Etiquetage morpho-syntaxique
Cette procédure consiste à associer une étiquette morpho-syntaxique à chaque mot. Dans un premier temps les textes doivent être segmentés en mots et en phrases. Ensuite, on effectue la lemmatisation, c'est-à-dire l'association d'un "lemme" à chacun de ces mots.
Cette partie est dédiée à l'etiquetage morpho-syntaxique des mots qui s'effectue sur les fichiers texte obtenus précédemment. Pour ce faire, on utilise deux méthodes différentes:
Etiquetage avec TreeTagger : TreeTagger est un outil qui permet d'annoter un texte en ajoutant des informations sur les parties du discours et des lemmes.
TreeTagger permet l'étiquetage de plusieurs langues, parmi lesquelles l'allemand, l'anglais, les principales langues romanes, le bulgare, le russe, le grec, le chinois, etc. et aussi des textes en ancien français. Il peut être adapté à d'autres langues à condition que des corpus étiquetés manuellement en ces langues soient disponibles.
Même si ce outil ne possède pas une interface graphique, il est facile à utiliser, soit directement sur la "ligne de commande", soit en faisant appel à lui dans un script perl.
Etiquetage en Cordial : Cordial est un programme payant, très coûteux. Il a l'avantage d'inclure une interface graphique propre mais il ne peut être utilisé que sous Windows.
Outre les fonctionalités d'analyse syntaxique et sémantique des phrases et les fonctions de correction gramaticale et orthographique, Cordial dispose aussi d'une fonction d'étiquetage morphosyntaxique qui donne des résultats plus raffinés que ceux de Treetagger. Il prend en entrée du texte brut et fournit en sortie un fichier format (.cnr) étiquaté sur trois colonnes: la forme | le lemme | la catégorie grammaticale.
Treetagger
On reprend le script initial de BAO1 (méthode à la loyale) et on rajoute le code pour le traitement en Treetagger:
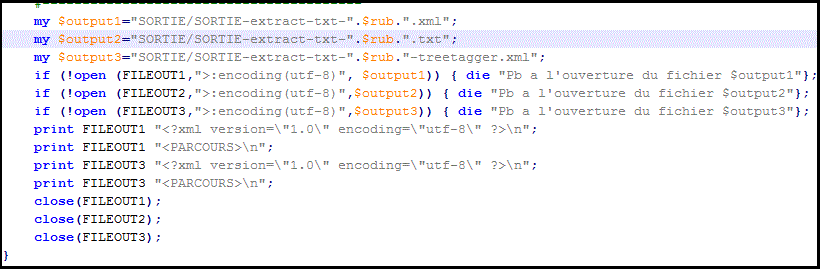
On configure une nouvelle sortie format xml treetagger comme suit:
my $output3="SORTIE/SORTIE-extract-txt-".$rub."-treetagger.xml";
if (!open (FILEOUT3,">:encoding(utf-8)",$output3)) { die "Pb a l'ouverture du fichier $output3"};
close(FILEOUT3);
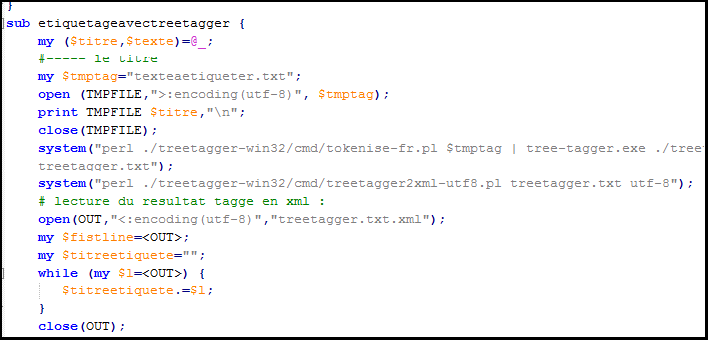
On fait appel au programme Treetagger:
Le mode d'emploi est: tree-tagger [options]
Le 1er argument est le script tokenise-fr.pl qui retourne une sortie avec un mot par ligne
Le 2ème argument est le fichier french-utf8.par
On utilise plusieurs options:
-token (retourner le token), -lemma (retourner le lemme de chaque token), -no-unknown (ne pas etiqueter au moment où la catégorie n'est pas reconnue.
Dans notre sous-programme marqué par la syntaxe [sub etiquetageavectreetagger] on utilisé un script intitulé treetagger2xml-utf8.pl qui transforme la sortie de Treetagger au format XML. Enfin, on relance le traitement décrit ci-dessus pour le texte ($texte) aussi.
Téléchargement du script ici.
Téléchargement des résultats ici.
Cordial
Le script utilisé en BAO1 est rélancé une deuxième fois, après avoir rajouté les parties concernant le traitement en Treetagger. Les sorties résultantes, en format texte brut, serviront comme input pour le traitement en Cordial.
Une étape de prétraitement est nécessaire, car l'encodage des fichiers texte est utf8 (nous l'avons transformé dans la partie BAO1). On rechange alors l'encodage de chaque fichier en iso-8859-1, car c'est le seul encodage accepté par Cordial. Une fois les fichiers texte recodés, on passe à l'etiquetage morpho-syntaxique.
L'etiquetage se fait simplement, d'après les paramètres que nous avons cochés selon notre intérêt, comme on peut le voir sur l'image suivante:
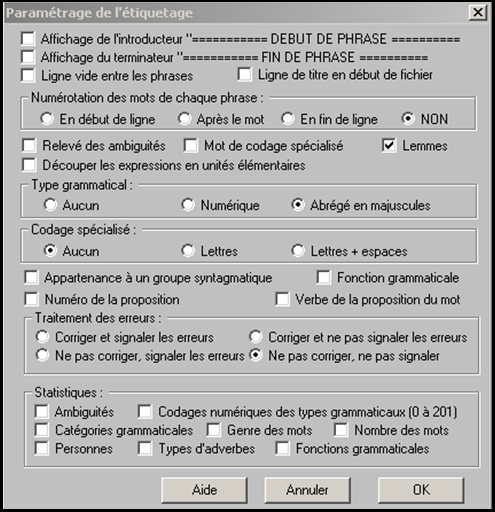
Les fichiers obtenus sont au format cordial (cnr).
Téléchargement des résultats ici.