentation du dispositif mis en place pour la génération automatique des prototypes de mots et des prototypes d'arbres associés et pour leurs classements.
Gaspar est le nom générique du dispositif chargé de construire les représentations des mots puis leur classement. L'implémentation s'inscrit dans le cadre défini par la version 4.0 du langage à prototypes Self (-> incise 3) : on dispose ainsi d'une interface graphique pour tracer, évaluer, modifier les résultats construits . Cette implémentation étend donc les outils d'analyse déjà présentés.8.1. Un dispositif pour la représentation et pour le classement des mots et de leurs comportements
8.1.1. Un dispositif pour l'expérimentation linguistique
Les informations associées aux mots donnent une description des mots à représenter aussi bien dans leur forme que dans les interrelations que ces mots tissent avec d'autres unités de langue, et en particulier les liens qui existent entre ces mots et des structures syntaxiques associées. On donne ci-dessous une présentation du schéma général des opérations mises en place.

Figure 8.1 : Représentation des mots et "représentactions" sur les mots
Les modifications que peuvent subir les unités lexicales dans certains contextes (glissement de sens, changement de type...) ou réciproquement, les modifications que peuvent déclencher ces mêmes unités lexicales sur d'autres unités dans un contexte donné ne sont pas formalisées de manière précise : il reste possible d'ajuster manuellement les représentations construites pour tenir compte de tels phénomènes (-> incise 1 : présentation de Self 4.0, -> affinements des représentations). De même, la détermination des processus généraux qui agissent sur le corpus donné ne sera pas traitée à ce stade de notre travail. Nous nous intéressons en premier lieu à la représentation du savoir qu'il est possible d'attacher aux unités lexicales. Nous verrons infra que le dispositif construit donne à l'utilisateur la possibilité d'intervenir directement sur les entités construites ou manipulées par le dispositif : il reste donc possible à tout moment d'ajuster la représentation des unités de langue. Le dispositif construit vise en effet à donner à l'utilisateur un rôle actif dans la manipulation des structures définies et dans l'interprétation des résultats à construire. Les résultats construits constituent des amorces d'interprétation qu'il convient d'ajuster. Ce dispositif est avant tout conçu comme un outil d'expérimentation avec lequel il est possible à tout moment d'affiner les représentations définies. Le langage Self et les différentes interfaces mises en place permettent à tout moment d'interroger et de modifier les objets construits (-> annexe partie 2 chapitres 8 et 9 : présentations des traces générées par Gaspar). Si l'examen des représentations construites ou des pôles de comportements partagés calculés révèlent des failles, des manques, des lacunes... l'utilisateur de ce dispositif peut ajuster les informations représentées par touches successives et de manière dynamique.
8.1.2. Description des informations à représenter
Pour commencer nous reprenons l'exemple traité dans le chapitre précédent. On donne ci-dessous une présentation des informations que le travail d'extraction de savoirs sur corpus génère :
#Dc
pontage
Nom
#DM (Description morphologique)
Masc
Sing
...
#FM
#DS(Description sémantique)
....
#FS
#DAE
N1PrepNPivot
('Nom' 'Prep' 'NomPivot')
->DCAE (Contraintes sur arbre élémentaire)
<-FCAE
#DAL
≠Sn
('Det' 'N1PrepNPivot')
->DCAL
(Contraintes sur arbre lié)
<-FCAL
#FAL
#DAL
Ø
NomPivotNAdj
('NomPivot' 'Adj')
->DCAL
(Contraintes sur arbre lié)
<-FCAL
#FAL
#DAL
*N1PrepNPivot
('Adj' 'N1PrepNPivot')
->DCAL
(Contraintes sur arbre lié)
<-FCAL
#FAL
#FAE
#DAE
NAdj
('Nom' & 'Adj')
->DCAE
(Contraintes sur arbre élémentaire)
<-FCAE
#DAL
≠
Sn('Det' 'NAdj')
->DCAL
(Contraintes sur arbre lié)
<-FCAL
#FAL
#DAL
Ø
AdjSAdj
('Adj' 'AdjPivot')
->DCAL
(Contraintes sur arbre lié)
<-FCAL
#FAL
#FAE
#DAE
....
#FAE
Fc#
On peut lire ce qui précède de la manière suivante :
le mot
il est possible d'adjoindre dans l'arbre élémentaire de type
N1PrepNPivot un arbre de type NAdj au niveau du composant NomPivot;
de même, le mot
pontage peut entrer dans un arbre élémentaire NAdj qui lui-même peut générer un arbre d'analyse de type Sn;
il est possible d'adjoindre dans l'arbre élémentaire de type
NAdj un arbre de type SAdj au niveau du composant Adj;

Figure 8.2 :
pontage et arbres associés
ce qui peut aussi s'écrire :
Arbre Elémentaire :
pontage => N1PrepNPivot -> Nom Prep NomPivot
Arbre d'analyse montant :
N1PrepNPivot => Sn -> Det N1PrepNPivot
Arbre auxiliaire :
N1PrepNPivot => *N1PrepNPivot -> Adj N1PrepNPivot
Arbre d'analyse par adjonction : (dans N1PrepNPivot sur NomPivot)
NomPivot => NAdj -> NomPivot Adj
Arbre Elémentaire :
pontage => NAdj -> Nom Adj
Arbre d'analyse montant :
NAdj => Sn -> Det NAdj
Arbre d'analyse par adjonction : (dans NAdj sur Adj)
Adj => SAdj -> Adj AdjPivot
A partir de ces informations, le dispositif peut générer à la volée les arbres élémentaires associés aux mots et les arbres liés aux arbres élémentaires. Il établit ensuite les liens qui existent entre les objets créés.
De manière plus générale, la phase d'extraction de savoirs sur corpus produit un fichier texte qui a l'allure suivante :
#Dc
entrée lexicale
Catégorie
#DM
(Description morphologique)
#FM
#DS
(Description sémantique)
#FS
#DAE
(Arbre élémentaire associé à cette entrée lexicale)
->DCAE
(Contrainte sur arbre élémentaire)
->FCAE
#DAL
(Arbre d'analyse associé à cet arbre élémentaire)
->DCAL
(Contrainte sur arbre d'analyse)
->FCAL
#FAL
#FAE
#DAE
....
#FAE
Fc#

Figure 8.3 : Description des informations associées à
pontage
A chaque entrée lexicale
#Dc-#Fc, on associe les informations suivantes :
une description morphologique de l'entrée lexicale
une description sémantique de l'entrée lexicale
#Ds-#Fs,
une liste d'arbres élémentaires associés à l'entrée lexicale
{#DAE-#FAE}. On peut aussi associer à chaque arbre élémentaire une liste de contraintes {#DCAE-#FCAE} et une liste d'arbres d'analyses {#DAL-#FAL}.
La phase de génération est conçue comme un processus évolutif. Si ces informations ne sont pas disponibles à une certaine phase de la représentation, rien n'empêchera d'affiner les représentations construites dès que ces informations seront établies ou disponibles. La détermination de celles-ci pourra se faire par projections des savoirs construits sur des savoirs définis par ailleurs ou en affinant la phase d'extraction de savoirs sur corpus avec là aussi projection sur des classes de savoirs qui précisent ce type d'informations. Il s'agit en fait de définir un format des informations que l'on peut recevoir pour la génération des prototypes associés aux mots : si les informations sont présentes, on pourra les représenter; si elles ne le sont pas, on attendra d'en disposer pour les représenter.
8.1.3. Mise en forme des connaissances
Phase 0 : Génération de prototypes pour "porter" les savoirs attachés à une entrée lexicale.
Un programme (écrit en C) est chargé de traiter le fichier précédent afin de le formater pour être lisible dans un environnement Self. Celui-ci crée une série de prototypes qui vont porter les informations lues. Pour chaque entrée lexicale, on construit un prototype qui a l'allure suivante :

Figure 8.4 : Description des informations en entrée
Chacun des objets ainsi créé est enregistré dans un dictionnaire.
8.1.4. Une construction inductive des savoirs
8.1.4.1. Génération dynamique des prototypes lexicaux et des prototypes d'arbres
On reprend dans le schéma qui suit les différentes étapes du traitement mis en place pour la génération des mots et et arbres sous la forme de prototypes.
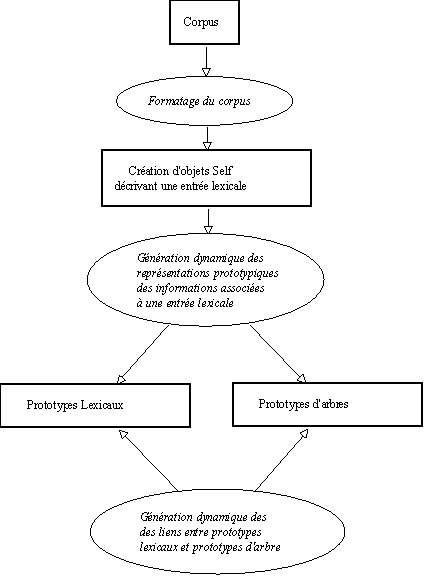
Figure 8.5 : Déroulement de la génération
A partir des objets précédents associés aux entrées lexicales, on construit les représentations prototypiques des informations contenues dans ces objets.
Phase 1 : Génération du prototype lexical en utilisant les informations décrivant la morphologie et la semantique du mot.
La génération d'un prototype lexical est réalisée de la manière suivante :
Si le mot à représenter possède une représentation prototypique, on conserve l'objet trouvé.
Si le mot à représenter ne possède pas de représentation prototypique et s'il existe déjà une représentation prototypique d'un élément de la même famille catégorielle, on utilise les opérations de clonage et d'ajustement pour représenter ce nouvel élément (en tenant compte des informations fournies pour décrire ce nouvel élément).
Si le mot à représenter ne possède pas de représentation prototypique, et s'il n'existe aucune représentation prototypique de sa famille catégorielle, on commence par créer de toutes pièces une représentation prototypique de cette nouvelle famille catégorielle, puis on construit une représentation prototypique de ce nouveau représentant de cette famille (en tenant compte des informations fournies pour décrire ce nouvel élément).
Phase 2 : Génération des prototypes d'arbres élémentaires associés à chacun des mots.
Tous les arbres élémentaires créés sont enregistrés dans un dictionnaire. Et on utilise ce dictionnaire comme base de référence pour les arbres élémentaires disponibles. Si on a besoin d'un arbre non référencé dans ce dictionnaire, on le créé avec les outils adéquats.
Si l'arbre élémentaire à représenter possède une représentation prototypique, on conserve l'objet trouvé.
Si l'arbre élémentaire à représenter ne possède pas de représentation prototypique et s'il existe déjà une représentation prototypique d'un élément de la même famille catégorielle (avec le même type de composants), on utilise les opérations de clonage et d'ajustement pour représenter ce nouvel élément (par exemple, ajustements des contraintes sur les composants de l'arbre).
Si l'arbre élémentaire à représenter ne possède pas de représentation prototypique, et s'il n'existe aucune représentation prototypique de sa famille catégorielle, on commence par créer de toutes pièces une représentation prototypique de cette nouvelle famille catégorielle, puis on construit une représentation prototypique de ce nouveau représentant de cette famille (en tenant compte des informations fournies pour décrire ce nouvel arbre).
Phase 3 : Génération des prototypes d'arbres d'analyses associés à chacun des arbres élémentaires.
On procède de la même manière que pour les arbres élémentaires.
Phase 4 : On construit ensuite les liens entre les prototypes lexicaux et les prototypes d'arbres élémentaires qui leurs sont associés.
Phase 5 : De même pour les liens entre les arbres d'analyses et les arbres élémentaires auxquels ils sont associés.
8.1.4.2. Génération du dictionnaire
Dans la phase 1, on utilise les outils déjà présentés (<- partie 2 chapitre 7) pour la génération de prototypes représentant des unités lexicales : on utilise les savoirs morphologiques et sémantiques fournis pour construire les représentations prototypiques des mots. Tous les prototypes créés, représentant des entrées lexicales, sont enregistrés dans un dictionnaire. Cette phase correspond donc à une construction dynamique du dictionnaire des entrées lexicales connues par le programme. On dispose en fait de plusieurs dictionnaires dont les contenus présentent les savoirs construits suivant des critères de recherche précis.
8.1.4.3. Génération d'un prototype de grammaire
Dans les phases 2 et 3, on utilise un générateur d'arbres similaire à celui déjà présenté (<- partie 2 chapitre 7) à la différence qu'il peut désormais construire des arbres auxiliaires (<- chapitre 3 : TAGs) utilisables dans les opérations d'adjonction (-> génération automatique d'arbres). Cette phase correspond à une construction dynamique d'une grammaire lexicalisée implicite qui associe à chaque entrée lexicale une suite d'arbres élémentaires et d'analyse. Tous les arbres créés sont enregistrés dans des dictionnaires correspondant à leur nature. La grammaire produite n'est donc pas construite explicitement mais elle se définit par les liens qui existent entre les prototypes lexicaux et les prototypes d'arbres créés.
8.1.4.4. Ajustement des bases de savoirs
Dans la mesure où il est possible à tout moment de modifier les savoirs initiaux attachés aux entrées lexicales, un ajustement des savoirs attachés à une entrée lexicale doit se propager sur les différentes représentations prototypiques associées à cette entrée lexicale. Il suffit donc :
soit de modifier les objets issus de la lecture de corpus et de réitérer les Phases 0 à 5 (dans ce cas la phase 1 ne regénère pas le prototype lexical mais ajuste les représentations existantes). De même les phases 2 et 3 ne regénèrent que les entités non encore reconnues et ajustent les autres si nécessaire.
soit de modifier dynamiquement les représentations prototypiques créées.
Si on doit par exemple modifier les contraintes associées à un arbre (élémentaire ou d'analyse), il est possible de modifier directement le prototype d'arbre contenu dans le dictionnaire correspondant.
On donne en annexe (-> annexe partie 2 chapitre 8) une trace de cette phase de génération des prototypes de mots et des contraintes associées. De plus une présentation complète des outils mis en place est faite elle aussi en annexe (-> incise 3).
8.1.5. Le réseau de prototypes dévoile une hiérarchie évolutive
8.1.5.1. Repérer les comportements partagés par les prototypes lexicaux
Si on reprend l'exemple précédent, l'approche retenue ici conduit à la mise en place des opérations schématisées ci-dessous. On dispose au départ d'une description textuelle des informations associées à un mot. A partir de celles-ci, on construit les prototypes pour représenter le mot et les arbres associés.
Le schéma ci-contre est une illustration partielle du micro-réseau de relations et de prototypes qui est défini sur une entrée lexicale. Si on poursuit plus avant ce travail de représentation sur de nouvelles unités lexicales, il est clair que l'on disposera de nouveaux points de vue sur les unités représentées. Notamment pour évaluer les liens qui unissent ces unités sur la base des comportements qu'elles partagent.
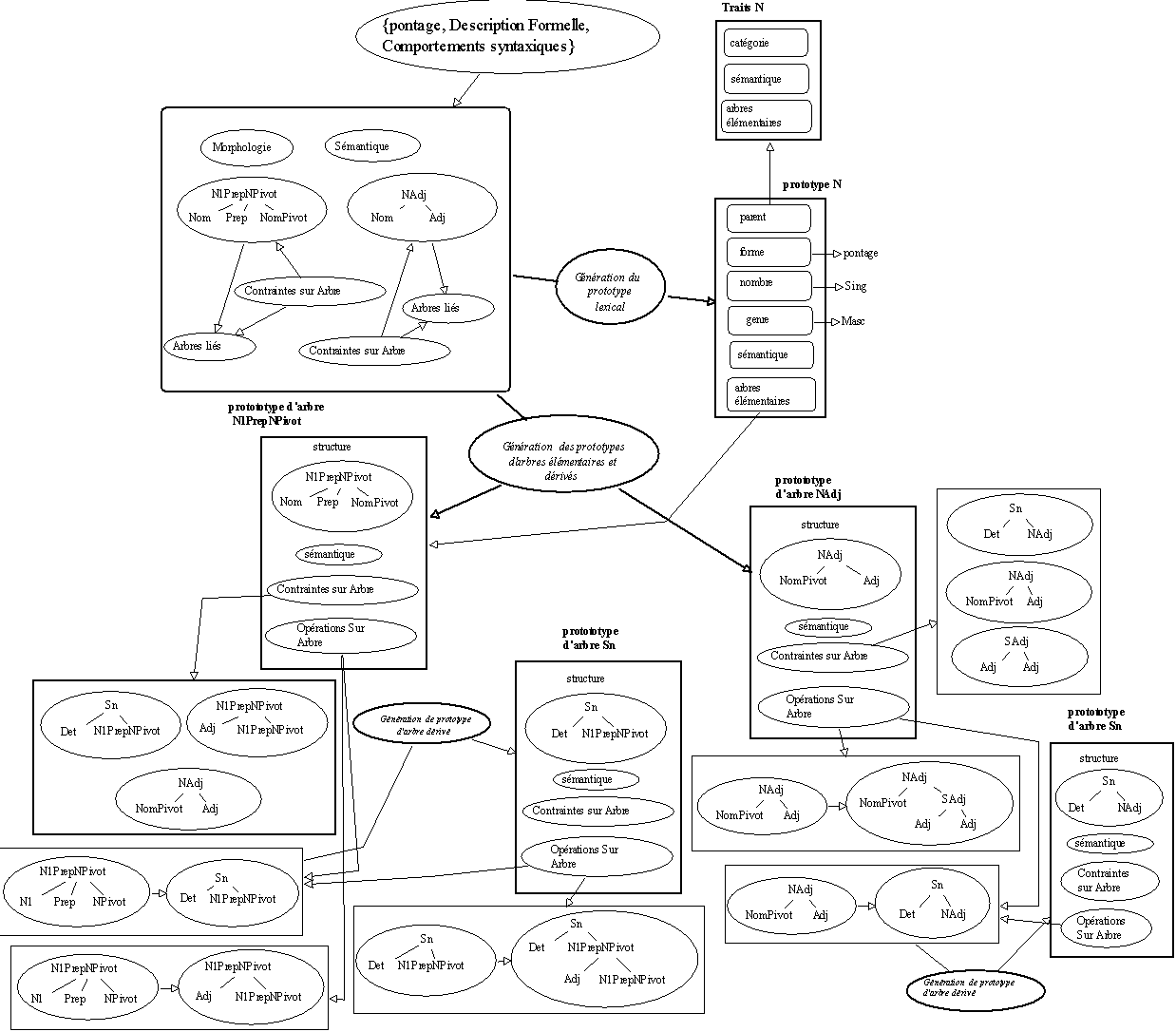
Figure 8.6 : Génération d'un prototype lexical et des prototypes d'arbres associés
A l'image de ce que nous faisions précédemment, nous pouvons désormais affiner notre travail de classement automatique des unités lexicales représentées sur la base de leurs comportements. Les savoirs attachés aux prototypes lexicaux se composent maintenant d'une liste d'arbres élémentaires (avec des contraintes possibles sur les noeuds de l'arbre) et pour chacun de ces arbres élémentaires d'une éventuelle liste d'arbres d'analyses (avec là aussi des contraintes possibles). Le classement construit se déroule de la manière suivante :
Dans un premier temps, on cherche à repérer sur les prototypes lexicaux construits les comportements partagés (i.e les arbres élémentaires communs); on construit ensuite un pôle qui va porter ce savoir partagé.
Si on considère les noms
stenose et lesion, ils partagent des savoirs et des comportements. Si on considère maintenant le nom angioplastie, celui-ci entre dans des constructions du type "indication de angioplastie". Des arbres élémentaires sont communs à un sous-ensemble de prototypes représentant ces noms. On construit donc un pôle de comportements partagés qui va porter les arbres élémentaires communs. On établit ensuite un lien de délégation entre ce pôle et les prototypes concernés. Sur notre famille de mots comprenant les noms stenose, lesion et angioplastie on obtient le mini réseau suivant :

Figure 8.7 : Un mini-réseau de hiérarchies locales
On évalue ensuite sur chaque pôle construit les extensions potentielles que les arbres associés à ce pôles permettent (-> classement des arbres élémentaires) quitte à construire de nouveaux pôles de comportements partagés par les arbres élémentaires si ces derniers mettent en avant des similarités comportementales (-> incise 4).
La figure 8.8 retrace les processus mis en place pour conduire des informations initiales au classement des unités lexicales.

Figure 8.8 : Génération et classement des prototypes
Les étiquettes sémantiques présentes dans cette figure ne résultent pas du processus de classification mis en place. Il s'agit en fait d'un travail d'interprétation manuel fait à l'issue du classement. On a qualifié le classement obtenu en utilisant ces étiquettes.
On donne infra et en annexe (-> annexe partie 2 chapitre 8 : classement des mots et des arbres, -> expérimentations sur corpus) une trace du classement réalisé.
8.1.5.2. Rôle et utilisations des arbres élémentaires
Les arbres élémentaires : des amorces syntaxiques pour le classement des mots
Le rapport entre les arbres élémentaires (simplifiés) et les arbres d'analyses n'est pas exploité de manière définitive dans le classement des unités lexicales à partir des arbres élémentaires qui leur sont attachés. Il convient d'examiner plus précisément si les dérivations décrites par ces associations donnent des informations supplémentaires sur les unités lexicales auxquelles sont attachées ces structures syntaxiques.
arbre élémentaire <---> arbres d'analyses
Description des modifications des liens sémantiques entre les composants des arbres : glissements de sens, changement de type....
On peut par exemple examiner si le lien entre arbre élémentaire et arbres d'analyses produit du savoir. Le classement réalisé s'appuie principalement sur les arbres élémentaires associés aux mots. La phase de classement rapproche les unités lexicales de même catégorie qui partagent des arbres élémentaires. Elle indique aussi pour chaque arbre élémentaire d'un pôle construit de comportements partagés les arbres d'analyse associés à chacun de ces comportements. Mais elle ne dit rien de plus sur ces extensions potentielles que chaque arbre élémentaire peut induire : les différences comportementales des arbres élémentaires sont constatées mais ne sont pas interprétées (-> classement des arbres élémentaires). Les résultats présentés infra (-> expérimentations sur corpus) donnent une illustration du travail qu'il reste à faire pour interpréter plus avant les liens qui existent entre arbres élémentaires et arbres d'analyse associés.
Les arbres élémentaires ont une histoire syntaxique
Le rapport entre les arbres élémentaires et les arbres d'analyse associés n'est donc pas, à ce stade de notre travail, utilisé pour interpréter automatiquement les résultats construits dans le classement des mots. Il convient d'examiner manuellement si les dérivations décrites par ces associations apportent des informations supplémentaires sur les unités lexicales auxquelles sont attachées ces structures syntaxiques (-> classement des arbres élémentaires). Cet examen des liens entre arbre élémentaire et arbre d'analyse constitue une des étapes du travail manuel d'interpretation qu'il convient de faire pour évaluer les résultats construits.
arbre élémentaire <---> arbres d'analyses
Description formelle des mécanismes qui permettent de passer de l'un aux autres et réciproquement.
La phase de représentation des structures syntaxiques associées aux unités lexicales passe par un travail de formalisation des relations de dépendance qui sont mises en évidence dans la phase de simplification des arbres élémentaires. Nous disposons cependant d'une première série d'outils qui permettent de représenter dynamiquement les liens entre les arbres élémentaires associés aux unités lexicales et les arbres complexes dans lesquels ces arbres de base peuvent être insérés (-> génération automatique d'arbre).
Classement des arbres élémentaires
Le classement des mots présentés supra rapproche les unités lexicales qui partagent des arbres élémentaires mais n'utilise pas l'"histoire syntaxique" des arbres élémentaires pour qualifier les pôles de comportements construits. Le dispositif permet cependant d'evaluer automatiquement les différences comportementales des arbres élémentaires. Il est en effet possible d'établir une recherche sur les arbres élémentaires de même catégorie des comportements partagés (arbres d'analyse) par ces arbres élémentaires. Ce classement utilise une démarche similaire à celle qui est utilisée pour classer les mots. Sur une famille d'arbre élémentaire de même catégorie, le dispositif va rechercher les prototypes d'arbres élémentaires qui possèdent des comportements similaires (i.e. les mêmes arbres d'analyse). S'il en trouve, il va construire automatiquement un pôle de comportements partagés pour les prototypes d'arbres élémentaires concernés et établir un lien de délégation entre ce pôle et les prototypes d'arbres.
Les résultats construits sur le classement des arbres élémentaires peuvent donc être utilisé pour affiner le classement mis en place pour les mots : les arbres élémentaires associés à un pôle de comportements partagés par un ensemble de mots sont potentiellement porteurs de comportements partagés par un ensemble d'arbres élémentaires. C'est en examinant les résultats construits à la suite de ces deux phases de classement qu'il est possible de déterminer si ces délégations de comportements à double niveau produisent de nouveaux savoirs (-> incise 4).
Génération automatique d'arbres (au cours d'une analyse)
Le dispositif établit des liens entre arbres élémentaires et arbres d'analyse (ces liens sont enregistrés dans les dictionnaires construits lors de la phase de génération des arbres). On peut aussi vouloir décrire les opérations qui permettent de passer de l'arbre élémentaire aux arbres d'analyses. En effet, il est important, dans le cadre de travail développé ici, de pouvoir associer aux arbres élémentaires représentés (et donc aux prototypes associés) les processus qui permettent de construire les arbres d'analyses associés à ces arbres élémentaires. Si les arbres élémentaires à représenter sont susceptibles d'adjonction ou de substitution, on peut associer à la représentation prototypique de ces arbres élémentaires les processus qui permettent de réaliser et donc de construire les arbres obtenus par adjonction ou par substitution à partir des prototypes représentant les arbres élémentaires. On a ainsi une représentation dynamique de l'arbre élémentaire de base, celle-ci incluant les mécanismes de production dynamique des arbres d'analyses qui lui sont associés. Les représentations prototypiques des arbres élémentaires disposent ainsi d'un savoir sur les articulations potentielles que leur structure de base peut induire.
En particulier, on peut avoir besoin de produire l'arbre résultant d'une opération de substitution ou d'une opération d'adjonction sur un arbre construit (un prototype d'arbre construit est associé à une structure syntaxique dont les composants sont eux mêmes des prototypes d'arbre ou de mots construits) : c'est le cas par exemple au cours d'une analyse automatique.
Prenons un exemple : le mot
pontage est associé aux arbres élémentaires et aux arbres d'analyse décrits dans le figure qui suit :

On doit donc pouvoir au cours d'une analyse reconstruire les arbres inscrits dans ces suites de dérivations potentielles. Pour réaliser cette génération de prototypes d'arbres, le dispositif construit utilise des opérateurs qui permettent de réaliser des opérations dynamiques sur les arbres, c'est-à-dire de construire dynamiquement les représentations prototypiques d'arbres obtenus par adjonction ou par substitution d'un prototype d'arbre sur une autre représentation prototypique d'arbre.
Construction des arbres de substitution
Pour réaliser cette génération de prototypes d'arbres construits, le dispositif construit utilise des opérateurs qui permettent de générer de nouveaux prototypes d'arbres à partir de ceux existants. Le générateur d'arbre prend en entrée les deux prototypes concernés et réalise l'opération de substitution : dans le cas d'une analyse avec le mot
pontage, substitution de l'arbre construit NPrepN dans l'arbre (à construire) Sn (Det NPrepN).
Construction des arbres auxiliaires pour l'adjonction
Pour l'adjonction de prototype, on dispose là aussi d'outils qui permettent de réaliser la génération de prototypes résultant de l'opération d'adjonction entre deux prototypes. L'opération se réalise de la manière suivante. On dispose d'une part d'un arbre élémentaire
Ae(i) que l'on peut noter :
Ae(i) (Xi -> (Xij) (j=1...)
chacun des
Xij étant lui-même un arbre élémentaire. D'autre part, on dispose d'un arbre auxiliaire Aa(k) noté :
(Aa(k) (Yk -> (Ykj) (j=1...))
et tel que
Yk soit dans { Xij (j=1...) }. L'adjonction peut donc se réaliser suivant le schéma ci-contre :
Figure 8.9 : Opération d'ajonction sur arbres
Le générateur d'arbre prend donc en entrée les deux prototypes pour mettre en oeuvre l'opération d'adjonction et réalise l'opération d'adjonction : dans le cas d'une analyse avec le mot
pontage par exemple, ajout de l'arbre construit SAdj dans l'arbre construit NAdj.
On donne en annexe (-> annexe partie 3 chapitre 9 : analyse automatique avec
Gaspar) une trace de la génération automatique d'arbres au cours d'une analyse.
8.2. Expérimentations sur corpus
8.2.1. Résultats construits sur un corpus de test
Le mini-corpus de test que nous utilisons contient 44 mots et une centaine d'arbres élémentaires et d'analyse. Sur ce corpus les processus de génération et de classement conduisent à la mise en place d'un réseau de prototypes dans lequel certains objets sont porteurs de comportements partagés.
Les figures qui suivent présentent des traces graphiques des prototypes générés lors du processus de génération et des pôles de comportements partagés construits. La trace dont le déroulement est donné en annexe (-> annexe partie 2 chapitre 8) ne présente que les deux premières contraintes traitées sur le corpus de test. Elle commence avec le mot
pontage. Avant cette phase de travail, il n'existe aucune représentation prototypique de mot ou d'arbre. Le processus de génération doit tout d'abord créer les objets de toutes pièces puis en créer de nouveaux par clonage et ajustement. Comme il n'existe aucune représentation prototypique de la catégorie des noms, le processus construit un prototype pour représenter cette catégorie, puis un prototype pour représenter le mot. Pour traiter la deuxième contrainte, le processus construit une représentation du mot lesion par clonage et ajustement en utilisant ces prototypes initialement générés. Il en va de même pour la génération des arbres.
Sur le corpus suivant :
lesion, vraiment, pontage, de, a, avec, sur, gauche, proximal, moyen, distal, anterieur, inferieur, superieur, serre, severe, tres, peu, pas, coronaire, carotide, circonflexe, marginale, long, ulcere, complexe, inhomogene, absence, pas, risque, presence, apparition, constitution, persistance, residuel, significatif, important, negligeable, predominant, premier, double
on obtient les résultats ci-dessous.
Dans la figure 8.10 on trouve tous les prototypes construits automatiquement par le processus de génération mis en place (tous ces objets , sur la gauche, ne sont pas expansés). On peut aussi y voir l'attribut de l'objet

Figure 8.10 : Génération des prototypes : trace graphique (1)
Dans la figure 8.11 on trouve les deux prototypes d'arbres élémentaires construits et associés au prototype lexical
Il s'agit des prototypes représentant l'arbre
NAdj et l'arbre N1 Prep NPivot.

Figure 8.11 : Génération des prototypes : trace graphique (2)
Cette troisième figure donne une trace graphique du pôle de comportement construit sur notre corpus (-> pôle n°5). Il s'agit du pôle de comportement regroupant les adjectifs
Un certain nombre d'étiquettes sémantiques ont été associées manuellement aux prototypes lexicaux construits sur le corpus de test. Le petit nombre de mots représentés nous a permis d'ajuster les prototypes construits avec une liste limitée d'étiquettes. Ce travail reste à affiner.
Liste des prototypes partageant les memes Comportements :
<Cat : Adj|Forme : carotide|Arbres elementaires : a list(an object)>
Concept (0) : vaisseau
<Cat : Adj|Forme : circonflexe|Arbres elementaires : a list(an object)>
Concept (0) : vaisseau
<Cat : Adj|Forme : coronaire|Arbres elementaires : a list(an object)>
Concept (0) : vaisseau
<Cat : Adj|Forme : marginale|Arbres elementaires : a list(an object)>

Figure 8.12 : Classement des prototypes : trace graphique (1)
La figure 8.13 présente une trace graphique du pôle de comportement regroupant les noms
Liste des prototypes partageant les memes Comportements :
<Cat : Nom|Forme : risque|Arbres elementaires : a list(an object)>
Concept (0) : etat
<Cat : Nom|Forme : apparition|Arbres elementaires : a list(an object)>
Concept (0) : proc
Concept (1) : evt
<Cat : Nom|Forme : persistance|Arbres elementaires : a list(an object)>
Concept (0) : etat
<Cat : Nom|Forme : pas|Arbres elementaires : a list(an object)>
Concept (0) : etat
<Cat : Nom|Forme : presence|Arbres elementaires : a list(an object)>
Concept (0) : etat
<Cat : Nom|Forme : absence|Arbres elementaires : a list(an object)>
Concept (0) : etat
<Cat : Nom|Forme : constitution|Arbres elementaires : a list(an object)>
Concept (0) : proc

Figure 8.13 : Classement des prototypes : trace graphique (2)
Sur la catégorie grammaticale des adjectifs, on obtient les pôles de comportements partagés suivants :
Pour chaque pôle présenté infra, le processus de classement propose une trace dans la fenêtre shell qui donne la liste des prototypes de mots associés à ce pôle sous la forme suivante :
<catégorie du mot , forme du mot, arbres élémentaires associés à ce mot>
Sur un pôle donné, l'arbre ou les arbres élémentaires sont les arbres partagés par les mots visés.
Pôle n°1 :
Liste des prototypes partageant les memes Comportements :
<Cat : Adj|Forme : posterieur|Arbres elementaires : a list(an object)>
<Cat : Adj|Forme : moyen|Arbres elementaires : a list(an object)>
Concept (0) : loc-lieu
<Cat : Adj|Forme : inferieur|Arbres elementaires : a list(an object)>
Concept (0) : loc-lieu
<Cat : Adj|Forme : gauche|Arbres elementaires : a list(an object)>
<Cat : Adj|Forme : distal|Arbres elementaires : a list(an object)>
<Cat : Adj|Forme : superieur|Arbres elementaires : a list(an object)>
Concept (0) : loc-lieu
<Cat : Adj|Forme : anterieur|Arbres elementaires : a list(an object)>
Concept (0) : loc-lieu
<Cat : Adj|Forme : droit|Arbres elementaires : a list(an object)>
Concept (0) : loc-lieu
<Cat : Adj|Forme : proximal|Arbres elementaires : a list(an object)>
Concept (0) : loc-lieu
Pôle n°2 :
Liste des prototypes partageant les memes Comportements :
<Cat : Adj|Forme : inhomogene|Arbres elementaires : a list(an object)>
Concept (0) : car
<Cat : Adj|Forme : complexe|Arbres elementaires : a list(an object)>
Concept (0) : car
<Cat : Adj|Forme : long|Arbres elementaires : a list(an object)>
Concept (0) : car
<Cat : Adj|Forme : ulcere|Arbres elementaires : a list(an object)>
Concept (0) : car
Pôle n°3 :
Liste des prototypes partageant les memes Comportements :
<Cat : Adj|Forme : negligeable|Arbres elementaires : a list(an object)>
Concept (0) : degre
<Cat : Adj|Forme : predominant|Arbres elementaires : a list(an object)>
Concept (0) : degre
<Cat : Adj|Forme : significatif|Arbres elementaires : a list(an object)>
Concept (0) : degre
<Cat : Adj|Forme : important|Arbres elementaires : a list(an object)>
Concept (0) : degre
Pôle n°4 :
Liste des prototypes partageant les memes Comportements :
<Cat : Adj|Forme : serre|Arbres elementaires : a list(an object)>
Concept (0) : degre
<Cat : Adj|Forme : severe|Arbres elementaires : a list(an object)>
Concept (0) : degre
Pôle n°5 :
Liste des prototypes partageant les memes Comportements :
<Cat : Adj|Forme : carotide|Arbres elementaires : a list(an object)>
Concept (0) : vaisseau
<Cat : Adj|Forme : circonflexe|Arbres elementaires : a list(an object)>
Concept (0) : vaisseau
<Cat : Adj|Forme : coronaire|Arbres elementaires : a list(an object)>
Concept (0) : vaisseau
<Cat : Adj|Forme : marginale|Arbres elementaires : a list(an object)>
Sur la catégorie grammaticale des adverbes, on obtient le pôle de comportement partagé suivant :
Liste des prototypes partageant les memes Comportements :
<Cat : Adverbe|Forme : pas|Arbres elementaires : a list(an object)>
Concept (0) : etat
<Cat : Adverbe|Forme : peu|Arbres elementaires : a list(an object)>
<Cat : Adverbe|Forme : tres|Arbres elementaires : a list(an object)>
Concept (0) : degre
<Cat : Adverbe|Forme : non|Arbres elementaires : a list(an object)>
Sur la catégorie grammaticale des noms, on obtient le pôle de comportement partagé suivant :
Liste des prototypes partageant les memes Comportements :
<Cat : Nom|Forme : risque|Arbres elementaires : a list(an object)>
Concept (0) : etat
<Cat : Nom|Forme : apparition|Arbres elementaires : a list(an object)>
Concept (0) : proc
Concept (1) : evt
<Cat : Nom|Forme : persistance|Arbres elementaires : a list(an object)>
Concept (0) : etat
<Cat : Nom|Forme : pas|Arbres elementaires : a list(an object)>
Concept (0) : etat
<Cat : Nom|Forme : presence|Arbres elementaires : a list(an object)>
Concept (0) : etat
<Cat : Nom|Forme : absence|Arbres elementaires : a list(an object)>
Concept (0) : etat
<Cat : Nom|Forme : constitution|Arbres elementaires : a list(an object)>
Concept (0) : proc
Sur la catégorie grammaticale des quantitatifs, on obtient le pôle de comportement partagé suivant :
Liste des prototypes partageant les memes Comportements :
<Cat : Quant|Forme : premier|Arbres elementaires : a list(an object)>
Concept (0) : ord
<Cat : Quant|Forme : double|Arbres elementaires : a list(an object)>
Concept (0) : card
8.2.2. Résultats construits sur des gros corpus
8.2.2.1. Etude de la relation NAdj
Nous limitons ici notre étude à certaines configurations nominales et plus particulièrement aux séquences du type
NAdj. Il s'agit en particulier de rechercher au niveau des mots des régularités et des redondances d'utilisation puis d'évaluer les regroupements obtenus (Justeson & Katz 1995). Deux corpus sont utilisés pour mettre en oeuvre les outils définis : le premier est obtenu via le travail d'extraction réalisé par Lexter, le second via l'extracteur AlethIP.Remarques préliminaires sur les corpus étudiés
Dans les deux corpus traités ci-dessous, nous n'avons retenu que la relation (mot, arbre élémentaire) : i.e. aucun arbre d'analyse n'est associé aux arbres élémentaires attachés aux mots.
Les séquences retenues présentent, pour les deux corpus étudiés, un plus grand nombre de séquences dans lesquelles l'adjectif est en position de postposition
Dans le premier corpus (via Lexter), on a la répartition suivante :
sur 1441 séquences
NAdj sélectionnées, on a 1260 séquences dans lesquelles l'adjectif est postposé et 181 séquences où il est antéposé.
Dans le second corpus (via AlethIP), on a la répartition suivante :
sur 1679 séquences
NAdj sélectionnées, on a 1444 séquences dans lesquelles l'adjectif est postposé et 235 séquences où il est antéposé.Résultats Lexter et Cyclade : Caractérisation des relations pour les adjectifs (Habert & al. 1996)
Le réseau des adjectifs renseigne plutôt sur les relations et attributs à attacher aux notions. Il est dominé par les localisants, en particulier ceux qui renvoient à des artères :
marginal coronaire circonflexe diagonal coronarien. L'opposition droit gauche constitue en fait une localisation auxiliaire, dans des contextes comme artere circonflexe gauche. Autre localisation, distincte, celle qui concerne la famille d'infarctus : anterieur apical inferieur. Si artere comme infarctus entrent dans une relation de localisation, celle-ci se réalise de deux facons différentes.
Contextes
1. Lexter :
[/SN [/SN [/Nom ARTERE]][/SAdj [/Adj CORONAIRE]]]
[/SN [/SN [/Nom ARTERE]][/SAdj [/Ppa NON_PONTE]]]
[/SN [/SN [/Nom ARTERE]][/SAdj [/Adj BRACHIAL]]]
[/SN [/SN [/Nom ARTERE]][/SAdj [/Adj PULMONAIRE]]]
[/SN [/SN [/Nom ARTERE]][/SAdj [/Adj CIRCONFLEXE]]]
[/SN [/SN [/Nom ARTERE]][/SAdj [/Adj DIAGONAL]]]
[/SN [/SN [/Nom ARTERE]][/SAdj [/Adj AURICULOVENTRICULAIRE]]]
[/SN [/SN [/Nom ARTERE]][/SAdj [/Adj NON_STENOSE]]]
[/SN [/SN [/Nom ARTERE]][/SN [/XX COLLATERALISEE]]]
[/SN [/SN [/Nom ARTERE]][/SAdj [/Adj HUMERAL]]]
[/SN [/SN [/Nom ARTERE]][/SAdj [/Adj INCOMPRESSIBLE]]]
[/SN [/SAdj [/Adj GROS]][/SN [/Nom ARTERE]]]
[/SN [/SN [/Nom ARTERE]][/SAdj [/Adj IRREGULIER]]]
[/SN [/SN [/Nom ARTERE]][/SAdj [/Adj TRES_PATHOLOGIQUE]]]
[/SN [/SN [/Nom ARTERE]][/SAdj [/Adj RENAL]]]
[/SN [/SAdj [/Adj PETIT]][/SN [/Nom ARTERE]]]
[/SN [/SN [/Nom ARTERE]][/SAdj [/Ppa TRES_GRELE]]]
[/SN [/SN [/Nom ARTERE]][/SAdj [/Adj CORONARIEN]]]
[/SN [/SN [/Nom ARTERE]][/SAdj [/Adj DOMINANT]]]
[/SN [/SAdj [/Adj BEAU]][/SN [/Nom ARTERE]]]
[/SN [/SN [/Nom ARTERE]][/SN [/Nom LATERO-DIAGONALE]]]
2.AlethIP :
[/SN [/SAdj [/Adj AUTRE]][/SN [/Nom ARTERE]]]
[/SN [/SAdj [/Adj BEAU]][/SN [/Nom ARTERE]]]
[/SN [/SAdj [/Adj GROS]][/SN [/Nom ARTERE]]]
[/SN [/SAdj [/Adj PETIT]][/SN [/Nom ARTERE]]]
[/SN [/SN [/Nom ARTERE]][/SAdj [/Adj BRACHIAL]]]
[/SN [/SN [/Nom ARTERE]][/SAdj [/Adj CIRCONFLEXE]]]
[/SN [/SN [/Nom ARTERE]][/SAdj [/Adj CORONAIRE]]]
[/SN [/SN [/Nom ARTERE]][/SAdj [/Adj CORONARIEN]]]
[/SN [/SN [/Nom ARTERE]][/SAdj [/Adj DIAGONAL]]]
[/SN [/SN [/Nom ARTERE]][/SAdj [/Adj DOMINANT]]]
[/SN [/SN [/Nom ARTERE]][/SAdj [/Adj FEMORAL]]]
[/SN [/SN [/Nom ARTERE]][/SAdj [/Adj HUMERAL]]]
[/SN [/SN [/Nom ARTERE]][/SAdj [/Adj ILIAQUE]]]
[/SN [/SN [/Nom ARTERE]][/SAdj [/Adj INCOMPRESSIBLE]]]
[/SN [/SN [/Nom ARTERE]][/SAdj [/Adj LATERAL]]]
[/SN [/SN [/Nom ARTERE]][/SAdj [/Adj MAMMAIRE]]]
[/SN [/SN [/Nom ARTERE]][/SAdj [/Adj PULMONAIRE]]]
[/SN [/SN [/Nom ARTERE]][/SAdj [/Adj RENAL]]]
[/SN [/SN [/Nom ARTERE]][/SAdj [/Adj DOMINE]]]
[/SN [/SN [/Nom ARTERE]][/SN [/XX CIRCONTLEXE]]]
[/SN [/SN [/Nom ARTERE]][/SN [/XX COLLATERALISEE]]]
[/SN [/SN [/Nom ARTERE]][/SAdj [/Adj AURICULOVENTRICULAIRE]]]
[/SN [/SN [/Nom ARTERE]][/SAdj [/Adj CIRCONFLEXE]]]
Contextes
1.Lexter
[/SN [/SN [/Nom INFARCTUS]][/SAdj [/Adj INFERIEUR]]]
[/SN [/SN [/Nom INFARCTUS]][/SAdj [/Adj ANTERIEUR]]]
[/SN [/SN [/Nom INFARCTUS]][/SAdj [/Adj BIOLOGIQUE]]]
[/SN [/SN [/Nom INFARCTUS]][/SAdj [/Adj RECENT]]]
[/SN [/SN [/Nom INFARCTUS]][/SAdj [/Adj INFERO-POSTERIEUR]]]
[/SN [/SN [/Nom INFARCTUS]][/SAdj [/Adj INFERO-APICAL]]]
[/SN [/SN [/Nom INFARCTUS]][/SAdj [/Adj MYOCARDIQUE]]]
2.AlethIP
[/SN [/SN [/Nom INFARCTUS]][/SAdj [/Adj ANTERIEUR]]]
[/SN [/SN [/Nom INFARCTUS]][/SAdj [/Adj BIOLOGIQUE]]]
[/SN [/SN [/Nom INFARCTUS]][/SAdj [/Adj INFERIEUR]]]
[/SN [/SN [/Nom INFARCTUS]][/SAdj [/Adj RECENT]]]
Le réseau permet également de préciser les conditions d'emploi de
coronaire et coronarien. Malgré le nombre élevé de contextes partagés et leur appartenance commune à la clique coronaire coronarien diagonal circonflexe, les deux adjectifs ne sont pas synonymes.
Cooccurrences
1. Lexter
[/SN [/SN [/SN [/Nom OBSTRUCTION]][/SAdj [/Adj CORONARIEN]]][/SAdj [/Adj SEVERE]]]
[/SN [/SN [/SN [/Nom LESION]][/SAdj [/Adj CORONARIEN]]][/SAdj [/Adj SEVERE]]]
[/SN [/SN [/SN [/Nom OBSTRUCTION]][/SAdj [/Adj CORONARIEN]]][/SAdj [/Adj SEVERE]]]
[/SN [/SN [/SN [/Nom MALADIE]][/SAdj [/Adj CORONARIEN]]][/SAdj [/Adj SEVERE]]]
[/SN [/SN [/SN [/Nom ATHEROME]][/SAdj [/Adj CORONARIEN]]][/SAdj [/Adj SEVERE]]]
[/SN [/SN [/Nom LESION]][/SN [/SN [/Nom CORONARIEN]][/SAdj [/Adj TOUT-A-FAIT_SEVERE]]]]
[/SN [/SN [/SN [/Nom LESION]][/SAdj [/Adj CORONARIEN]]][/SAdj [/Adj SEVERE]]]
[/SN [/SN [/SN [/SN [/Nom LESION]][/SAdj [/Adj CORONARIEN]]][/SAdj [/Adj TRITRONCULAIRES]]][/SAdj [/Adj SEVERE]]]
[/SN [/SN [/SN [/Nom ATHEROSCLEROSE]][/SAdj [/Adj CORONARIEN]]][/SAdj [/Adj SIGNIFICATIF]]]
[/SN [/SN [/SN [/Nom LESION]][/SAdj [/Adj CORONARIEN]]][/SAdj [/Adj SIGNIFICATIF]]]
[/SN [/SN [/SN [/Nom ANOMALIE]][/SAdj [/Adj CORONARIEN]]][/SAdj [/Adj SIGNIFICATIF]]]
2. AlethIP
[/SN [/SN [/SN [/Nom LESION]][/SAdj [/Adj CORONARIEN]]][/SAdj [/Adj SEVERE]]]
[/SN [/SN [/SN [/Nom MALADIE]][/SAdj [/Adj CORONARIEN]]][/SAdj [/Adj SEVERE]]]
[/SN [/SN [/SN [/Nom OBSTRUCTION]][/SAdj [/Adj CORONARIEN]]][/SAdj [/Adj SEVERE]]]
[/SN [/SAdj [/Adj SEUL]][/SN [/SN [/SN [/Nom ANOMALIE]][/SAdj [/Adj CORONARIEN]]][/SAdj [/Adj SIGNIFICATIF]]]]
[/SN [/SN [/Nom ABSENCE]][/SP [/Prep DE][/SN [/SN [/SN [/Nom ATHEROMATOSE]][/SN [/Nom CORONARIEN]]][/SAdj [/Adj SIGNIFICATIF]]]]]
[/SN [/SN [/SN [/Nom ATHEROSCLEROSE]][/SAdj [/Adj CORONARIEN]]][/SAdj [/Adj SIGNIFICATIF]]]
[/SN [/SN [/SN [/Nom LESION]][/SAdj [/Adj CORONARIEN]]][/SAdj [/Adj SIGNIFICATIF]]]
Cooccurrences
1. Lexter
[/SN [/SN [/Nom PAS]][/SP [/Prep DE][/SN [/SN [/SN [/Nom LESION]][/SAdj [/Adj CORONAIRE]]][/SAdj [/Adj SIGNIFICATIF]]]]]
2. AlethIP
[/SN [/SN [/SN [/Nom LESION]][/SAdj [/Adj CORONAIRE]]][/SAdj [/Adj SIGNIFICATIF]]]
Ce réseau comprend enfin des antonymes :
residuel severe et important minime qui peuvent exprimer la relation de degré à attacher à certaines affections.8.2.2.2. Travail sur le corpus fourni par Lexter
Données traitées
Dans un premier temps nous avons travaillé sur des séquences
NAdj extraites via Lexter. A partir de 8754 séquences comportant des groupes nominaux, nous avons extraits 609 mots (des noms) auxquels sont attachés 1441 arbres élémentaires de type :
Sn -> Nom Adj
Sn -> Adj Nom
Sn -> Adj XX
Sn -> XX Adj
Cette première sélection a donc consisté à ne garder que les arbres binaires portant les feuilles
Nom/XX et Adj.8.2.2.3. Travail sur le corpus fourni par AlethIP
Données traitées
A partir de 7766 séquences extraites via AlethIP comportant des groupes nominaux, nous avons extraits 718 mots (des noms) auxquels sont attachés 1680 arbres élémentaires de même type que précédemment.
8.2.2.4. Le travail sur les gros corpus et les limites de Self
"Prolog est né d'un pari : créer un langage de très haut niveau, même inefficace au sens des informaticiens de l'époque. L'efficacité consistait alors à faire exécuter très rapidement par une machine des programmes écrits laborieusement. Le pari était donc de pouvoir écrire rapidement des programmes, quitte à ce que la machine les exécute laborieusement."
Colmerauer, préface à Giannesini & al. "Prolog", InterEditions, 1985.
Les processus de génération de prototypes présentés supra ont mis en avant les limites actuelles de l'implémentation de Self quand ces processus sont activés sur de gros corpus. Après la génération d'une cinquantaine de prototypes de mot de ces corpus et des arbres associés (environ une centaine d'objets), le système Self s'"écroule" par manque de ressources. Le problème est en fait lié à un manque de mémoire pour exécuter la construction dynamique de nouveaux objets. Self est de fait peu habitué à manipuler autant d'objets dans une même session de travail. Les créateurs de Self ont essayé de remédier à ces problèmes en ajustant l'implémentation. Cette nouvelle version n'a pas encore pu être testée sur nos corpus de travail : des problèmes de compatibilité de structure de représentation ont été mises à jour entre cette version et le code écrit pour
Gaspar. Cette incapacité actuelle du système Self à assimiler la génération d'un grand nombre d'objets met surtout en avant les problèmes complexes liés à la mise en oeuvre de ce type de modèle de représentations évolutives. Cette mise en oeuvre de la mouvance dans les outils de représentation coûte chère en ressources pour les systèmes sous-jacents. Ce contre-temps technique nous empêche donc pour le moment de produire des résultats pertinents sur les corpus Lexter et AlethIP.
Les processus sont prêts : seule la "mémoire" leur manque pour exprimer et produire des pistes de sens.
8.3. Représentation et classification dynamiques : bilans et perspectives
8.3.1. Une démarche interprétative contrôlée et en spirale
Les énoncés de langue se réalisent sous la forme d'agencements entre des évènements, des idées, des concepts, des sujets... Ils se construisent comme une suite hétérogène d'éléments qu'il s'agit de faire tenir ensemble. Un tel agencement se comporte comme une structure qui organise les co-fonctionnements des unités qui la composent. Ce qui importe, ce n'est pas tant les éléments pris individuellement, mais les relations qu'ils tissent entre eux pour produire du sens. Ces relations se déploient entre les unités et ne sont pas des propriétés attachées aux unités qui composent un énoncé. Un agencement de langue établit donc des faisceaux de relations entre les unités linguitiques, faits de pleins et de vides, de blocs et de ruptures, de blancs et de reprises, de nuances et de brusqueries, d'additions dont la somme n'est jamais arithmétiquement construite... Le sens d'un énoncé construit de l'imperceptible à partir de micro-perceptions : comment formaliser ceci de manière prédéfinie? Les modèles doivent maintenir présente cette notion d'expérimentation permanente dans la production des faits de langue. Les programmes de TALN doivent construire des moyens de repérage pour conduire une expérimentation sur les faits de langue qui déborde nos capacités de prévoir. Les représentations d'unités de langue doivent être des outils qui permettent au linguiste d'opérer un travail d'expérimentation sur les faits représentés. La langage n'est pas une masse inerte. Les relations que les unités linguistiques tissent entre elles dans un énoncé peuvent évoluer sans que les unités elles-même soient modifiées. Self encourage l'expérimentation, et nous choisissons donc de ne pas nous imposer de modèles interprétatifs prédéterminées dans les représentations que nous construisons. Notre approche vise à définir une démarche en spirale : construire des représentations par affinements successifs avec projections de savoirs soit constitués soit établis par ailleurs; puis ajustements et affinements des représentations à chaque nouvelle étape (Mikheev & Moens 1994). Comme notre programme n'est pas encore capable de produire systématiquement de nouvelles connaissances à partir de celles qui existent déjà, l'acquisition de nouvelles connaissances reste tributaire d'une intervention extérieure au programme capable de transmettre ces informations. Soit on agit directement sur les savoirs construits (intervention manuelle), soit on affine les informations initiales et on réitère la génération ou l'affinement de la représentation des objets.
8.3.2. Des amorçages d'interprétation : le retour du linguiste
Notre approche tend à distribuer les savoirs sur des myriades d'éléments capables de travailler chacun de leur côté, tout en mettant en place des "micro-instances" centralisatrices qui structurent les savoirs représentés sur des ensembles réduits d'éléments. Les savoirs représentés se déploient sur les prototypes construits et les pôles de savoirs partagés permettent de tisser des liens entre les prototypes représentés. La démarche suivie s'inscrit donc dans une perspective expérimentale à différents niveaux :
Travail sur des savoirs extraits de corpus.
Représentation des mots : construire les représentations informatiques des informations linguistiques formelles associées aux mots.
"Représentaction" sur les mots : construire les représentations des processus linguistiques ou des comportements linguistiques que l'on peut attacher à ces mots.
Corpus arboré
Le classement obtenu reste évidemment à affiner. Ce classement sur les entités représentées vise à la contruction de réseaux entre les prototypes définis à la manière d'un parcours entre ces prototypes représentés pour y trouver le chemin interprétatif adéquat. Nous insistons sur le fait que le système construit s'inscrit dans une approche qui vise à établir un dialogue entre les dispositifs informatiques construits et les problèmes posés par les faits linguistiques. L'intervention manuelle du linguiste s'inscrit parfaitement dans une telle approche.
8.3.3. Un système qui module les flux d'informations
On peut disposer en amont de plusieurs couches d'informations. Si le travail d'extraction de savoirs est capable de mettre en évidence différents types de savoirs sur une entité lexicale, on utilisera ces informations dès la première phase de génération du prototype construit pour représenter cette unité lexicale. On peut aussi envisager de procéder à une acquisition de savoirs en réitérant la phase initiale de lecture de ces savoirs initiaux. On pourrait ainsi moduler et modulariser cette phase d'acquisition de savoirs en activant différents flux de savoirs. Si les savoirs attachés aux mots ne sont pas disponibles dès la première phase de génération des prototypes associés, il sera toujours possible d'ajuster les représentations construites en utilisant un nouveau flux de savoirs disponibles ultérieurement.
Il est aussi possible de projeter les résultats transitoires obtenus sur des savoirs établis par ailleurs et d'utiliser les résultats de ces projections pour ajuster les représentations.
Phase1 : on utilise un corpus donné pour représenter puis classer les savoirs associés à ce corpus. On prend appui sur les savoirs généraux disponibles.
Cette première étape peut conduire à une mise à jour (manuelle ou automatique) sur les résultats construits : mise à jour sur les objets construits ou sur la base de savoirs généraux. Ces affinements résultent d'un travail d'interprétation fin des informations issues des activités de génération et de classement réalisées.

Figure 8.14 : Une démarche en spirale (1)
Phase 2 : Si de nouvelles informations sont mises à jour (affinement des informations dans le corpus ou mises à jour dans les savoirs généraux), il est possible de réitérer les processus de représentation (affinement de l'existant ou recréation à la volée de nouveaux objets) ou de classement pour tenir compte de celles-ci.

Figure 8.15 : Une démarche en spirale (2)
Phase 3 : On peut aussi confronter les résultats établis sur différents états de corpus ou sur des corpus de différentes natures. Dans le schéma qui suit, on peut appliquer les processus sur deux corpus différents et produire des résultats relatifs à ces deux corpus. On peut aussi appliquer les processus au seul corpus 2 pour établir par exemple une confrontation des résultats produits sur les deux corpus traités.

Figure 8.16 : Une démarche en spirale (3)
Le processus de représentation peut donc se développer en réitérant les phases suivantes :
représentations à partir de savoirs extraits d'un corpus
projections des résultats
ajustements des représentations
ajustement du classement
Ces différentes étapes peuvent induire des phases intermédiaires de travail manuel pour corriger les états de représentation produits (Mikheev & Moens 1994). L'environnement de programmation choisi permet à tout moment d'affiner les représentations construites (-> incise 2). Le dispositif mis en place utilise ce potentiel évolutif pour aider à la mise en oeuvre de ces ajustements. On dispose ainsi d'une série d'interfaces et d'outils qui permettent d'interroger, de modifier... les objets construits dans une séance de travail (-> annexe partie 2 chapitre 8, -> incise 2).
La PàP s'accommode bien avec cette démarche de représentation. Elle permet en effet de construire la représentation du domaine visé puis de classer les savoirs représentés de manière progressive : les processus de représentation puis de classement permettent une approche incrémentale. La représentation du domaine étudié pouvant évoluer, sa représentation s'améliore en fonction des résultats obtenus.
8.3.4. Prototypie et représentation des savoirs pour le TALN
8.3.4.1. Processus de représentation et TALN
Les mots ont leur(s) histoire(s)
Dans des situations de communication traditionnelles, les mots véhiculent leurs propre(s) histoire(s); et même s'il y a des trous, personne ne s'en "plaint vraiment" dans la mesure où l'on peut, en général, les combler sans peine, quitte à "réécrire" une nouvelle "histoire" autour ou entre les mots.
Retrouver/rechercher les connaissances liées à chaque mot
Dans notre approche de travail, il s'agit de rechercher les savoirs associés aux mots puis de les représenter en tenant compte des interactions multiples entre toutes les connaissances qui sont à l'oeuvre entre les mots.
Processus de représentation évolutifs
Le modèle de représentation mis en oeuvre prend appui sur un corpus arboré pour opérer un apprentissage des savoirs à représenter; il s'agit ensuite de construire par affinements successifs les structures pour porter les savoirs mis à jour. On cherche à réaliser une adéquation entre les occurrences linguistiques réalisées et les prédictions de représentations construites. Il ne s'agit pas de produire d'emblée un résultat définif qui réalise cette adéquation de manière parfaite; mais plutôt de tendre vers cette adéquation, par touches successives, en affinant les prédictions construites.
La mise en oeuvre des représentations est donc conçue comme un mécanisme évolutif qui, d'une part, doit tenir compte d'un nombre important de sources de connaissances, et d'autre part, doit être capable d'intégrer de nouvelles informations à chaque étape. Les représentations à construire ne sont donc pas figées mais peuvent évoluer dynamiquement en fonction des nouveaux savoirs utilisés ou mis à jour. L'apprentissage de nouveaux savoirs ne prédétermine et ne limite pas les sources de connaissances capables d'induire de nouveaux savoirs à associer aux mots.
Importance du travail manuel sur le corpus initial, puis sur les représentations construites.
Deux tâches fondamentales sont nécessaires pour mettre en oeuvre l'apprentissage des savoirs à partir d'un corpus initial. Il s'agit évidemment dans un premier temps d'affiner le travail d'extraction de savoirs sur le corpus utilisé : le travail sur corpus est conçu lui aussi comme un travail évolutif, on n'épuise jamais un corpus. Puis, il s'agit d'affiner le travail de représentation sur les entités représentées, en utilisant soit des résultats construits par ailleurs, soit les nouveaux résultats obtenus par le travail continu effectué sur le corpus initial.
8.3.4.2. Affinements des représentations
On a vu précedemment que la génération des savoirs linguistiques mise en oeuvre avec Gaspar s'effectue par une construction dynamique de prototypes pour représenter aussi bien les mots que les contraintes syntaxiques (les arbres) associées à ces mots. Les différentes opérations qui réalisent la construction effective de ces prototypes utilisent les outils mis en place par Self pour définir des objets ou pour ajuster leurs représentations. On rappelle que par exemple l'opération de clonage (réalisée par la primitive
clone appliquée à un objet) produit une copie du prototype auquel est adressé ce message. De même, les opérations d'ajout ou de retrait d'attributs (réalisées via les primitives _AddSlots:, _AddSlotsIfAbsent:, _RemoveSlot:...) permettent d'ajuster la représentation d'un objet donné en lui ajoutant un attribut (l'argument de cette primitive), ou en lui supprimant un attribut.Clonage et ajustements
Dans les mécanismes mis en place par Gaspar pour la génération des prototypes, on n'utilise pas la primitive de clonage prédéfinie telle quelle. En effet, les prototypes construits sont définis par certains attributs qui peuvent par exemple pointer sur d'autres objets : le prototype
pontage porte un attribut morphologie qui pointe vers un prototype morphologie décrivant la morphologie du mot. Si on appliquait l'opération de clonage au prototype pontage pour créer un nouveau prototype lexical, le prototype issu du clonage porterait lui aussi un attribut morphologie qui pointerait vers le même prototype morphologie associé au prototype pontage. On a donc défini des mécanismes de copie de prototypes qui enrichissent considérablement l'opération de clonage. La copie de prototype met en place des opérations qui initialisent tous les attributs de l'objet issu du clonage et qui peuvent aussi mettre à jour ces attributs si on dispose des informations adéquates.Ajouts/Retraits d'attributs et effets de bord
Les opérations d'ajout et de retrait d'attributs génèrent des effets de bord dont il faut absolument tenir compte. En effet, si on ajoute un attribut à un prototype donné, on créé, en fait, un nouveau prototype (un clone du prototype initial) sur lequel est greffé le nouvel attribut. Il existe toujours une trace du prototype initial tel qu'il était défini avant l'opération d'ajout d'attribut. Dans notre démarche de génération dynamique de prototypes, on utilise évidemment ces mécanismes d'ajout et de retrait d'attribut pour ajuster la représentation des objets que l'on a à construire. Mais seul le prototype construit à l'ultime phase d'ajouts ou de retraits d'attribut est considéré comme pertinent dans l'environnement de Gaspar : les prototypes "transitoires" sont incohérents, ils correspondent à un état intermédiaire de la construction d'un certain type de prototype, ils ne seront donc pas pris en compte dans les opérations d'analyse définies par Gaspar. Pour contrôler cette génération de prototype, on a donc mis en place des mécanismes de vérification de la structure interne des objets construits : un prototype sera "cohérent" s'il est issu des différentes phases de construction des prototypes de mots ou des prototypes d'arbres. Ce qui indiquera qu'il possède tous les facettes nécessaires pour être considéré comme valide dans l'environnement de Gaspar. De plus, pour ne pas multiplier inconsidérement les prototypes incohérents, on dispose d'un mécanisme qui permet de "détruire" tous ces prototypes incomplètement construits ou tout au moins de les "poubelliser". Ces opérations sont définies en utilisant les outils de méta-représentation disponibles avec Self et qui seront présentées infra.
8.3.4.3. Retour sur le stochastique
Affecter des poids aux arbres associés aux mots
"Le fait que ces arbres élémentaires apparaissent en rafales peut être l'indication d'un fonctionement dénominatif (une entité suffisamment importante pour donner lieu à redondance locale). Par exemple, une ellision du type "angine stable" n'a pas le même statut (quant à la dénomination éventuelle que l'on peut postuler) selon qu'elle arrive immédiatement après une forme longue : "On peut distinguer deux types d'angines de poitrine. L'angine stable..." et selon qu'elle se produit sans forme longue dans un contexte proche : dans ce dernir cas, il est nettement plus probable qu'"angine de poitrine" est une dénomination, et "angine stable" un hyponyme " (Habert & al. 1995).
Si un mot donné est associé à un arbre élémentaire dont le nombre de réalisation dans le corpus donné est faible et si un autre mot est associé au même arbre élémentaire mais dont le nombre de réalisation est beaucoup plus important, il peut être intéressant de disposer de ces données quantitatives pour qualifier les résultats ou tout au moins pour mettre en avant ces différences de comportements des unités lexicales visées. On peut ainsi tenir compte dans le classement des unités lexicales du "poids" que peuvent avoir les arbres associés sur ces unités. De même, pour un mot inconnu, on peut utiliser les arbres les plus probables sur telle catégorie pour une analyse sur une séquence qui contient ce mot inconnu.
Apprentissage et mot nouveau
Les savoirs recensés et construits sur un certain état du corpus vont être utilisés pour le parsage. Si le parseur analyse une phrase qui contient des mots non recensés (dans la phase initiale d'extraction de savoirs sur corpus), il va évaluer les comportements de ces nouveaux mots en fonction des savoirs déjà construits. Le parseur gardera comme solution d'analyse, celle qui semble la plus probable. Plus précisément, si au cours de l'analyse le parseur rencontre un mot nouveau, il construit des prototypes lexicaux (pour chaque catégorie déjà recensée) pour représenter ce nouveau mot. De plus ne sachant pas si ce nouveau mot est forcément un représentant d'une des catégories grammaticales déjà reconnues, le parseur construit aussi un prototype lexical de catégorie inconnue pour représenter ce mot nouveau. Ce dernier type de prototype pourra entrer dans toutes les compositions syntaxiques sollicitées par d'autres prototypes d'arbres.
Utilisation des savoirs construits
En procédant ainsi, l'analyse ne bloque pas sur des formes non prédéfinies ou non représentées. Au contraire elle permet à l'analyse de construire de nouvelles connaissances (les nouveaux mots représentés) et toutes les connaissances qui peuvent y être associées. Par exemple, si on considère que le parseur doit analyser une phrase contenant le mot
"pontage". Et s'il n'existe pas de prototypes lexicaux de même forme. Le parseur construit des prototypes lexicaux pour chacune des catégories grammaticales déjà construites avec cette forme. Les prototypes lexicaux ainsi définis vont hériter des comportements communs (s'il en existe) associés aux prototypes existants pour chacune de ces catégories. En particulier, si le classement des prototypes lexicaux a permis d'attribuer des arbres élémentaires aux objets qui portent les comportements communs des catégories construites, les prototypes lexicaux associés au mot "pontage" délègueront eux aussi à ces objets ces types de comportement. Ces savoirs hérités ne sont pas a priori des comportements associés aux nouveaux mots représentés, ils permettent simplement de relâcher l'analyse aux endroits où il peut y avoir blocage. Il reste ensuite à évaluer si cette association implicite de nouveaux savoirs à un mot initalement inconnu a permis de produire des savoirs pertinents sur ce mot et sur ces relations avec les autres mots.
De même, on utilise les arbres définis et contraints sémantiquement pour analyser des phrases qui pourraient contenir des mots nouveaux. A priori, si un mot est inconnu, les contraintes sur l'arbre vont bloquer la construction de cet arbre avec ce mot nouveau. On doit donc pouvoir relâcher ces contraintes si l'analyse rencontre un mot nouveau; il s'agira ensuite d'évaluer les constructions construites et les relâchements opérés pour produire un résultat significatif ou non. On opère ainsi ce type de relâchement dans le cas où l'analyse est confrontée à un prototype représentant un nouveau mot pour une éventuelle association avec tout prototype d'arbre rencontré.
On donne en annexe (-> annexe partie 3 chapitre 9 : analyse automatique avec Gaspar) une analyse qui illustre ce point. Dans l'analyse présentée, le parseur gaspar doit analyser la séquence "analyseur à prototypes". Cette séquence de mots contient une forme lexicale à laquelle le parseur ne va pas pouvoir, dans un premier temps, associer une ou plusieurs représentations prototypiques de mot. Il va associer, par défaut, à cette forme autant de représentations prototypiques de mot qu'il existe de catégorie pouvant potentiellement être associée à un mot. Il associe de plus à cette forme une représentation prototypique de mot de catégorie inconnue. L'analyse va donc se dérouler en utilisant ces savoirs construits automatiquement par le parseur en utilisant les savoirs déjà représentés.
8.4. Conclusion
1. Les processus de représentation des faits de langue sont contraints de faire évoluer les savoirs représentés (i.e. leurs structures de représentation construites) :
Les savoirs linguistiques sont évolutifs.
Leur représentation et leur classement sont donc en perpétuel ajustement.
La PàP permet de construire la représentation du domaine visé puis de classer les savoirs représentés de manière progressive : les processus de représentation puis de classement permettent une approche incrémentale. La représentation du domaine étudié pouvant évoluer, sa représentation s'améliore en fonction des résultats obtenus.
Les savoirs qui interviennent dans les faits de langue sont nombreux et interagissent de manière complexe. Il est évident qu'une modification dynamique de ces savoirs ou de leurs liens réciproques implique une attention particulière. Ce contrôle ne peut être réalisé que si on peut exercer un méta-regard sur le domaine des connaissances représentées.
2. Le classement des unités lexicales mis en place précédemment est confronté aux problèmes suivants :
Il est nécessaire là encore de disposer d'outils de contrôle pour réaliser le réseau de délégation induit par le classement défini.
La classement ne qualifie pas les pôles de comportements partagés mis en place. Les méta-connaissances nécessaires pour nommer les choses construites ne sont pas disponibles ni même définies.
Incise Chapitre 8
Incise 1. Self 4.0, un environnement informatique qui dynamise les objets
Self (et notamment la version 4.0) permet une gestion dynamique de la mise à jour des objets représentés. Self est disponible à l'adresse suivante : http://self.sunlabs.com.
I.1.1. Self-4.0 (Smith, Maloney, Ungar 1995)
Environnement de programmation
Définition et modification incrémentales des objets
Techniques expérimentales d'interaction
Manipulation directe des objets
Animation
Démarrer Self
Self est activé en tapant
Snapshot dans une session de travail. Self démarre avec :
Un prompt interactif dans une fenêtre
shell
La fenêtre
shell permet d'interroger les objets disponibles dans le monde Self et en particulier de les inclure dans l'interface graphique.
Une interface graphique interactive
L'environnement graphique est appelé le monde Self

Figure 8.17 : Interface
shell
La poubelle permet de nettoyer la fenêtre graphique en y déposant les objets que l'on ne souhaite plus y voir figurer.

Figure 8.18 :
"Trash-Can Self"I.1.2. Interfaces, outils, opérations et menus dans le monde Self
Menus des opérations sur le monde Self
En utilisant la souris dans la fenêtre graphique, on peut accéder à certains outils qui permettent d'agir sur le monde Self.

Figure 8.19 : Menu des opérations sur le monde Self
La touche droite de la souris active un menu des opérations sur le monde Self :
Les options disponibles permettent en particulier de :
Shell
créer un objet
shell;
Toggle Spy
activer un object qui contrôle les activités du système;
Write Snapshot
sauvegarder l'état présent du monde Self;
Quit
quitter la session de travail.
Menus des opérations spécifiques sur les objets Self
De même, tous les objets de la fenêtre graphique sont réactifs à la souris. On peut ainsi accéder à certains outils qui permettent d'agir sur les objets.



Figure 8.20 : Menus des opérations spécifiques sur les objets Self
La touche de gauche de la souris permet d'"attraper" les objets et de les déplacer dans la fenêtre graphique
La touche centrale de la souris active un menu des opérations spécifiques sur un objet
Menu des opérations spécifiques sur un objet
Les options disponibles permettent en particulier de :
Add Slot
ajouter un attribut à l'objet visé;
Comment
ajouter des commentaires à l'objet visé;
Annotation ...
éditer un objet porteur d'annotations sur l'objet visé;
Find Slot ...
créer un objet pour trouver un attribut dans l'objet visé;
Structure Editor
créer un éditeur pour l'objet visé;
Evaluator
créer un (ou plusieurs) évaluateur(s) pour l'objet visé;
Le touche droite de la souris active un menu des opérations globales sur les objets :
Opérations globales
Les options disponibles permettent en particulier de :
Duplicate
créer un copie de l'objet visé;
Resize
retailler les dimensions de l'objet;
Move to Own Window
créer un monde particulier (une nouvelle fenêtre) avec cet objet;
Dismiss
faire disparaître l'objet de la fenêtre;
Object expander
étendre ou de restreindre la présentation des attributs de l'objet.
On donne ci-dessous une présentation d'un objet tel qu'il apparaît dans la fenêtre graphique. Cette présentation précise les rôles des différents éléments constitutifs de cet objet.

Figure 8.21 : Objet Self expansé (1) (Duvall 1995)
"
Expanders"
Pour expanser ou restreindre la présentation des attributs de l'objet, on agit sur les points d'entrée définis :

Figure 8.22 : "
Expander" pour les méthodes


Figure 8.23 : "
Expander" pour les objets"
Evaluator"
Les évaluateurs constituent des zones d'édition qui permettent d'évaluer des expressions Self dans l'environnement particulier de l'objet.
L'objet associé à un évaluateur est le récepteur direct des messages adressés dans cette zone.
Accept
La validation de la zone
Accept via le bouton de gauche de la souris permet d'activer l'exécution des messages définis dans l'évaluateur.
Cancel
La validation de la zone
Cancel via le bouton de gauche de la souris permet de désactiver l'évaluateur.
Il est donc possible de visualiser, manipuler ou modifier les attributs des objets de la fenêtre graphique. Pour cela, on peut tout d'abord activer les "
slots expanders" pour avoir accès au contenu des attributs. On peut ensuite agir sur ces contenus.


Figure 8.24 : Objet Self expansé (2)
La figure qui suit présente:
l'objet
les objets expansés associés à certains attributs,
une description du code définissant des méthodes attachées à d'autres attributs.

Figure 8.25 : Objet Self expansé (3)
Incise 2. Manipulation et intervention directes sur les objets avec Self
L'utilisateur constitue à lui tout seul une "entité" de méta-contrôle indispensable pour évaluer les résultats construits. Il peut lui même être à l'origine de modifications sur les savoirs représentés. Pour cela il peut intervenir directement sur les objets via la fenêtre graphique de Self. Dans les figures 8.26 et 8.27, on réalise une mise à jour dynamique d'un attribut de l'objet présenté dans la fenêtre graphique : il s'agit du prototype lexical représentant le nom
lesion.

Figure 8.26 : Manipulation et modification directes d'objet (1)
On veut mettre à jour l'attribut
marque_nombre associé à l'objet nombre porté par l'attribut accord associé au prototype lexical. Pour réaliser cette mise à jour, on commence par associer à l'objet un évaluateur (en activant la souris sur cet objet) : cette interface permet de lui adresser directement des messages. Dans la figure 8.26, on trouve les valeurs initiales associées aux différents objets présentés ainsi que le message de mise à jour 'accord nombre marque_nombre : s' avant validation ('evaluate'). Dans la figure 8.27 on présente le résultat de la mise à jour précédente après la validation et la réussite de l'envoi du message.

Figure 8.27 : Manipulation et modification directes d'objet (2)
Dans les figures 8.28, 8.29, 8.30, on effectue une mise à jour dynamique de la méthode associée à l'attribut
addSemantique : on va donc modifier le code associé à l'écriture de cette méthode. Cette première figure présente la valeur initiale associée à cet attribut. En utilisant les menus accessibles sur l'attribut via la souris, on active la présentation de l'objet qui porte ce code initial, on active aussi l'affichage d'un éditeur qui permet d'accéder au code pour la mise à jour.

Figure 8.28 : Manipulation et modification directes d'objet (3)
Dans la figure 8.29, on effectue la mise à jour de l'attribut (la méthode)
addSemantique : ajout d'un affichage après la mise à jour de l'attribut semantique. Une confirmation est demandée pour valider cette mise à jour (un voyant vert (celui du haut) pour la valider, un voyant rouge pour l'annuler (<-"Accept, Cancel")). Si la mise à jour effectuée n'est pas syntaxiquement correcte, un objet portant un message d'erreur apparaît dans la fenêtre graphique et la mise à jour n'est pas enregistrée.

Figure 8.29 : Manipulation et modification directes d'objet (4)
Dans la figure 8.30, on trouve le résultat de la mise à jour réalisée et validée sur l'attribut (la méthode)
addSemantique.

Figure 8.30 : Manipulation et modification directes d'objet (5)
Incise 3.
Gaspar : un analyseur à mots implémenté avec Self-4.0
Nous présentons ici les outils mis en place pour l'implémentation de
Gaspar, l'analyseur chargé de construire les représentations des mots puis leur classement. L'implémentation s'inscrit dans le cadre défini par la version 4.0 du langage à prototypes Self. Elle étend donc les outils d'analyse déjà présentés.I.3.1. Catégorisation des outils pour l'analyse
L'analyseur
Gaspar est organisé de la manière suivante:
Gaspar
est un objet défini dans l'objet Self globals (un parent du lobby), il est donc accessible directement à partir du lobby (la "racine" du monde Self). Les différents outils définis ou à construire sont accessibles à partir de ce point d'entrée que constitue l'objet Gaspar. Tous les prototypes définis sous Gaspar sont donc des attributs définis dans cet objet ou dans ces sous-catégories. L'organisation des objets construits est présentée dans la figure qui suit.

Figure 31 :
Gaspar, un analyseur à prototypes
Chaque prototype dépendant de l'analyseur est catégorisé suivant son rôle dans l'"environnement" de cet analyseur. Les objets
traits définis pour les objets associés à Gaspar sont définis dans l'objet Self traits qui porte tous les comportements partagés. En utilisant l'interface graphique de Self, on peut inspecter l'objet Gaspar déclinant les différents niveaux de catégorisation présentés dans la figure précédente. Cette organisation initiale peut évidemment être modifiée: il est important de souligner qu'il est toujours possible avec Self de modifier dynamiquement et interactivement la structure des objets et donc aussi l'organisation des objets dans le monde Self.I.3.2. Interfaces disponibles
Pour accèder à
Gaspar et aux outils associés, des interfaces sont disponibles via les attributs menus définis par Gaspar. Ce dernier est le point d'entrée initial. On peut l'atteindre en chargeant le fichier initGaspar.self, ou en utilisant la syntaxe suivante:
gaspar menusGaspar menu
On peut ensuite atteindre les outils cherchés en sélectionnant une option parmi celles présentées.
Il est bien sûr indispensable d'activer cette option pour disposer des outils
Gaspar. On dispose pour le chargement des données d'une possibilité de chargement sélectif de celles-ci. De plus, on peut disposer ou non d'un lexique prédéfini ou de catégories déjà préconstruites.
L'analyseur syntaxique
Gaspar peut travailler en utilisant des savoirs préconstruits (<- partie 2 chapitres 5, 6) pour l'analyse (-> partie 3 chapitre 9 : présentation du parseur). Il peut aussi travailler à partir des savoirs associés aux mots construits dynamiquement par Gaspar (<- partie 2 chapitres 7, 8 : génération automatique de prototypes à partir de savoirs extraits sur corpus).
menu Define : outils Gaspar de génération et de classement
Ce menu regroupe les outils pour la génération dynamique des prototypes à partir de savoirs extraits sur corpus ainsi que les outils disponibles pour le classement des prototypes lexicaux et des prototypes d'arbre construits. D'autres outils sont également définis pour activer par exemple des opérations de substitution ou d'adjonction entre prototypes d'arbre.
Ce menu regroupe les outils qui permettent de lire les informations disponibles dans les différents dictionnaires définis par
Gaspar.
Ce menu regroupe les outils qui permettent d'inspecter (à un niveau méta) tous les objets générés dans l'environnement défini par
Gaspar et des outils qui permettent de modifier les liens entre ces objets (liens d'héritage en particulier) (-> chapitre 9). Ces outils utilisent la méta-représentation de structure définie par Self. L'objet metaGaspar est aussi l'objet initiateur des traçages potentiels de toutes les activités de Gaspar : on peut ainsi choisir de tracer les activités des différents processus définis (via l'interface graphique de Self et via la fenêtre shell), on peut en outre activer la présentation des objets construits ou sélectionnés dans la fenêtre graphique de Self. Il sera aussi capable de gérer les (méta)connaissances construites ou les évènements extérieurs qui interviennent dans les différentes phases de travail de Gaspar : ces options ne sont pas encore disponibles dans les résultats présentés ici (-> chapitre 9, -> annexe chapitre 9).
Ce menu regroupe les outils qui permettent de sélectionner le corpus de travail et d'activer certaines actions sur les corpus définis (recherche de chaîne textuelle ou de cooccurrences dans les corpus disponibles).
Ces différents outils sont accessibles dans l'environnement Self, il reste évidemment possible d'utiliser l'interface graphique de Self pour manipuler ou visualiser les différents objets construits. Il est d'ailleurs possible d'activer dans la fenêtre graphique les différents objets associés à
Gaspar via un menu desktop défini dans les menus construits. Ce dernier permet aussi l'ouverture et la fermeture de fenêtre(s) graphique(s).
Les outils d'interface construits constituent des raccourcis pour exécuter les différentes actions définies. Il est bien sûr plus facile de manipuler les objets individuellement via l'interface graphique. Pour visualiser par exemple les prototypes lexicaux ou syntaxiques construits dynamiquement par
Gaspar, il suffit de les activer à partir de l'objet Gaspar dans la fenêtre graphique: pour faire apparaître Gaspar dans cette fenêtre, il suffit d'évaluer le prototype Gaspar dans la fenêtre shell disponible dans cette interface graphique. On peut ensuite parcourir les sous-catégories de cet objet pour y découvrir les objets cherchés.
On donne dans la figure qui suit une illustration de l'environnement disponible avec la fenêtre graphique de Self. On trouve dans cette figure :
L'objet
La fenêtre
shell qui permet d'activer des opérations dans cette fenêtre graphique.
Les trois objets situés en bas et à droite sont des prototypes lexicaux ou d'arbres construits dynamiquement.
L'objet en haut et à droite est un attribut de l'objet
Gaspar qui contient tous les prototypes générés.
Et enfin, complètement à droite et en haut, la poubelle qui permet de nettoyer la fenêtre graphique.

Figure 32 :
Gaspar et l'interface graphique de Self
Incise 4. La classification évolutive est en marche
I.4. Des regards multiples sur les mots
La mise en oeuvre des processus de classement construits confirme les multiplicités de comportement possibles sur les mots. Comme on pouvait s'y attendre, on ne trouve jamais de comportement(s) partagé(s) par tous les membres d'une même famille catégorielle (<- expérimentations sur corpus). Il convient donc d'interroger les savoirs construits de manière plus fine si on veut y découvrir des similarités comportementales.
On donne ci-dessous une présentation détaillée des différentes opérations définies via Gaspar pour amorcer les classements des savoirs représentés.
I.4.1. Descriptif des opérations de classement réalisées
(1) Recherche sur tous les mots d'une même catégorie des comportements partagés (i.e. détermination des arbres propres à chacun d'eux)
Si tous les prototypes de mot d'une même catégorie partagent exactement les mêmes comportements, l'objet
traits qui portent les comportements partagés de cette catégorie est mis à jour : ilportera ces comportements communs. Dans tous les cas, les prototypes de mots portent quant à eux leurs comportements propres .
(2) Recherche sur tous les mots d'une même catégorie des comportements partagés (i.e. détermination des arbres propres à chacun d'eux) et pour toutes les catégories
Même opération que dans (1) sur toutes les catégories.
(3) Recherche des arbres élémentaires communs à deux prototypes (i.e. détermination des arbres propres à chacun d'eux)
Si deux prototypes de mot d'une même catégorie partagent un ou plusieurs comportements, un objet
traits est automatiquement construit pour porter ces comportements partagés. Dans ce cas on ajoute automatiquement aux prototypes concernés un attribut parent qui pointe sur ce nouvel objet porteur de comportements partagés. Les comportements propres à chacun des prototypes restent attachés à ces prototypes.

Figure 8.33 : Classement des mots deux à deux
Il est possible de réaliser ce type de recherche sur deux mots particuliers ou sur l'ensemble des mots (pris deux à deux et dans chaque catégorie). Dans la figure 8.18, on présente le résultat graphique obtenu sur la recherche de comportements partagés par deux prototypes de mot : il s'agit des deux prototypes associés aux mots
pontage et lésion (-> annexe partie 2 chapitre 8 : trace de la recherche des comportements partagés par ces deux mots). Après évaluation de leur(s) comportement(s) partagé(s), un attribut parental est automatiquement ajouté à ces deux prototypes (compShared_pontage_lesion*) qui pointe sur l'objet (présenté à droite dans la fenêtre graphique) portant le comportement commun (une liste portant un arbre élémentaire).

Figure 8.34 : Comportements partagés par deux mots
(4) Recherche sur des sous-familles de mots d'une même catégorie des comportements partagés et construction automatique d'un pôle de comportements partagés
Si plusieurs prototypes de mot d'une même catégorie partagent exactement les mêmes comportements, un objet
traits est automatiquement construit pour porter ces comportements partagés. Dans ce cas on ajoute automatiquement aux prototypes concernés un attribut parent qui pointe sur ce nouvel objet porteur de comportements partagés. Les comportements propres à chacun des prototypes restent attachés à ces prototypes.

Figure 8.35 : Classement des mots en sous-famille
Dans la figure précédente, les prototypes construits (représentant des noms) sont regroupés en sous-famille en tenant compte des arbres élémentaires associés à ces prototypes de mots. Les prototypes d'une sous-famille délèguent les mêmes arbres élémentaires à un ou plusieurs pôles de comportements partagés.
(5) Recherche sur des sous-familles de mots d'une même catégorie (et pour toute les catégories) des comportements partagés et construction d'un pôle de comportements partagés
Même opération que dans (4) sur toutes les catégories.
(6) Recherche sur des sous-familles d'arbres élémentaires d'une même catégorie des comportements partagés (arbres d'analyse) et construction d'un pôle de comportements partagés
Si plusieurs prototypes d'arbre élémentaire d'une même catégorie partagent exactement les mêmes comportements, un objet
traits est automatiquement construit pour porter ces comportements partagés. Dans ce cas on ajoute automatiquement aux prototypes concernés un attribut parent qui pointe sur ce nouvel objet porteur de comportements partagés. Les comportements propres à chacun des prototypes restent attachés à ces prototypes.

Figure 8.36 : Classement des arbres élémentaires
La détermination des comportements partagés par deux arbres élémentaires (à la manière de (3)) reste à faire.
On donne en annexe une trace de tous ces processus (-> annexe partie 2 chapitre 8).
I.4.2. Mise en place de réseaux de prototypes : autant de réseaux à interpréter
Le dispositif construit permet donc d'activer des processus de classement qui proposent des regards multiples et croisés sur les savoirs représentés. Ces processus construisent des réseaux de hiérarchies locales entre prototypes de mots et prototypes d'arbres ou entre prototypes d'arbres, ces liens multiples constituent autant de pistes de sens à interpréter.
Examen des comportements partagés sur des sous-familles de mots d'une famille catégorielle
A partir des prototypes de mot d'une même catégorie (en haut de la figure) on construit une première couche de pôles de comportements partagés par des sous-familles de prototypes (opération (4) décrite supra).
Examen des comportements partagés par les mots (deux à deux)
A partir de deux prototypes de mot d'une même catégorie, on peut aussi construire une seconde couche de pôles de comportements partagés par ces deux prototypes (opération (3) décrite supra).
Examen des comportements partagés par les arbres élémentaires
Enfin, à partir des prototypes d'arbre élémentaire d'une même catégorie (les ellipses noires ou fortement grisées de la figure) on construit une nouvelle couche de pôles de comportements partagés par des sous-familles de prototypes (opération (5) décrite supra).
Le schéma qui suit est une illustration simplifiée des réseaux mis en place.

Figure 8.37 : La classification évolutive est en marche
Incise 5. Approche d'un méta-protocole
I.5. Une approche expérimentale guidée par le méta-regard du linguiste
Les outils construits produisent des amorces de résultat qu'il convient d'affiner (Habert & al. 1996). Ils permettent en outre de guider la mise au point de nouveaux résultats : on peut à chaque étape examiner les résultats déjà établis pour ensuite soit sélectionner parmi les outils disponibles ceux qui permettent d'améliorer la qualité des résultats, soit agir directement sur les savoirs représentés pour les modifier ou pour les remodeler.
Ainsi la détermination d'un classement global des mots d'une catégorie sur la base des comportements partagés par l'ensemble de ces mots (opération (1) supra) nécessite à coup sûr un examen plus fin de ces mots et de leurs comportements respectifs si on veut y déceler des regroupements de comportements partagés sur des ensembles restreints de mots.
La mise en place de regards croisés sur les savoirs représentés dépend donc directement du méta-regard de l'utilisateur sur les résultats qu'il génère en activant les outils définis : le méta-regard de l'utilisateur et ses interventions guident le travail d'affinement des résultats construits et leur interprétation (<- incise 4).
I.5.1. Du méta-regard à l'automodification
Le système Gaspar active plusieurs niveaux de représentation pour évaluer les savoirs manipulés :
1 Les programmes construits utilisent des méta-processus (-> partie 3 chapitre 9) capables d'évaluer la structure interne des objets construits. On peut vouloir sélectionner et rechercher parmi tous les objets disponibles un objet particulier avec un type donné d'attribut. Pour réaliser ce type d'opérations, on utilise des méta-processus capables de lire la structure des objets (-> partie 3 chapitre 9), et on récupère l'objet adéquat. Les programmes construits utilisent ce type de processus pour, par exemple, modifier dynamiquement des liens de délégation. On dispose aussi d'outils capables de supprimer les liens de délégation de même nature (i.e. les mêmes comportements étant portés par deux ou plusieurs pôles différents). Ces opérations, intégrées au programme construit restent évidemment transparentes pour l'utilisateur.
Le point important à souligner dans cette phase de développement de notre analyseur est que les méta-processus disponibles avec Self ont été généralisés dans toutes les phases de travail qu'il est possible d'activer via Gaspar. On a vu supra qu'il existait désormais une interface particulière dans Gaspar pour activer ce genre des outils. Ces derniers, activables par l'utilisateur, permettent un méta-regard sur les objets construits et des actions qui se réalisent en utilisant les méta-processus disponibles avec Self.
Ce méta-niveau reste principalement capable d'évaluer la définition structurelle des objets et d'agir sur elle : il n'est en aucun cas capable d'interpréter les méta-opérations réalisées. Ce premier type d'automodification des représentations construites reste donc limité à la structure interne des objets portant les savoirs représentés.
2 L'utilisateur constitue à lui tout seul une "entité" de méta-contrôle indispensable pour évaluer les résultats construits. C'est à lui d'interpréter et d'évaluer toutes les mises à jour réalisées : il peut d'ailleurs lui-même être à l'origine de modifications sur les savoirs représentés. Ce sont les outils construits à partir des fonctionnalités de Self (primitives du langage) qui permettent à l'utilisateur d'évaluer les objets construits.
Puisque l'utilisateur joue un rôle central dans notre approche expérimentale, il est important de souligner que si l'on veut qu'il soit capable d'intervenir pour évaluer ou modifier les objets ou les résultats construits, il doit pouvoir suivre pas à pas les différentes opérations réalisées par les programmes construits et évaluer les changements d'états des objets manipulés (Habert & Fleury 1993a, 1993b). Il est donc impératif de disposer de processus de traçage de toutes ces opérations. Nous avons déjà indiqué et nous le reverrons infra (-> partie 3 chapitre 9) que les processus mis en place via Gaspar permettent d'activer à tout moment de tels processus de traçage qui présentent les différents états pertinents des traitements réalisés et des résultats construits à chaque étape.
I.5.2. Limites actuelles des méta-processus
Tous les méta-processus définis n'agissent en fait que de manière structurelle par rapport aux objets construits. Ils permettent soit d'ajouter un comportement, soit de retirer un comportement, soit enfin de modifier globalement un comportement. En effet, si on veut affiner un comportement dans un programme et de manière transparente pour l'utilisateur, il est nécessaire de le redéfinir complètement. Les processus disponibles ne sont pas encore capables de modifier partiellement la valeur d'un attribut, et notamment des attributs qui portent des procédures. Si l'on doit modifier ce type d'attribut de manière transparente pour l'utilisateur (et sans passer par l'interface graphique), il convient de modifier globalement la valeur de cet attribut i.e réécrire le code associé et le réaffecter à l'attribut visé. Si l'utilisateur peut intervenir dynamiquement et de manière interactive sur tous les objets construits en utilisant l'interface graphique de Self , il reste important de souligner qu'à moins de connaître toutes les finesses de la programmation avec Self, il reste difficile à un utilisateur non spécialiste de ce langage de gérer tout seul ce type de mise à jour.
La mise au point de tels outils de mise à jour dynamique et ponctuelle des objets construits est d'ailleurs loin d'être triviale (Cointe & al. 1993, Cointe & al. 1995) (-> partie 3 chapitre 9 : réflexivité comportementale).