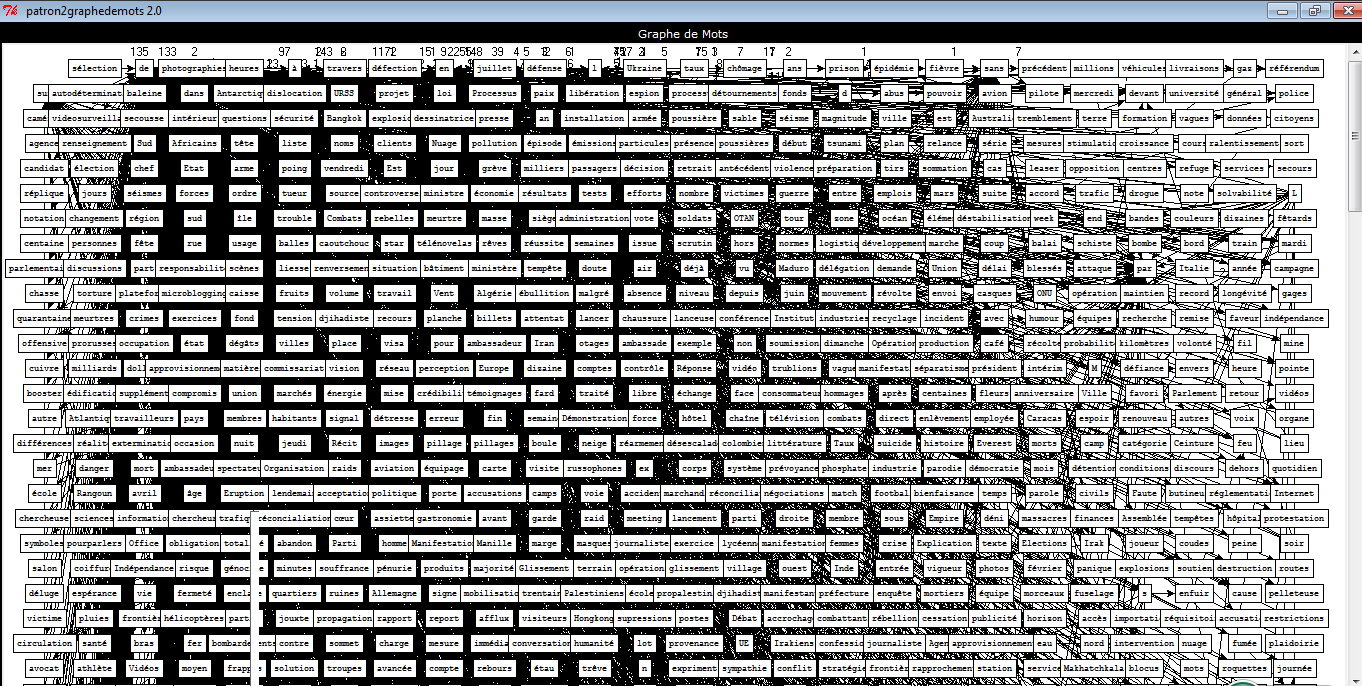
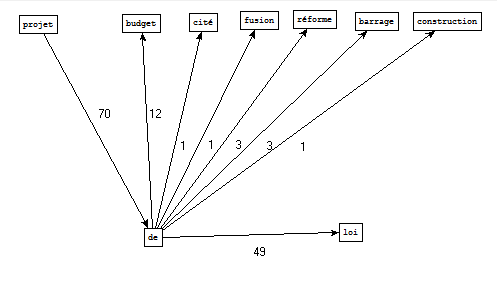
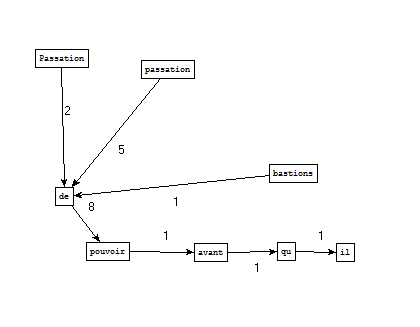
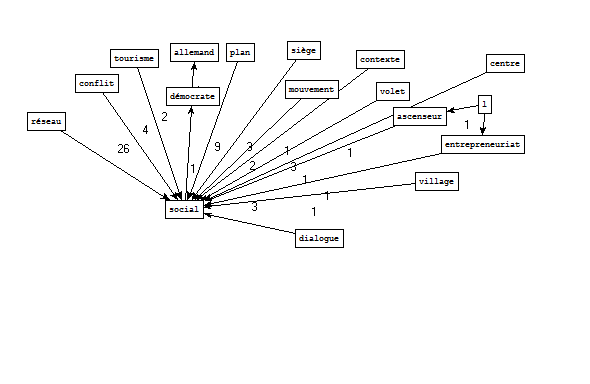
Bao1 Filtrage et nettoyage
Le corpus du projet Boîte à outils est composé par les fichiers de flux RSS du journal Le Monde de de l'année 2014.
Tous les fichiers à traiter sont sous forme XML. On extrait le contenu balisé en «title » et en « description » qui continent le titre et le résumé de chaque nouvelle article.
Les fichiers XML sont nommés par les numéros qui représentent les rubriques correspondants.
Dans cette tâche, il s’agit d’abord de parcourir le répertoire de corpus et de lire les fichiers XML , ensuite on fait l’extraction de contenu textuel de <title> et de <description>, et finalement on le sauvegarde dans un fichier texte et un fichier XML.
On a utilisé un script perl pour réaliser cette tâche. Concernant les méthode, ici nous allons en présenter deux : une méthode d’expression régulière et une autre méthode qui utilise la bibliothèque de « XML ::lib ».
A. La méthode d'expression régulière :
Le programme principal
01 #!/usr/bin/perl
02 <<DOC;
03 Votre Nom : Chunxiao YAN
04 mars 2015
05 usage : perl 2015BAO1exrg.pl repertoire-a-parcourir repertoire-de-sortie
06 DOC
07
08 use Unicode::String qw(utf8);
09
10 #----------------------bon script par rub ----------------------------------------
11 my $rep="$ARGV[0]";
12 $rep=~ s/[\/]$//;
13
14 my $repsortie=$ARGV[1];
15 print $repsortie;
16 mkdir($repsortie) or die ("Probleme avec la creation du repertoire de $repsortie, verifier s'il en existe deja une");
17
18 my %dicTitle=();
19 my %dicDescription=();
20 my %dicrubriques=();
21 #----------------------------------------
22 &parcoursarborescencefichiers($rep); # traitement de tous les fichiers
23
24 opendir(DIR, $repsortie) or die "probleme d'ouverture de repertoire: $!\n";
25 my @listefichiers = readdir(DIR);
26 closedir(DIR);
27 foreach my $fichier (@listefichiers) {
28 if ($fichier=~/\.xml$/) {
29 if (!open (FILE,">>:encoding(utf-8)",$repsortie."\\".$fichier)) { die "Pb a l'ouverture du fichier $output1"};
30 print FILE "</PARCOURS>\n";
31 close(FILE);
32 }
33 }
34 exit;
Ce programme principal prend deux arguments en entrée:
perl scriptbao1.pl répertoire-de-corpus répertoire-de-sortie
Ensuite trois tables de hachage sont établis :
my %dicTitle=();
my %dicDescription=();
my %dicrubriques=();
La fonction de parcoursarborescencefichiers($rep) parcours le répertoire du corpus , extrait le contenu de <title> et de <description> dans les fichiers XML de RSS, nettoie les données et les sauvegarde dans les fichiers textes et les fichiers XML classés par rubrique.
Finalement, on parcours le répertoire de sortie et écrit la balise de fin </parcours> dans tous les fichiers sorties en XML qu’on a créé au cours d’exécution de la fonction parcoursarborescencefichiers($rep).
Les fonctions :
01 sub parcoursarborescencefichiers {
02 my $path = shift(@_);
03 opendir(DIR, $path) or die "can't open $path: $!\n";
04 my @files = readdir(DIR);
05 closedir(DIR);
06 foreach my $file (@files) {
07 next if $file =~ /^\.\.?$/;
08 $file = $path."/".$file;
09
10 if (-d $file) {
11 &parcoursarborescencefichiers($file); #recurse!
12 print "je rentre dans $file \n ";
13 #my $attente=<STDIN>;
14 }
15
16 if (-f $file) {
17 print "Traitement de : $file\n";
18 #print OUT "$file\n";
19 if (($file=~/\.xml$/) && ($file!~/\/fil.+\.xml$/)){
20 open(FILE,$file);
21 $ligne=<FILE>;
22 print $file;
23 close(FILE);
24 #----------------------detecte encodqge--------------------------------
25 $ligne =~/encoding=[\'\"]([^\'\"]+)[\'\"]/i;
26
27 my $encodage = $1;
28 print "ENCODAGE : $encodage\n";
29 #----------------------------------------------------------------------
30 open (FILE,"<:encoding($encodage)",$file);
31 $chainecomplete = "";
32 while ($ligne=<FILE>) {
33 chomp $ligne;
34 $chainecomplete = $chainecomplete . " " . $ligne;
35 }
36 $chainecomplete=~s/> +</></g;
37 #-------------------traitement de fichier rubrique---------------------------------------
38 if ($encodage ne "") {
39 print "Extraction dans : $file \n";
40 my $tmptexteXML="<file>\n";
41 $tmptexteXML.="<name>$file</name>\n";
42 $chainecomplete=~/<pubDate>([^<]+)<\/pubDate>/;
43 $tmptexteXML.="<date>$1</date>\n";
44 $tmptexteXML.="<items>\n";
45 my $tmptexteBRUT="";
46 # on recherche la rubrique
47 $chainecomplete=~/<channel>.*?<title>([^<]+)<\/title>/;
48 my $rub=$1;
49 $rub=&nettoyagerub($rub);
50 print "RUBRIQUE : $rub\n";
51 #---------------------------------------------------------------------------------------------------
52 my $output1=$repsortie."/SORTIE-extract-txt-".$rub.".xml";
53 my $output2=$repsortie."/SORTIE-extract-txt-".$rub.".txt";
54 if ( -e $output1) {
55 print "exsite: $rub";
56 }
57 else {
58 &fichiersortie($rub);
59 }
60 if (!open (FILEOUT1,">>:encoding(utf-8)", $output1)) { die "Pb a l'ouverture du fichier $output1"};
61 if (!open (FILEOUT2,">>:encoding(utf-8)", $output2)) { die "Pb a l'ouverture du fichier $output2"};
Dans cette partie, le programme parcours le répertoire du corpus et détecte les fichiers .xml de flux RSS, une fois le fichier .xml trouvé, on commence à traiter le fichier.
- 1. Lire le fichier ligne par ligne et extrait son encodage (19-29)
- 2. Concaténer tous les lignes dans le fichier et le mettre dans la variable $chainecomplete (30-36)
- 3. Créer deux variables :$tmptexteXML et $tmptexteBRUT destinées à l'écriture du fichier sortie en xml et en texte brut (38-45)
- 4. Trouver la rubrique du fichier et nettoyer le $rub (47-50)
- 5. Créer les fichiers de sortie en rubrique en vérifiant son existence: if ( -e $output1), si le fichier existe, le programme passe à la mode d’écriture de données dans le fichier,sinon en utilisant la fonction fichiersortie($rub) on crée ce fichier de sortie de rubrique. (51-61)
01 #----------------------------------------------------------------------------------------------------
02 my $cpt=0;
03
04
05 #----------------------------------------------
06 while ($chainecomplete=~/<item><title>([^<]*)<\/title>.*?<description>([^<]*)<\/description>/g) {
07 my $title=$1;
08 my $description=$2;
09 if (uc($encodage) ne "UTF8") {
10 print "changement en utf8\n";
11 utf8($title);
12 utf8($description);
13 }
14 if (!(exists $dicTitle{$title})){
15 $cpt++;
16 $dicTitle{$title}++;
17 $dicDescription{$description}++;
18
19 #--------------nettoyage-------------------
20 print "nettoyage";
21 $title=&nettoyage($title);
22 $description=&nettoyage($description);
23
24 $tmptexteBRUT.="§$title \n";
25 $tmptexteBRUT.="$description \n";
26 $tmptexteXML.="<item num=\"$cpt\"><title>$title</title><abstract>$description</abstract></item>\n";
27 }
28 else {
29 $tmptexteXML.="<item><title>-</title><abstract>-</abstract></item>\n";
30 print "doublons";
31 }
32 }
33 $tmptexteXML.="</items>\n</file>\n";
34 print FILEOUT1 $tmptexteXML;
35 print FILEOUT2 $tmptexteBRUT;
36 close FILEOUT1;
37 close FILEOUT2;
38 }
39 else {
40 print "$file ==> $encodage \n";
41 }
42 }
43 }
44
45 }
46 }
Avec l’expression régulière , on arrive à extraire le $title et le $description.Puis on le transcode en utf-8 si les données ne sont pas en utf-8. Le deuxième « if » sert à supprimer les doublons à l’aide de la vérification dans les dictionnaires qu’on a créé au début de programme.Après avoir nettoyé le $title et le $description, on les écrit dans les fichiers xml et les fichiers en texte brut.
Nous avons un compteur $cpt qui compte le nombre de «item » qu’on a traité dont les doublons sont exclus.
La variable $tmptexteBRUT et la variable $tmptexteXML permettent de concaténer tous les items extraits et de faciliter l’écritures du fichier de sortie.
Les autres fonctions :
Fonction de création des fichiers de sortie
01 sub fichiersortie {
02 my $rub=shift(@_);
03 my $output1=$repsortie."/SORTIE-extract-txt-".$rub.".xml";
04 my $output2=$repsortie."/SORTIE-extract-txt-".$rub.".txt";
05 if (!open (FILEOUT1,">:encoding(utf-8)", $output1)) { die "Pb a l'ouverture du fichier $output1"};
06 if (!open (FILEOUT2,">:encoding(utf-8)",$output2)) { die "Pb a l'ouverture du fichier $output2"};
07 print FILEOUT1 "<?xml version=\"1.0\" encoding=\"utf-8\" ?>\n";
08 print FILEOUT1 "<PARCOURS>\n";
09 print FILEOUT1 "<NOM>Chunxiao YAN 2015</NOM>\n";
10 close(FILEOUT1);
11 close(FILEOUT2);
12
13 }
Fonctions de nettoyage
01 sub nettoyage {
02 my $chainetrouvee=shift(@_);
03 $chainetrouvee=~s/&#39;/'/g;
04 $chainetrouvee=~s/&#34;/"/g;
05 $chainetrouvee=~s/'/'/g;
06 $chainetrouvee=~s/"/"/g;
07 $chainetrouvee=~s/é/é/g;
08 $chainetrouvee=~s/ê/ê/g;
09 $chainetrouvee=~s/<.*?>//g;
10 return $chainetrouvee;
11 }
12
13 sub nettoyagerub {
14 my $rub=shift(@_);
15 $rub=~ s/Le ?Monde.fr ?://g;
16 $rub=~s/ ?: ?Toute l'actualité sur Le Monde.fr.//g;
17 $rub=~s/\x{E8}/e/g;
18 $rub=~s/\x{E0}/a/g;
19 $rub=~s/\x{E9}/e/g;
20 $rub=~s/\x{C9}/e/g;
21 $rub=~s/ //g;
22 $rub=uc($rub); # mise en majuscules
23 $rub=~s/-LEMONDE.FR//g;
24 $rub=~s/:TOUTEL'ACTUALITESURLEMONDE.FR.//g;
25 $rub=~s/LEMONDE.FR-ACTUALITE//g;
26 return $rub
27 }
B. La méthode de XML::RSS
Tout d'abord, il faut importer la bibliothèque de XML ::RSS.
use strict;
use Unicode::String qw(utf8);
use XML::RSS;
Le programme principal est identique avec celui de la méthode d’expression régulière.
Dans la fonction de « parcoursarborescencefichier », après avoir détecté le fichier de traitement, au lieu de concaténer les lignes dans le fichier, on lance un passeur XML-RSS qui transforme le document en un tableau qui contient l’élément et son contenu textuel.
01 if ($encodage ne "") {
02 #------------------module xml rss--------------------------------------------------------
03 my $rss=new XML::RSS;
04 eval {$rss->parsefile($file); };
05 if( $@ ) {
06 $@ =~ s/at \/.*?$//s;
07 print STDERR "\nERROR in '$file':\n$@\n";
08 }
09 $rss->parsefile($file);
10 print "Extraction dans : $file \n";
11 my $canal = $rss->{'channel'};
12 my $rub=$canal->{'title'};
13 $rub=&nettoyagerub($rub);
14 print "RUBRIQUE : $rub\n";
De cette façons, on arrive à obtenir non seulement le $rub, mais aussi le $title et le $description:
1 foreach my $item (@{$rss->{'items'}}) {
2 my $description=$item->{'description'};
3 my $title = $item->{'title'};
Les fichiers de sortie
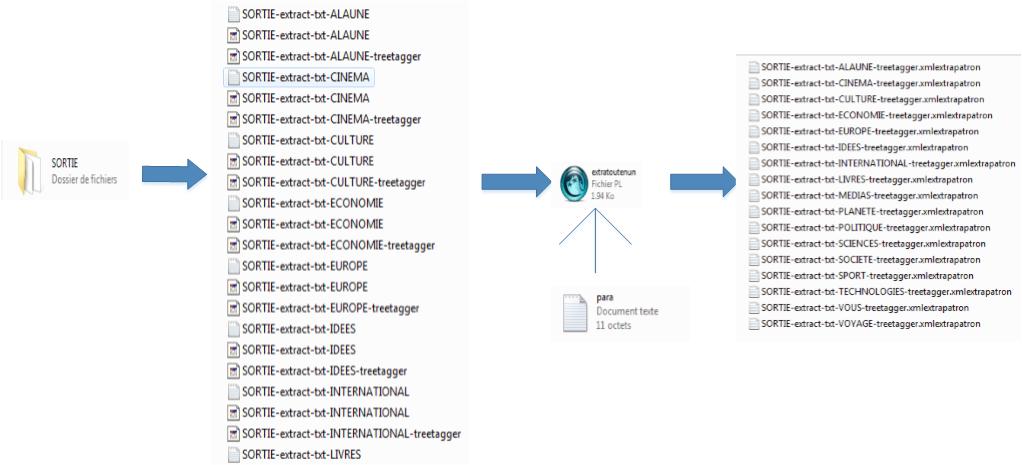
après l'exécution du programme, on obtient un fichier de texte et un fichier d'XML pour chaque rubrique.
Voici un exemple de fichier .txt (une partie dans fichier "SORTIE-extract-txt-ALAUNE.txt")
§ Marchés financiers : le scandale du Forex s'étend à Hongkong
Les autorités bancaires allemande, américaine, britannique, singapourienne et suisse ont ouvert parallèlement des enquêtes sur ce scandale où des traders auraient réussi à fausser l'indice qui détermine le cours des devises.
§ Centrafrique : l'UE lance sa propre opération militaire
« La force comprendra jusqu'à 1 000 soldats, dirigés par le général de division Philippe Pontiès », a précisé dans un communiqué le Conseil de l'Europe
§ Bambi menacé par le réchauffement climatique
Des chercheurs du CNRS et de l'Office national de la chasse et de la faune sauvage ont établi un lien entre avancée du printemps et surmortalité des faons.
§ Un homme retranché chez lui à Antony, le RER B arrêté
L'homme a tiré un coup de feu en l'air puis s'est retranché seul dans son appartement situé près des voies du RER B, dont la circulation a été interrompue.
§ Jacques Le Goff, mort d'un « ogre historien »
Le plus grand médiéviste français, Jacques Le Goff, est mort, mardi 1er avril, à l'âge de 90 ans à l'hôpital Saint-Louis.
§ Face au Bayern, Manchester United rêve de sauver sa saison
Distancée en championnat, l'équipe de David Moyes reçoit le Bayern Munich en quart de finale de la Ligue des champions. Manchester tentera de reproduire l'exploit de 1999 pour sauver sa saison.
§ Pour le 1er avril, Le Gorafi devient sérieux
Le site parodique a décidé de ne pas rigoler, en ce 1er avril, avec un éditorial tristement sérieux.
§ Un site de rencontre boycotte Firefox à cause des idées de son PDG
Le site américain de rencontres OK Cupid est inaccessible depuis lundi avec le navigateur Firefox, de Mozilla. Le site a voulu contester la récente nomination du nouveau PDG de Mozilla, qui est publiquement opposé au mariage entre personnes du même sexe.
§ Des vins animés : le chasselas suisse
A la découverte de ce cépage hélévète... en deux minutes chrono !
§ L'Unedic a versé 756 millions d'euros d'allocations chômage à tort en 2013
L'Unedic, qui gère les seules allocations chômage, estime que « le poids des indus rapportés aux dépenses d'indemnisation est resté stable, à 2,52 % »
§ Les idées iconoclastes de Valls au PS
Manuel Valls, nouveau premier ministre français, a longtemps cultivé une posture à part au sein de la gauche.
§ La police disperse des manifestants à Ankara
Plusieurs milliers de partisans du principal parti de l'opposition se sont réunis pour dénoncer des fraudes supposées à l'élection municipale à Ankara.
§ La Norvège reconduit son quota de baleines chassées
La Norvège a fixé à 1 286 le nombre de baleines susceptibles d'être harponnées dans ses eaux entre le 1er avril et le 30 septembre.
§ Comment s'est terminée la série « How I Met Your Mother » ?
Il est fortement recommandé d’être à jour pour lire cette note. Mais vous pouvez juste avoir envie de savoir la fin.
§ A Matignon, Valls veut « aller encore plus loin » et « plus vite »
Le désormais ex-premier ministre a mis en garde son successeur : « La tâche est immense. Ce que nous avons à faire est difficile et n'est pas terminé. »
§ Le frère de Mohamed Merah reste en détention
La cour d'appel de Paris a confirmé le maintien en détention d'Abdelkader Merah, mis en examen pour « complicité d'assassinat » dans l'enquête sur les crimes commis par son frère Mohamed Merah.
§ La grève à Saint-Lazare reconduite jusqu'à mercredi
La grève a commencé dimanche à l'appel du syndicat SUD-Rail qui conteste le projet de réorganisation des personnels d'aiguillage.
§ SNCM : l'actionnaire principal en négociation avec un groupe norvégien
Les syndicats ont dit avoir suspendu leur grève après avoir obtenu des garanties de l'actionnaire principal, Transdev, sur l'avenir de leur compagnie.
§ En direct : la passation de pouvoir à Matignon
La passation de pouvoir entre Jean-Marc Ayrault et Manuel Valls a lieu actuellement à Matignon.
§ Syrie : un bilan de « 150 000 morts » depuis trois ans
L'Observatoire syrien des droits de l'homme annonce, mardi, que le nombre des victimes de la guerre en Syrie a dépassé les 150 000 morts depuis son déclenchement en mars 2011.
§ Procès Heaulme : l'ancien suspect Henri Leclaire ne se « rappelle de rien »
L'audition de ce témoin, ex-suspect du double meurtre de Montigny-lès-Metz, mis en cause par de nouveaux témoignages, est susceptible de faire basculer l'audience.
§ Sous tutelle, la fédération PS du Pas-de-Calais se rebelle
« C'est un acte de défiance ou de défi. On reprend notre autonomie, notre souveraineté sans demander la permission » à Solférino, a déclaré un dirigeant de la deuxième fédération socialiste de France.
§ Quand Manuel Valls se déclarait pour la GPA
Lors de la campagne des primaires socialistes, Manuel Valls prenait le contre-pied de son parti en défendant la gestation pour autrui.
§ Le Maroc renforce son dispositif sanitaire face au virus Ebola en Guinée
Le Maroc a annoncé mardi avoir renforcé son dispositif de contrôle sanitaire aux frontières, en particulier à l'aéroport de Casablanca, l'un des principaux hubs d'Afrique, en raison de l'importante épidémie de fièvre Ebola en Guinée.
§ Manuel Valls en cinq phrases choc
Du changement de nom du PS aux Roms en passant par les 35 heures, le nouveau premier ministre est un habitué des déclarations polémiques.
§ Un clan de yakuzas lance son site Internet
Etre yakuza ne fait plus envie. Alors que les effectifs sont en baisse régulière, un clan mise sur Internet pour redorer son image.
Voici un exemple du fichier de sortie d'XML (une partie dans fichier "SORTIE-extract-txt-ALAUNE.txt")
01 <?xml version="1.0" encoding="utf-8" ?>
02 <PARCOURS>
03 <NOM>Chunxiao YAN 2015</NOM>
04 <file>
05 <name>2014/Apr/01/19-00-00/0,2-3234,1-0,0.xml</name>
06 <date>Tue, 01 Apr 2014 16:33:45 GMT</date>
07 <items>
08 <item num="1"><title>Marks & Spencer continue son expansion à Paris</title><abstract>Marks & Spencer va ouvrir d'ici l'été cinq nouveaux magasins dans la capitale.</abstract></item>
09 <item num="2"><title>Les prix de l’électricité vont fortement grimper en 2014</title><abstract>Le Conseil d’Etat devrait exiger de l’exécutif que les tarifs régulés couvrent les coûts d’EDF.</abstract></item>
10 <item num="3"><title>Avec la crise, les porte-conteneurs se font refaire le nez</title><abstract>Pour utiliser moins de carburant, CMA-CGM et ses rivaux rabotent le bulbe de leurs navires.</abstract></item>
11 <item><title>-</title><abstract>-</abstract></item>
12 <item num="4"><title>Les ventes de voitures neuves en hausse en mars, le marché reste en crise</title><abstract>Les groupes français PSA et Renault tirent leur épingle du jeu, selon les chiffres des immatriculations publiés mardi.</abstract></item>
13 <item num="5"><title>Bouygues Telecom prolonge la durée de son offre pour SFR jusqu'au 25 avril</title><abstract>L'opérateur a informé Vivendi de cette extension qui vise à « procéder de façon sereine et approfondie à l'examen (…) que requiert une opération aussi importante ».</abstract></item>
14 <item num="6"><title>Ce qui change au 1er avril pour les familles</title><abstract>Hausse du minimum vieillesse, revalorisation du complément familial, baisse de l'allocation de base pour les parents de jeunes enfants aux revenus élevés, entrent en vigueur.</abstract></item>
15 <item num="7"><title>General Motors rappelle 1,5 million de véhicules supplémentaires</title><abstract>Ce nouveau rappel, trois jours après un autre de 1,6 million de véhicules, concerne principalement les Etats-Unis mais également le Canada et le Mexique.</abstract></item>
16 <item num="8"><title>Yahoo! en négociations pour un rachat dans la vidéo en ligne</title><abstract>Comme l'avait montré l'achat avorté de Dailymotion l'an dernier, le groupe internet américain souhaite mettre l'accent sur la vidéo pour relancer sa croissance.</abstract></item>
17 <item num="9"><title>Le salaire symbolique de Mark Zuckerberg, patron de Facebook</title><abstract>Le salaire de base d'un dollar de la 21e fortune mondiale est notamment complété par 653 164 dollars de rémunérations en nature.</abstract></item>
18 <item num="10"><title>« Non, Libé n’est pas sauvé ! »</title><abstract>Les représentants des salariés du journal restent très dubitatifs après les annonces de l'actionnaire Bruno Ledoux.</abstract></item>
19 <item><title>-</title><abstract>-</abstract></item>
20 <item num="11"><title>Immobilier : petits tracas et grosses galères de propriétaires</title><abstract>A la suite d’un appel à témoignage, une centaine de propriétaires nous ont raconté leur tracasseries quotidiennes. Nous publions ici les anecdotes les plus représentatives avec, à chaque fois, les conseils des juristes de l’Union nationale de la propriété immobilière (UNPI).</abstract></item>
21 <item num="12"><title>Rembourser un crédit de façon anticipée : ce qu'il faut savoir</title><abstract>Lorsqu'ils négocient leur crédit immobilier, très peu d'emprunteurs s'intéressent aux conditions de remboursement anticipé. Dommage, car cela leur permettrait de réaliser des économies, très peu d'emprunts allant jusqu'à leur terme.</abstract></item>
22 <item num="13"><title>La Redoute : 18 délégués CFDT quittent le syndicat</title><abstract>Les démissionnaires reprochent au syndicat d'avoir paraphé l'accord de la direction sur le plan social sans passer par un référendum.</abstract></item>
23 <item num="14"><title>La Poste doublement condamnée</title><abstract></abstract></item>
24 <item><title>-</title><abstract>-</abstract></item>
25 <item num="15"><title>Comment utilisez-vous les titres-restaurants ?</title><abstract>La possiblité d'avoir un titre-restaurant numérique, dont la mise en place entre en vigueur le 2 avril, vous paraît-elle intéressante ? Regretterez-vous de ne plus pouvoir donner les titres dont vous ne vous servez pas ?</abstract></item>
26 </items>
27 </file>
Exemple du fichier XML complet
Bao2 Etiquetage
L’objectif de cette étape est de segmenter les données qu’on a obtenues dans l’étape précédente, et d' identifier le lemme et la nature syntaxique de chaque mot. Deux méthodes nous aident à réaliser cette étape :
1. méthode automatique de programmation en utilisant Treetagger
2. méthode de logiciel Cordial qui est très performant sur l’annotation et des autres traitements du texte en français.
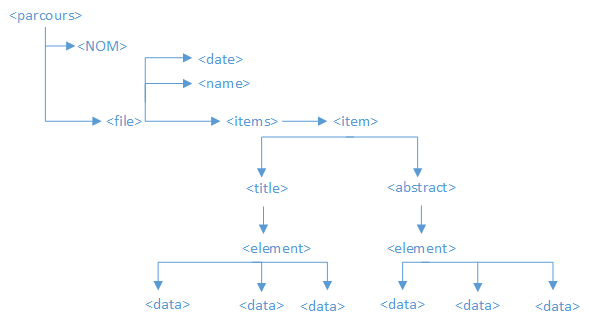
Ces deux méthodes produisent leurs données sous formes différentes. Avec méthode de Treetagger, nous obtient finalement un fichier xml dont les données sont structurées en arbre.
Avec méthode Cordia, on obtient un fichier .txt qui représente les données sous forme tabulaire.
D’ailleurs, la première méthode est une suite du script de BAO1 qui est capable de traiter des fichiers systématiquement. Avec le cordial, nous avons besoin de mettre un fichier .txt chaque fois pour obtenir son fichier de sortie.
Méthode de Treetagger
Nous n’avons qu’à rajouter :
1. La fonction d’étiquetage dans nos script de BAO1
2. Le troisième fichier de sortie ( my $output3=$repsortie."/SORTIE-extract-txt-".$rub."-treetagger.xml")
3. La ligne ($titletag,$descriptiontag)=&ettiquetage($title,$description); dans la fonction de parcoursarborescencefichiers($rep) pour étiqueter $title et $description
4. Les codes pour qu'on puisse mettre le $title et $description étiqueté dans le troisième fichier de sortie .
Fonction parcoursarborescencefichiers:
001 sub parcoursarborescencefichiers {
002 my $path = shift(@_);
003 opendir(DIR, $path) or die "can't open $path: $!\n";
004 my @files = readdir(DIR);
005 closedir(DIR);
006 foreach my $file (@files) {
007 next if $file =~ /^\.\.?$/;
008 $file = $path."/".$file;
009
010 if (-d $file) {
011 &parcoursarborescencefichiers($file); #recurse!
012 print "je rentre dans $file \n ";
013 #my $attente=<STDIN>;
014 }
015
016 if (-f $file) {
017 print "Traitement de : $file\n";
018 #print OUT "$file\n";
019 if (($file=~/\.xml$/) && ($file!~/\/fil.+\.xml$/)){
020 open(FILE,$file);
021 $ligne=<FILE>;
022 print $file;
023 close(FILE);
024 #----------------------detecte encodqge--------------------------------
025 $ligne =~/encoding=[\'\"]([^\'\"]+)[\'\"]/i;
026
027 my $encodage = $1;
028 print "ENCODAGE : $encodage\n";
029 #----------------------------------------------------------------------
030 open (FILE,"<:encoding($encodage)",$file);
031 $chainecomplete = "";
032 while ($ligne=<FILE>) {
033 chomp $ligne;
034 $chainecomplete = $chainecomplete . " " . $ligne;
035 }
036 $chainecomplete=~s/> +</></g;
037 #-------------------traitement de fichier rubrique---------------------------------------
038 if ($encodage ne "") {
039 print "Extraction dans : $file \n";
040 my $tmptexteXML="<file>\n";
041 $tmptexteXML.="<name>$file</name>\n";
042 $chainecomplete=~/<pubDate>([^<]+)<\/pubDate>/;
043 $tmptexteXML.="<date>$1</date>\n";
044 $tmptexteXML.="<items>\n";
045
046 my $tmptexteXMLtagger="<file>\n";
047 $tmptexteXMLtagger.="<name>$file</name>\n";
048 $tmptexteXMLtagger.="<date>$1</date>\n";
049 $tmptexteXMLtagger.="<items>\n";
050
051 my $tmptexteBRUT="";
052 open(FILE,"<:encoding($encodage)", $file);
053
054 #print "Traitement de :\n$file\n";
055 $chainecomplete="";
056 while ($ligne=<FILE>) {
057 chomp $ligne;
058 $chainecomplete = $chainecomplete . " " . $ligne;
059 }
060
061 close(FILE);
062 $chainecomplete=~s/> *</></g;
063 # on recherche la rubrique
064 $chainecomplete=~/<channel>.*?<title>([^<]+)<\/title>/;
065 my $rub=$1;
066 $rub=&nettoyagerub($rub);
067 print "RUBRIQUE : $rub\n";
068 #---------------------------------------------------------------------------------------------------
069 my $output1=$repsortie."/SORTIE-extract-txt-".$rub.".xml";
070 my $output2=$repsortie."/SORTIE-extract-txt-".$rub.".txt";
071 my $output3=$repsortie."/SORTIE-extract-txt-".$rub."-treetagger.xml";
072 if ( -e $output1) {
073 print "exsite: $rub";
074 }
075 else {
076 &fichiersortie($rub);
077 }
078 if (!open (FILEOUT1,">>:encoding(utf-8)", $output1)) { die "Pb a l'ouverture du fichier $output1"};
079 if (!open (FILEOUT2,">>:encoding(utf-8)", $output2)) { die "Pb a l'ouverture du fichier $output2"};
080 if (!open (FILEOUT3,">>:encoding(utf-8)", $output3)) { die "Pb a l'ouverture du fichier $output3"};
081 #----------------------------------------------------------------------------------------------------
082 my $cpt=0;
083 my $compteurEtiquetage=0;
084
085 #----------------------------------------------
086 while ($chainecomplete=~/<item><title>([^<]*)<\/title>.*?<description>([^<]*)<\/description>/g) {
087 my $title=$1;
088 my $description=$2;
089 if (uc($encodage) ne "UTF8") {
090 print "changement en utf8\n";
091 utf8($title);
092 utf8($description);
093 }
094 if (!(exists $dicTitle{$title})){
095 $cpt++;
096 $dicTitle{$title}++;
097 $dicDescription{$description}++;
098 $compteurEtiquetage++;
099 #--------------nettoyage-------------------
100 print "nettoyage";
101 $title=&nettoyage($title);
102 $description=&nettoyage($description);
103 print "ettiquetage";
104 #----------ettiquetage de titre et de decscription------------------
105 ($titletag,$descriptiontag)=&ettiquetage($title,$description);
106 #-------------------------------------------------
107 $tmptexteBRUT.="?$title \n";
108 $tmptexteBRUT.="$description \n";
109 $tmptexteXML.="<item num=\"$cpt\"><title>$title</title><abstract>$description</abstract></item>\n";
110 $tmptexteXMLtagger.="<item num=\"$cpt\">\n<title>\n$titletag</title>\n<abstract>\n$descriptiontag</abstract>\n</item>\n";
111 }
112 else {
113 $tmptexteXML.="<item><title>-</title><abstract>-</abstract></item>\n";
114 print "doublons";
115 }
116 }
117 $tmptexteXML.="</items>\n</file>\n";
118 $tmptexteXMLtagger.="</items>\n</file>\n";
119 print FILEOUT1 $tmptexteXML;
120 print FILEOUT2 $tmptexteBRUT;
121 print FILEOUT3 $tmptexteXMLtagger;
122 close FILEOUT1;
123 close FILEOUT2;
124 close FILEOUT3;
125 }
126 else {
127 print "$file ==> $encodage \n";
128 }
129 }
130 }
131
132 }
133 }
Fonction d'étiquetage:
01 sub ettiquetage {
02 my ($title,$texte)=@_;
03 #---------titre-----------------
04 my $codage="utf-8";
05 my $tmptag="texteaetiqueter.txt";
06 #creer un fichier temporaire
07
08 open(TMPFILE,">:encoding(utf-8)",$tmptag);
09 print TMPFILE $title;
10 close (TMPFILE);
11 system("perl5.18.4 tokenise-utf8.pl $tmptag | tree-tagger.exe -token -lemma -no-unknown french-utf8.par > treetagger.txt");
12 system("perl5.18.4 treetagger2xml.pl treetagger.txt $codage");
13 open (TAGOUT,"<:encoding(utf-8)","treetagger.txt.xml");
14 my $titreetiquete="";
15 while (my $ligne=<TAGOUT>){
16 $titreetiquete.=$ligne;
17 }
18 close (TAGOUT);
19 #-------------description---------
20 open(TMPFILE,">:encoding(utf-8)",$tmptag);
21 print TMPFILE $texte;
22 close (TMPFILE);
23 system("perl5.18.4 tokenise-utf8.pl $tmptag | tree-tagger.exe -token -lemma -no-unknown french-utf8.par > treetagger.txt");
24 system("perl5.18.4 treetagger2xml.pl treetagger.txt $codage");
25 open (TAGOUT,"<:encoding(utf-8)","treetagger.txt.xml");
26 my $texteetiquete="";
27 while (my $ligne=<TAGOUT>){
28 $texteetiquete.=$ligne;
29 }
30 close (TAGOUT);
31 return($titreetiquete,$texteetiquete);
32 }
Dans cette fonction, ce qui est essentiel est d’implémenter les programmes de Treetagger dans le script perl.
Au niveau de la préparation, nous avons quatre fichiers qui doivent être placés dans le même répertoire que le script principal.
- 1. tokenise-utf8.pl
- 2. tree-tagger.exe
- 3. treetagger2xml.pl
- 4. french-utf8.par
Cliquez ici pour télécharger
Afin de réaliser l’étiquetage, nous avons besoin de lancer le script « tokenise-utf8.pl » pour segmenter le texte. Puis on va l’étiqueter avec tree-tagger.exe (pour Windows), on va lancer le programme avec les options : -token -lemma -no-unknown , et on met après les options notre ressource lexicale : french-utf8.par.
Cette procédure est la ligne 24 :
system("perl5.18.4 tokenise-utf8.pl $tmptag | tree-tagger.exe -token -lemma -no-unknown french-utf8.par > treetagger.txt");
Ici on doit faire attention à notre version de perl. Si on utilise le perl d’ActiveState dans Cygwin, nous devons écrire « perl5.XX.X… » qui indique également la version du perl qu’on veut lancer. Si on écrit seulement perl sans le suffixe de version, cygwin va lancer sa propre version de perl au lieu de celui d’ActiveState.
Ensuite on transmet le fichier étiqueté de type .txt en fichier XML (ligne 25):
system("perl5.18.4 treetagger2xml.pl treetagger.txt $codage");
Le programme treetagger2xml.pl sort un fichier treetagger.txt.xml , et on lit ce fichier de sortie et sauvegarde le contenu de ce fichier dans la variable $titreetiquete pour le $title et dans la variable $texteetiquete pour le $description.
Finalement avec le nouveau script, on obtient non seulement les fichiers .txt et .xml qui contiennent le contenu textuel, mais aussi les fichiers .xml qui contiennent le contenu étiqueté.
01 <?xml version="1.0" encoding="utf-8" ?>
02 <PARCOURS>
03 <NOM>Chunxiao YAN 2015</NOM>
04 <file>
05 <name>2014/Apr/01/19-00-00/0,2-3208,1-0,0.xml</name>
06 <date>Tue, 01 Apr 2014 16:52:58 GMT</date>
07 <items>
08 <item num="1">
09 <title>
10 <element><data type="type">NOM</data><data type="lemma">marché</data><data type="string">Marchés</data></element>
11 <element><data type="type">ADJ</data><data type="lemma">financier</data><data type="string">financiers</data></element>
12 <element><data type="type">PUN</data><data type="lemma">:</data><data type="string">:</data></element>
13 <element><data type="type">DET:ART</data><data type="lemma">le</data><data type="string">le</data></element>
14 <element><data type="type">NOM</data><data type="lemma">scandale</data><data type="string">scandale</data></element>
15 <element><data type="type">PRP:det</data><data type="lemma">du</data><data type="string">du</data></element>
16 <element><data type="type">NAM</data><data type="lemma">Forex</data><data type="string">Forex</data></element>
17 <element><data type="type">VER:pres</data><data type="lemma">s'étend</data><data type="string">s'étend</data></element>
18 <element><data type="type">PRP</data><data type="lemma">à</data><data type="string">à</data></element>
19 <element><data type="type">NAM</data><data type="lemma">Hongkong</data><data type="string">Hongkong</data></element>
20 </title>
21 <abstract>
22 <element><data type="type">DET:ART</data><data type="lemma">le</data><data type="string">Les</data></element>
23 <element><data type="type">NOM</data><data type="lemma">autorité</data><data type="string">autorités</data></element>
24 <element><data type="type">ADJ</data><data type="lemma">bancaire</data><data type="string">bancaires</data></element>
25 <element><data type="type">ADJ</data><data type="lemma">allemand</data><data type="string">allemande</data></element>
26 <element><data type="type">PUN</data><data type="lemma">,</data><data type="string">,</data></element>
27 <element><data type="type">ADJ</data><data type="lemma">américain</data><data type="string">américaine</data></element>
28 <element><data type="type">PUN</data><data type="lemma">,</data><data type="string">,</data></element>
29 <element><data type="type">ADJ</data><data type="lemma">britannique</data><data type="string">britannique</data></element>
30 <element><data type="type">PUN</data><data type="lemma">,</data><data type="string">,</data></element>
31 <element><data type="type">NOM</data><data type="lemma">singapourienne</data><data type="string">singapourienne</data></element>
32 <element><data type="type">KON</data><data type="lemma">et</data><data type="string">et</data></element>
33 <element><data type="type">NOM</data><data type="lemma">suisse</data><data type="string">suisse</data></element>
34 <element><data type="type">VER:pres</data><data type="lemma">avoir</data><data type="string">ont</data></element>
35 <element><data type="type">VER:pper</data><data type="lemma">ouvrir</data><data type="string">ouvert</data></element>
36 <element><data type="type">ADV</data><data type="lemma">parallèlement</data><data type="string">parallèlement</data></element>
37 <element><data type="type">PRP:det</data><data type="lemma">du</data><data type="string">des</data></element>
38 <element><data type="type">NOM</data><data type="lemma">enquête</data><data type="string">enquêtes</data></element>
39 <element><data type="type">PRP</data><data type="lemma">sur</data><data type="string">sur</data></element>
40 <element><data type="type">PRO:DEM</data><data type="lemma">ce</data><data type="string">ce</data></element>
41 <element><data type="type">NOM</data><data type="lemma">scandale</data><data type="string">scandale</data></element>
42 <element><data type="type">PRO:REL</data><data type="lemma">où</data><data type="string">où</data></element>
43 <element><data type="type">PRP:det</data><data type="lemma">du</data><data type="string">des</data></element>
44 <element><data type="type">NOM</data><data type="lemma">traders</data><data type="string">traders</data></element>
45 <element><data type="type">VER:cond</data><data type="lemma">avoir</data><data type="string">auraient</data></element>
46 <element><data type="type">VER:pper</data><data type="lemma">réussir</data><data type="string">réussi</data></element>
47 <element><data type="type">PRP</data><data type="lemma">à</data><data type="string">à</data></element>
48 <element><data type="type">VER:infi</data><data type="lemma">fausser</data><data type="string">fausser</data></element>
49 <element><data type="type">NOM</data><data type="lemma">l'indice</data><data type="string">l'indice</data></element>
50 <element><data type="type">PRO:REL</data><data type="lemma">qui</data><data type="string">qui</data></element>
51 <element><data type="type">VER:pres</data><data type="lemma">déterminer</data><data type="string">détermine</data></element>
52 <element><data type="type">DET:ART</data><data type="lemma">le</data><data type="string">le</data></element>
53 <element><data type="type">NOM</data><data type="lemma">cour|cours</data><data type="string">cours</data></element>
54 <element><data type="type">PRP:det</data><data type="lemma">du</data><data type="string">des</data></element>
55 <element><data type="type">NOM</data><data type="lemma">devise</data><data type="string">devises</data></element>
56 <element><data type="type">SENT</data><data type="lemma">.</data><data type="string">.</data></element>
57 </abstract>
58 </item>
Le fichier étiqueté produit par Treetagger
Méthode Cordial
Le logiciel est simple à utiliser. Pour étiqueter un fichier, il nous faut ouvrir le fichier .txt qu’on a obtenu dans BAO1. Ensuite, on clique sur l'onglet Syntaxe et puis Etiquetage de texte.
Cordial lit le fichier en encodage ISO-8859, donc si le fichier n’est pas en ISO-8859, il faut d’abord le transcoder.

Voici un exemple de fichier de sortie :

Le fichier cordial complet
Extraction des patrons syntaxiques
Après avoir récupéré nos fichiers étiquetés dans BAO2, nous commençons à extraire les partons syntaxiques.
Dans cette étapes, il s'agit également de plusieurs méthodes.
- 1. Méthode de Serge Fleury et ses extensions
- 2. Méthode de Jean-michel
- 3. Méthode de Xpath
A part ces trois solutions, nous avons également une solution avec XSLT qui n’est pas une méthode de programmation perl.
Concernant les partons syntactiques, on prend le NOM-ADJ et le NOM-PREP-NOM comme les points de départ afin de développer les differentes méthodes.
Méthode de Serge Fleury
La particularité de cette méthode est d’utiliser les expressions régulières.
01 # le modifier pour extraire NOM PREP NOM
02 #--------------------------------------------
03 my @lignes=<FILE>;
04 close(FILE);
05 while (@lignes) {
06 my $ligne=shift(@lignes);
07 #on lit une premiere ligne et on le vire dans la liste
08 chomp $ligne;
09 my $sequence="";
10 my $longueur=0;
11 if ( $ligne =~ /^([^\t]+)\t[^\t]+\tNC.*/){
12 #on prend le premier element de la ligne qui contient un nom
13 my $forme=$1;
14 $sequence.=$forme;
15 $longueur=1;
16 my $nextligne=$lignes[0];
17 if ( $nextligne =~ /^([^\t]+)\t[^\t]+\tPREP.*/){
18 my $forme=$1;
19 $sequence.=" ".$forme;
20 $longueur=2;
21 my $nextligne2=$lignes[1];
22 if ( $nextligne2 =~ /^([^\t]+)\t[^\t]+\tNC.*/){
23 my $forme=$1;
24 $sequence.=" ".$forme;
25 $longueur=3;
26 }
27 }
28 }
29 if ($longueur == 3) {
30 #on extrait que des formes positives qui a une longueur en 2.
31 print $sequence,"\n";
32 }
33 }
La particularité de cette méthode est d’utiliser les expressions régulières.
Dans ce programme, on lance d’abord une boucle « while », qui traite chaque fois une première ligne et en même temps le vire dans la liste des lignes :
my $ligne=shift(@lignes); (ligne 5-7)
Ensuite , on définit deux variables :
$sequence peut sauvegarder temporairement les formes qui satisfont aux expressions régulières de la ligne 11,17 et 21 au cours de chaque exécution de la boucle dans « while ».
$longueur sert à compter le nombre de formes récupérés dans $sequence.
Ensuite , on passe au trois conditions « if » successivement, et en même temps on incrémente la $longueur si la condition est bien acceptée.
De cette manière, on est capable de trouver les formes qui satisfont à notre parton syntaxique à l’aide des expressions régulières et en même temps gardent l’information linéaire qui permet d’extraire une suite d’étiquettes comme l’ordre de notre patron syntaxique (ligne14-29) .
Finalement le dernier « if» sélectionne les bonnes combinaisons afin de les affricher dans le Terminal.
(ligne 32-35)
Cette méthode est performante , et pour cette raison , j'ai complété ce script afin de le rendre plus automatique qui satisfait à différents longueurs de patron syntaxique.
Ce programme complet est capable de lire un répertoire de fichiers et le patron syntaxique sauvegardé dans un fichier de paramètre , de trouver les fichiers .xml à traiter, et d’extraire des termes correspondants à partir du fichier de traitement.
La démarche du programme se deroule comme ci-dessous :
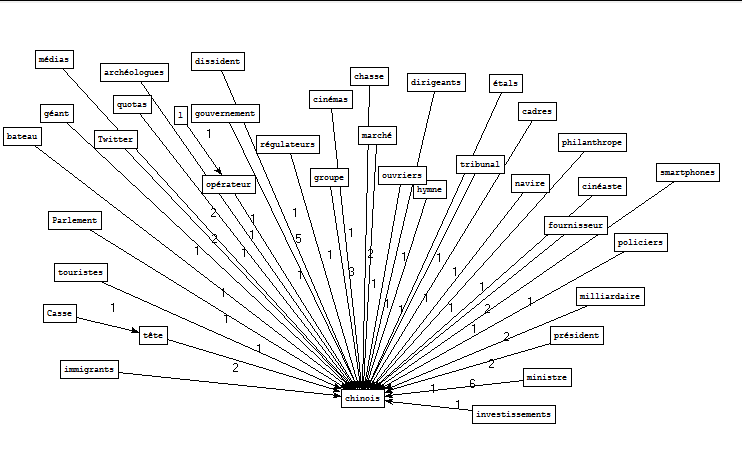
En observant les trois conditions « «if » dans le script précédent, on trouve une grande similarité dans les codes. Cela nous indique qu’il serait possible de générer ces trois conditions « if » en une seule.
.
Tout d'abord , on essaye de générer la représentation de parton et le traitement des fichiers
Partie 1
01 #!/usr/bin/perl
02 <<DOC;
03 Votre Nom : Chunxiao YAN
04 mars 2015
05 usage : perl extratoutenun.pl repertoire-a-parcourir fichier-patrons
06
07 DOC
08
09 opendir(DIR,"$ARGV[0]");
10 open(PATRON,"$ARGV[1]");
11 my @listefichiers = readdir(DIR);
12 closedir(DIR);
13 #print @listefichiers;
14 #creer une rep de sortie
15 my $repsortie="SORTIEPATRON";
16 mkdir($repsortie) or die ("Probleme avec la creation du repertoire de $repsortie, verifier s'il en existe deja une");
17
18 #lire des patrons
19 my $termes=<PATRON>;
20 chomp($termes);
21 #lire ligne par ligne
22 my @listepatron=split(/ /,$termes);
23 print @listepatron;
24 #$listepatron[0],listepatron[1],listepatron[2].........
25 $len=scalar(@listepatron);
26 #on compte longueur de liste de patron
Ce script prend deux arguments comme données d’entrée :
extratoutenun.pl <1. repertoire-a-parcourir(si on a beaucoup de fichiers à traiter ,celui est le cas pour notre projet) > <2. fichier-patrons(sans modifier le programme, on écrit une ligne de parton syntaxique dans un fichier .txt)>
my @listepatron=split(/ /,$termes);
Ensuite on utilise la fonction split pour construire une liste de notre parton syntaxique @listepatron, et on compte sa longueur $len.
Partie 2
01 #traitement de chaque fichier dans le repertoire
02
03 foreach my $fichier (@listefichiers) {
04 next if $fichier =~ /^\.\.?$/;
05 print $fichier;
06 if ($fichier=~/treetagger.xml$/) {
07 $fichier2 = $ARGV[0]."/".$fichier;
08 print $fichier2;
09 #exit;
10 open(FILE,$fichier2);
11 my $output=$repsortie."/".$fichier."extrapatron.xml";
12 if (!open (OUT,">",$output)) { die "Pb a l'ouverture du fichier $output1"};
13 my @lignes=<FILE>;
14 close(FILE);
15 while (@lignes) {
16 my $ligne=shift(@lignes);
17 #print $ligne;
18 #on lit une premiere ligne et on le vire dans la liste
19 chomp $ligne;
20 my $sequence="";
21 my $longueur=0;
22 my $lignepatron=$ligne;
23 my $extraitpatron;
24 my $cpt=0;
25 foreach my $etik (@listepatron) {
26 if ($lignepatron =~ /<element><data type=\"type\">$etik<\/data><data type=\"lemma\">[^<]+<\/data><data type=\"string\">([^<]+)<\/data><\/element>/){
27 #on prend le premier element de la ligne qui contient un $etik
28 my $forme=$1;
29 #print $forme,$etik,"\n";
30 $sequence.=$forme." ";
31 $longueur++;
32 #print $longueur." \n";
33 $lignepatron=$lignes[$cpt];
34 $cpt++;
35 }
36 }
37 if ($longueur == $len) {
38 #print $sequence,"\n";
39 $extraitpatron.=$sequence."\n";
40 }
41 print $extraitpatron;
42 print OUT $extraitpatron;
43
44 }
45
46 close(OUT);
47
48 }
49 }
La deuxième partie traite le ficher et fait l’extraction. Ici on utilise les données produites par Treetagger.
Da la ligne 03 jusqu’à 09, on cherche le fichier cible dans la liste de fichier.
Une fois le bon fichier trouvé, on commence à le traiter dans la boucle « while ».
De la ligne 15 à la ligne 25, on n’a pas modifié les codes principaux. On ajoute variable $extraitpatron qui sauvegarde tous les sequeces extraites.
On rajoute un autre compteur $cpt qui sert à trouver les lignesprochaines.
Ensuite on lance la boucle « foreach » :
foreach my $etik (@listepatron) (ligne 03 )
Pour chaque element dans la liste de patrons , si on trouve cette étiquette dans la ligne, on le garde dans la variable $sequence, et incrémente la longueur de sequence.
Ensuite on doit chercher le prochain élément de la liste de patron dans la ligne prochaine, vue qu’on a le shift(@lignes) au début de boucle « while », la prochaine ligne est le premier élément de la liste @lignes représenté en $lignes[0] (comme $lignes[$cpt] quand $cpt=0), et à la fin on incrémente le $cpt afin de continuer parallèlement dans la boucle « foreach ».(lignes 25-35)
Regarder un exemple des résultats ici.
Nous avons vérifié les resultas produits par le script initial avec ceux de ce script complet. Les nombres d'éléments extraits sont identiques.
Méthode Jean-michel
Le script est le-big-programme.pl
Le programme prend en entrée un fichier de paramètre qui contient les partons syntaxiques qu’on veut extraire et le fichier étiqueté par Cordial (.cnr) .
Dans ce programme, on utilise deux liste @POS et @LIST pour trouver les bons résultats
01 #!/usr/bin/perl
02 # Le programme de JMD...
03 # lecture du fichier cordial et d'un fichier de patrons
04 # IMPORTANT : TOUT EST EN ISO.
05 #-----------------------------------------------------------
06 # 1er argument : le fichier des patrons morphosyntaxiques
07 open(TERMINO,"<$ARGV[0]");
08 while (my $terme=<TERMINO>) {
09 chomp($terme);
10 $terme=~s/ +/ /g;
11 $terme=~s/\r//g;
12 open(CORDIAL,"<$ARGV[1]");
13 my @POS=();
14 my @TOKEN=();
15 while (my $ligne=<CORDIAL>) {
16 chomp($ligne);
17 $ligne=~s/\r//g;
18 if ($ligne!~/PCT/) {
19 my @LISTE=split(/\t/,$ligne);
20 #print "PATRON LU <$terme> : Ligne lue <@LISTE>\n";
21 push(@POS,$LISTE[2]);
22 push(@TOKEN,$LISTE[0]);
23 }
24 else {
25 # on est arriv?sur une PCT, on va la traiter...
26 #print "----------------------------------------\n";
27 #print "<@TOKEN>\n";
28 #print "<@POS>\n";
29 #print "TERME CHERCHE : $terme \n";
30 #my $a=<STDIN>;
31 # on doit chercher si le "scalaire" $terme est dans @POS
32 # pour cela on va transformer POS et TOKEN en scalaire
33 # pour ensuite faire le match entre le TERME et le scalaire POS
34 # si match alors on imprime...
35 my $pos=join(" ",@POS);
36 my $token=join(" ",@TOKEN);
37 my $cmptdetrouvage=0;
38 while ($pos=~/$terme/g) {
39 $cmptdetrouvage++;
40 #print "Youpi, TROUVE $cmptdetrouvage fois \n ";
41 #print "En effet : $terme est bien dans $pos !!!!\n";
42 my $avantlacorrespondance=$`;
43 # on compte le nb de blanc dans avantlacorrespondance et dans terme...
44 #--------------------------------------------------------------------------
45 # SUPER METHODE : my $comptagedeblanc = () = $avantlacorrespondance=~/ /g;
46 #-------------------------------------------------------------------------
47 # autre methode : avec un while
48 my $comptagedeblancdansterme=0;
49 while ($terme=~/ /g) {
50 $comptagedeblancdansterme++;
51 }
52 my $comptagedeblanc=0;
53 #print "AVANT : $avantlacorrespondance \n";
54 while ($avantlacorrespondance=~/ /g) {
55 $comptagedeblanc++;
56 }
57 for (my $i=$comptagedeblanc;$i<=$comptagedeblanc+$comptagedeblancdansterme;$i++) {
58 print $TOKEN[$i]." ";
59 }
60 print "\n";
61 }
62 # c'est fini pour la recherche du match
63 # on vide les 2 listes de travail avant de recommencer de les remplir
64 @POS=();
65 @TOKEN=();
66 }
67 }
68 close(CORDIAL);
69 }
70 close(TERMINO);
71 #----------------
Methode Xpath
Cette méthode utilise le module XML::XPath qui permet de réaliser les requêtes XPATH pour repérer des tokens, des lemmes et des catégories ainsi qu'extraire des partons syntaxiques qui sont indiqués dans un fichier paramètre. Script
001 #/usr/bin/perl
002 <<DOC;
003 Nom : Rachid Belmouhoub
004 Avril 2012
005 usage : perl bao3_rb_new.pl fichier_tag fichier_motif
006 DOC
007 #a faire sur les morceaux d'ettiquettage un fichier par jour et concatener l'ensemble de fichier.
008
009 use strict;
010 use utf8;
011 use XML::LibXML;
012
013 # Définition globale des encodage d'entrée et sortie du script à utf8
014 binmode STDIN, ':encoding(utf8)';
015 binmode STDOUT, ':encoding(utf8)';
016
017 # On vérifie le nombre d'arguments de l'appel au script ($0 : le nom du script)
018 if($#ARGV!=1){print "usage : perl $0 fichier_tag fichier_motif";exit;}
019
020 # Enregistrement des arguments de la ligne de commande dans les variables idoines
021 my $tag_file= shift @ARGV;
022 my $patterns_file = shift @ARGV;
023
024 # création de l'objet XML::LibXML pour explorer le fichier de sortie tree-tagger XML
025 my $xp = XML::LibXML->new(XML_LIBXML_RECOVER => 2);
026 $xp->recover_silently(1);
027
028 my $dom = $xp->load_xml( location => $tag_file );
029 #parcours le fichier
030 my $root = $dom->getDocumentElement();
031
032 #creer un nouveau objet
033 my $xpc = XML::LibXML::XPathContext->new($root);
034
035 # Ouverture du fichiers de motifs
036 open(PATTERNSFILE, $patterns_file) or die "can't open $patterns_file: $!\n";
037
038 # lecture du fichier contenant les motifs, un motif par ligne (par exemple : NOM ADJ)
039
040 #automatiser plusieurs motifs
041 while (my $ligne = <PATTERNSFILE>) {
042 # Appel à la procédure d'extraction des motifs
043 &extract_pattern($ligne);
044 }
045
046 # Fermeture du fichiers de motifs
047 close(PATTERNSFILE);
048
049 # routine de construction des chemins XPath
050 sub construit_XPath{
051 # On récupère la ligne du motif recherché
052 my $local_ligne=shift @_;
053
054 # initialisation du chemin XPath
055 my $search_path="";
056
057 # on supprime avec la fonction chomp un éventuel retour à la ligne
058 chomp($local_ligne);
059
060 # on élimine un éveltuel retour chariot hérité de windows
061 $local_ligne=~ s/\r$//;
062
063 # Construction au moyen de la fonction split d'un tableau dont chaque élément a pour valeur un élément du motif recherché
064 my @tokens=split(/ /,$local_ligne);
065
066 # On commence ici la construction du chemin XPath
067 # Ce chemin correspond au premier noeud "element" de l'arbre XML qui répond au motif cherché
068 $search_path="//element[contains(data[\@type=\"type\"],\"$tokens[0]\")]";
069
070 # Initialisation du compteur pour la boucle de construction du chemin XPath
071 my $i=1;
072 while ($i < $#tokens) {
073 $search_path.="[following-sibling::element[1][contains(data[\@type=\"type\"],\"$tokens[$i]\")]";
074 $i++;
075 }
076 my $search_path_suffix="]";
077
078 # on utilise l'opérateur x qui permet de répéter la chaine de caractère à sa gauche autant de fois que l'entier à sa droite,
079 # soit $i fois $search_path_suffix
080 $search_path_suffix=$search_path_suffix x $i;
081
082 # le chemin XPath final
083 $search_path.="[following-sibling::element[1][contains(data[\@type=\"type\"],\"".$tokens[$#tokens]."\")]"
084 .$search_path_suffix;
085 # print "$search_path\n";
086
087 # on renvoie à la procédure appelante le chein XPath et le tableau des éléments du motif
088 return ($search_path,@tokens);
089 }
090
091 # routine d'extraction du motif
092 sub extract_pattern{
093 # On récupère la ligne du motif recherché
094 my $ext_pat_ligne= shift @_;
095
096 # Appel de la fonction construit_XPath pour le motif lu à la ligne courrante du fichier de motif
097 my ($search_path,@tokens) = &construit_XPath($ext_pat_ligne);
098
099 # définition du nom du fichier de résultats pour le motif en utilisant la fonction join
100 my $match_file = "res_extract-".join('_', @tokens).".txt";
101 #$match_file=~s/://g;
102 # Ouverture du fichiers de résultats encodé en UTF-8
103 open(MATCHFILE,">:encoding(UTF-8)", "$match_file") or die "can't open $match_file: $!\n";
104
105 # création de l'objet XML::XPath pour explorer le fichier de sortie tree-tagger XML
106
107 # Parcours des noeuds du ficher XML correspondant au motif, au moyen de la méthode findnodes
108 # qui prend pour argument le chemin XPath construit précédement
109 # avec la fonction "construit_XPath"
110 my @nodes=$root->findnodes($search_path);
111 foreach my $noeud ( @nodes) {
112 # Initialisation du chemin XPath relatif du noeud "data" contenant
113 # la forme correspondant au premier élément du motif
114 # Ce chemin est relatif au premier noeud "element" du bloc retourné
115 # et pointe sur le troisième noeud "data" fils du noeud "element"
116 # en l'identifiant par la valeur "string" de son attribut "type"
117 my $form_xpath="";
118 $form_xpath="./data[\@type=\"string\"]";
119
120 # Initialisation du compteur pour la boucle d'éxtraction des formes correspondants
121 # aux éléments suivants du motif
122 my $following=0;
123
124 # Recherche du noeud data contenant la forme correspondant au premier élément du motif
125 # au moyen de la fonction "find" qui prend pour arguments:
126 # 1. le chemin XPath relatif du noeud "data"
127 # 2. le noeud en cours de traitement dans cette boucle foreach
128 # la fonction "find" retourne par défaut une liste de noeuds, dans notre cas cette liste
129 # ne contient qu'un seul élément que nous récupérons avec la fonction "get_node"
130 # enfin nous en imprimons le contenu textuel au moyen de la méthode string_value
131 print MATCHFILE $xpc->findvalue($form_xpath,$noeud);
132
133 # Boucle d'éxtraction des formes correspondants aux éléments suivants du motif
134 # On descend dans chaque noeud element du bloc
135 while ( $following < $#tokens) {
136 # Incrémentation du compteur $following de cette boucle d'éxtraction des formes
137 $following++;
138
139 # Construction du chemin XPath relatif du noeud "data" contenant
140 # la forme correspondant à l'élément suivant du motif
141 # Notez bien l'utilisation du compteur $folowing tant dans la condition de la boucle ci-dessus
142 # que dans la construction du chemin relatif XPath
143 my $following_elmt="following-sibling::element[".$following."]";
144 $form_xpath=$following_elmt."/data[\@type=\"string\"]";
145
146 # Impression du contenu textuel du noeud data contenant la forme correspondant à l'élément suivant du motif
147 print MATCHFILE " ",$xpc->findvalue($form_xpath,$noeud);
148 }
149
150 print MATCHFILE "\n";
151 }
152 # Fermeture du fichiers de motifs
153 close(MATCHFILE);
154 }
Mehtode XSLT
Cette méthode est très pratique au niveau d’utilisation, et également rapide. Nous n’avons pas besoin de script dans cette méthode, et nous établissons simplement une feuille de style afin d’afficher les terminologies qu’on veut à partir du fichier XML produit par Treetagger.
Dans cette feuille de style, nous avons trois « templates » correspondants à les trois patrons syntaxique : NOM-ADJ , NOM-PRP-NOM, et NOM-NOM.
Exemple :
Dans le ‘match ‘ , à l’aide des expressions Xpath , on arrive à décrire les éléments qu’on veut traiter.
<xsl:template match="element[contains(data[1], 'NOM')][following-sibling::element[1] [contains(data[1], 'ADJ')]]">
(Si dans ‘element’ le deuxième ‘data’ contient le ‘NOM’, et dans le nœud suivant de ‘element’ le deuxième ‘data’ contient le ‘ADJ’.)
Au niveau d’application du ‘template’ pour chaque patron syntaxique, on l’applique une fois sous le ‘title’ et une fois sous le ‘abstract’ :
<xsl:apply-templates select="PARCOURS/file/items/item/title/element[contains(data[1], 'NOM')][following-sibling::element[1][contains(data[1], 'ADJ')]]"/>
<xsl:apply-templates select="PARCOURS/file/items/item/abstract/element[contains(data[1], 'NOM')][following-sibling::element[1][contains(data[1], 'ADJ')]]"/>
Voici notre feuille de style pour visualiser les patrons :
01 <?xml version="1.0" encoding="UTF-8"?>
02 <xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform" version="2.0">
03 <xsl:output method="html"/>
04 <xsl:template match="/">
05 <html>
06 <body bgcolor="#81808E">
07 <table align="center" width="800px" bgcolor="white" bordercolor="#3300FF" border="1">
08 <center>
09 <font color="white" size="12">Extraction de patron </font>
10 </center>
11 <tr bgcolor="black">
12 <td align="center"><font color="red"><b>NOM </b></font>
13 <font color="blue"><b>ADJ</b></font>
14 </td>
15 <td align="center">
16 <font color="red"><b>NOM </b></font>
17 <font color="blue"><b>PREP </b></font>
18 <font color="red"><b>NOM</b></font>
19 </td>
20 <td align="center">
21 <font color="red"><b>NOM </b></font>
22 <font color="blue"><b>NOM</b></font>
23 </td>
24 </tr>
25 <tr>
26 <td valign="top">
27 <blockquote>
28 <xsl:apply-templates select="PARCOURS/file/items/item/title/element[contains(data[1], 'NOM')][following-sibling::element[1][contains(data[1], 'ADJ')]]"/>
29 </blockquote>
30 <blockquote>
31 <xsl:apply-templates select="PARCOURS/file/items/item/abstract/element[contains(data[1], 'NOM')][following-sibling::element[1][contains(data[1], 'ADJ')]]"/>
32 </blockquote>
33 </td>
34 <td valign="top">
35 <blockquote>
36 <xsl:apply-templates select="PARCOURS/file/items/item/title/element[contains(data[1], 'NOM')][following-sibling::element[1][contains(data[1], 'PRP')]] [following-sibling::element[2][contains(data[1], 'NOM')]]"/>
37 </blockquote>
38 <blockquote>
39 <xsl:apply-templates select="PARCOURS/file/items/item/abstract/element[contains(data[1], 'NOM')][following-sibling::element[1][contains(data[1], 'PRP')]] [following-sibling::element[2][contains(data[1], 'NOM')]]"/>
40 </blockquote>
41 </td>
42 <td valign="top">
43 <blockquote>
44 <xsl:apply-templates select="PARCOURS/file/items/item/title/element[contains(data[1], 'NOM')][following-sibling::element[1][contains(data[1], 'NOM')]]"/>
45 </blockquote>
46 <blockquote>
47 <xsl:apply-templates select="PARCOURS/file/items/item/abstract/element[contains(data[1], 'NOM')][following-sibling::element[1][contains(data[1], 'NOM')]]"/>
48 </blockquote>
49 </td>
50 </tr>
51 </table>
52 </body>
53 </html>
54 </xsl:template>
55 <xsl:template match="element[contains(data[1], 'NOM')][following-sibling::element[1] [contains(data[1], 'ADJ')]]">
56 <font color="blue">
57 <xsl:value-of select="./data[3]"/>
58 </font>
59 <xsl:text> </xsl:text>
60 <font color="red">
61 <xsl:value-of select="following-sibling::element[1]/data[3]"/>
62 </font>
63 <br/>
64 </xsl:template>
65 <xsl:template match="element[contains(data[1], 'NOM')][following-sibling::element[1] [contains(data[1], 'NOM')]]">
66 <font color="blue">
67 <xsl:value-of select="./data[3]"/>
68 </font>
69 <xsl:text> </xsl:text>
70 <font color="red">
71 <xsl:value-of select="following-sibling::element[1]/data[3]"/>
72 </font>
73 <br/>
74 </xsl:template>
75 <xsl:template match="element[contains(data[1], 'NOM')][following-sibling::element[1][contains(data[1], 'PRP')]] [following-sibling::element[2][contains(data[1], 'NOM')]]">
76 <font color="blue">
77 <xsl:value-of select="./data[3]"/>
78 </font>
79 <xsl:text> </xsl:text>
80 <font color="red">
81 <xsl:value-of select="following-sibling::element[1]/data[3]"/>
82 </font>
83 <xsl:text> </xsl:text>
84 <font color="blue">
85 <xsl:value-of select="following-sibling::element[2]/data[3]"/>
86 </font>
87 <br/>
88 </xsl:template>
89 </xsl:stylesheet>
Pour visualier le resultat, veuillez cliquer ici
 voir + sur la présentation du projet
voir + sur la présentation du projet