L'environnement de travail contient plusieurs dossiers.
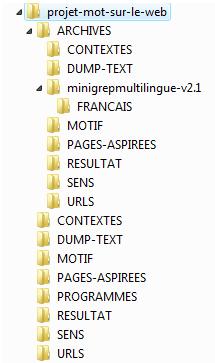
URLS/
Contient des fichiers au format 'langue'_'numéro sens'.txt. Chaque url est écrit à la ligne dans un fichier correspondant à une langue et au même sens.SENS/
Les différents sens sont aussi indiqué à la ligne dans un fichier au format 'langue'.txt. Le numéro du sens est le même que le numéro de la ligne sur laquelle il est écrit dans le fichier.RESULTAT/
Ici se trouve un fichier html avec toutes les sorties du script.PROGRAMMES/
Le fichier final.sh est le script de l'examen du mot. L'exécution doit se faire après le positionnement dans ce dossier PROGRAMMES.PAGES-ASPIREES/
Les pages aspirées après l'application de wget. Lors de l'exécution du script, si l'utilisateur ne désire pas enregistrer à nouveau les pages du web, les pages aspirées sont copiées dans ce répertoire à partir d'ARCHIVES.MOTIF/
Contient deux fichiers au format 'langue'.txt pour chaque des motif de recherche dans les contextes selon la langue. Ce motif est transmit au programme minigrepmultilingue qui fait l'extraction. Dans le fichier 'langue'.txt doit figurer seulement une ligne qui commence par 'MOTIF=' et suivi par le mot à chercher dans les contextes extraits des pages web. Dans le cas, le mot est 'boîte' en français et 'кутия' pour le bulgare.DUMP-TEXT/
Contient des fichiers au format 'langue'_'numéro du sens'_'numéro identifiant de la page'.txt. Ces fichiers sont le résultat de l'application de lynx sur les pages aspirées dans le but d'enlever les lignes de code html du contexte simple du mot étudié.CONTEXTES/
Contient des fichiers dans le format:
'langue'_'sens'_numéro fichier'.html.
Ces fichiers fournissent le
contexte du mot à partir des pages web, ce ne sont que quelques
lignes autour du mot "boîte". Ils sont le résultats de
l'application du programme minigrepmultilingue.
ARCHIVES/
Sert à restaurer, si nécessaire, les répertoires avec le motif d'extraction du contexte de "boîte", les urls des pages examinées, les fichiers contenant les différents sens de "boîte" par langue, les pages préalablement aspirées. C'est ici qu'il faux modifier les fichiers textes, si on veut changer le motif d'extraction, le corpus d'urls et le sens du mot étudié. Petite recommandation – s'il faut changer les données de départ, il vaut mieux copier tous les répertoires de ARCHIVES, sauf minigrepmultilingue-v2.1. Ce programme est en deux version. Une pour le français, parce que le code de la version originale est un peu modifié pour le faire marcher avec des symboles diacritiques comme '^'. Et une version standard qui fonctionne avec le cyrillique. C'est pourquoi existe un sous-répertoire avec la version pour le français