Documents Structurés
Site réalisé dans le cadre du cours de Documents Structurés par Kelly MASCLEF et Julie SAUVAGE.
Visiter le site
Site réalisé dans le cadre du cours de Documents Structurés par Kelly MASCLEF et Julie SAUVAGE.
Visiter le site
Programmation et Projet Encadré 1 du Semestre 1 par Kelly MASCLEF et Julie SAUVAGE (et avec Julie BELIAO).
Visiter le site
Programmation et Projet Encadré 1 du Semestre 1 par Ilaria TIDDI (avec Marcelo MATOSO et Camille DOUDANE).
Visiter le site



Dans le cadre de ce projet, nous allons travailler à partir de fils RSS ( traduisez "Really Simple Syndication" ) tirés du site www.lemonde.fr durant les années 2009 et 2010. Ceci représente plusieurs centaines de méga de fichiers ! A travers les différentes boîtes à outils, nous allons vous montrer la démarche de notre travail.
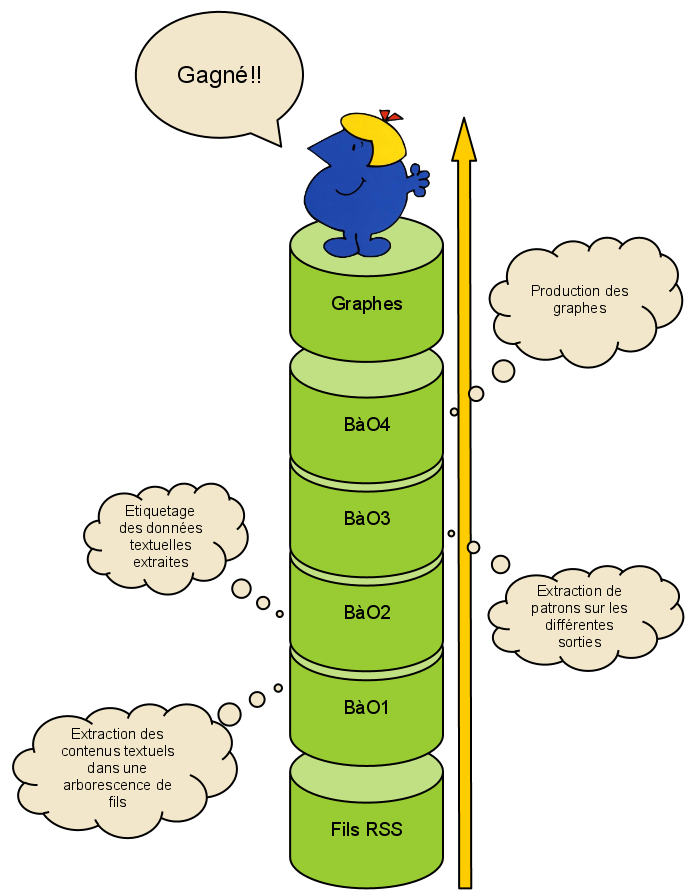
L'entrée pour cette partie du projet est un corpus constitué du contenu des fils RSS . Ces fils RSS sont eux-mêmes au format XML, ce qui est capital pour la suite du projet, vous allez le voir bien assez tôt. Le but de cette première boîte va être d'extraire les parties textuelles du corpus. Pour celà, nous avons utilisé plusieurs solutions :
Le but de cette boîte est de s'appuyer sur les contenus textuels extraits grâce à la boîte n°1 et de les étiqueter avec des étiquettes morpho-syntaxiques. Pour celà il existe deux éditeurs :
Dans cette boîte nous allons faire de l'extraction de patrons syntaxiques. Suivant l'étiqueteur que nous avons pris, le travail sera différent.
Dans cette dernière boîte à outils, nous allons produire, à partir des patrons syntaxiques extraits, des graphes permettant de mettre en valeur les relations entretenues par les différents éléments.
Vous trouverez les archives des scripts ainsi que des résultats en cliquant sur le lien "Scripts" en bas de page.