Secteur TAL Informatique,
Université Sorbonne nouvelle, Paris 3
19 rue des Bernardins, 75005 Paris


Ressources locales
"Corpus de campagne" - Présidentielle 2002
Ressources pour les cours
- DormiPleure.cnr
- DormiPleure.txt
- DormiPleure.xml
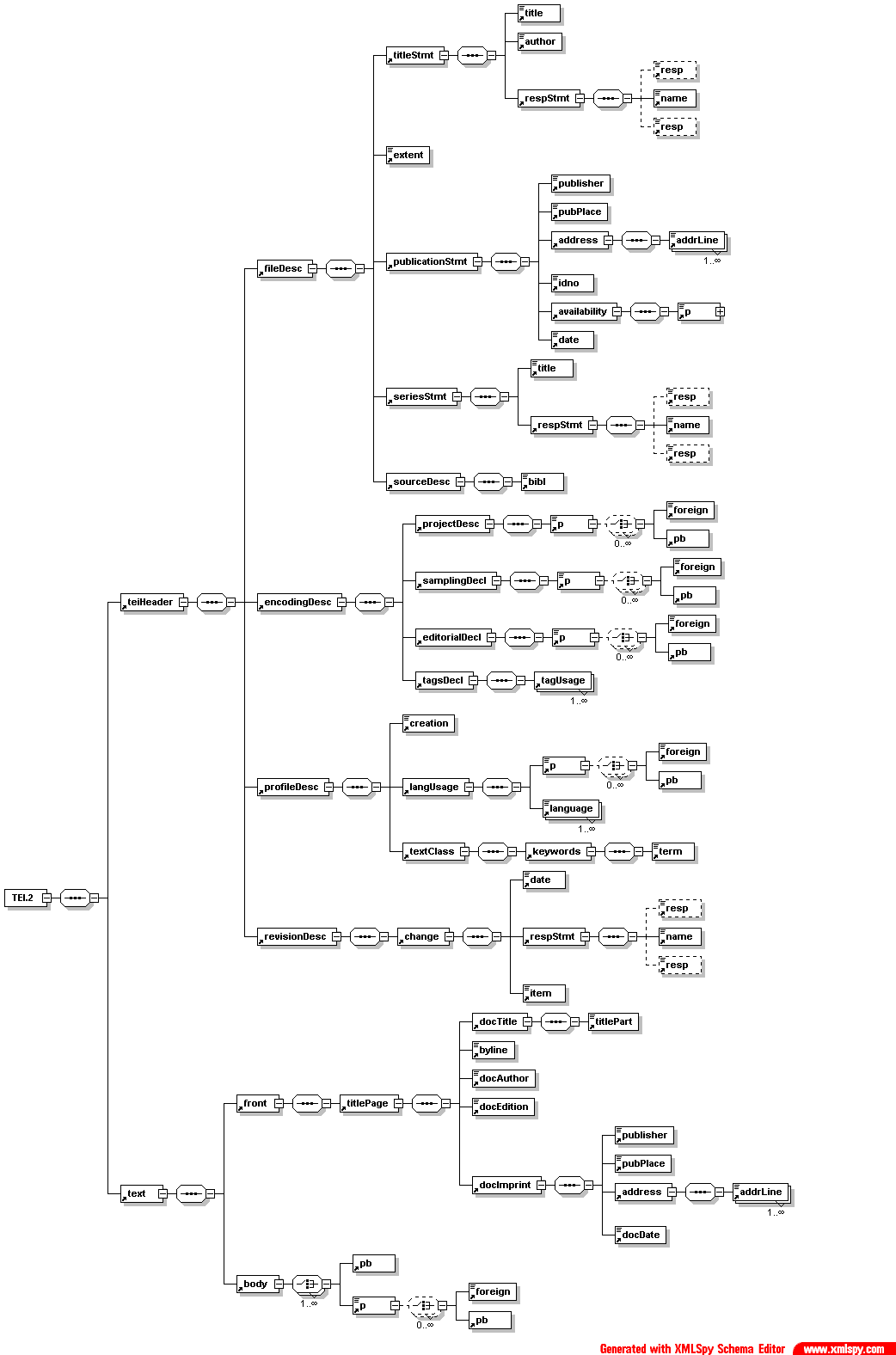
- exempleTEI2.xml
- tei2.png
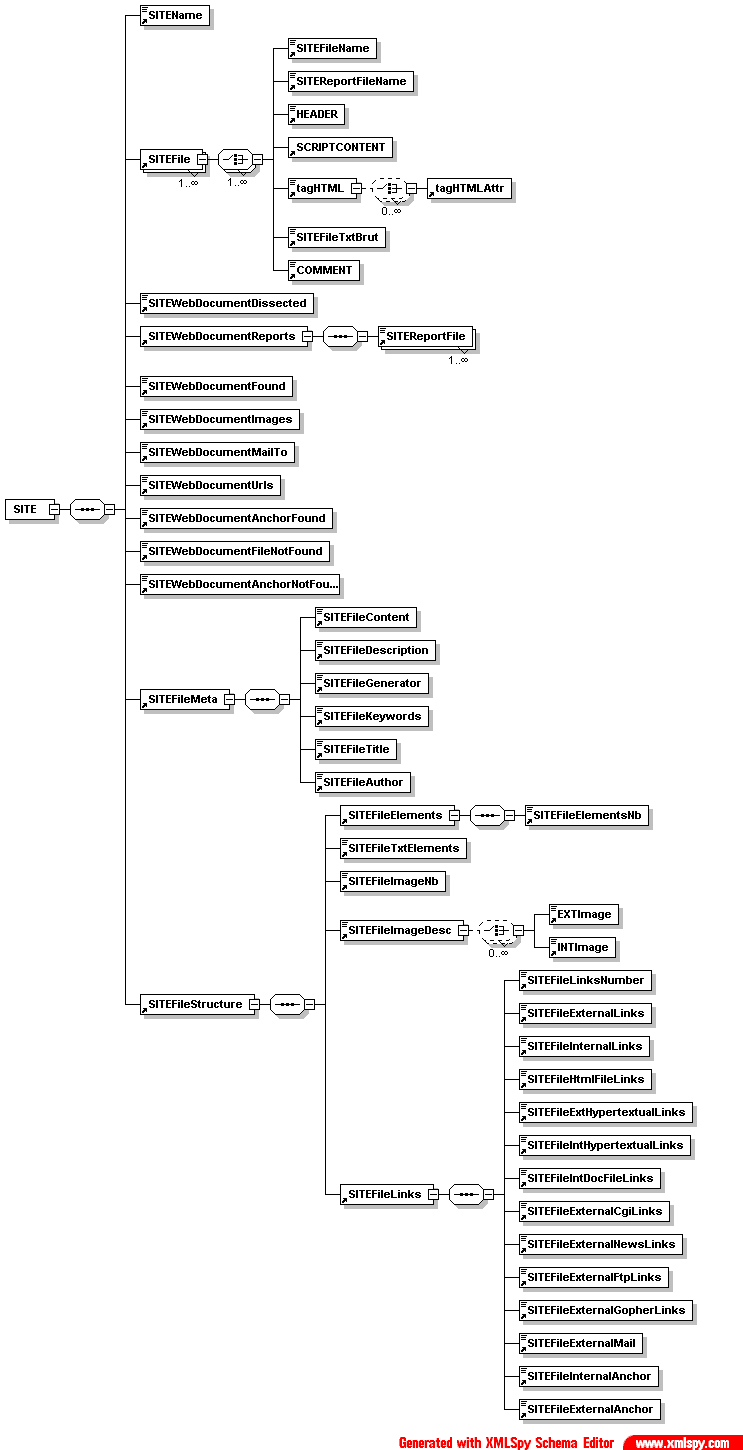
- CorpusSitesWeb/CorpusTypweb.dtd
- CorpusSitesWeb/CorpusTypweb.xml
- CorpusSitesWeb/CorpusTypweb.xml.Ascii
- CorpusSitesWeb/CorpusTypweb.xml.Caracteres
- CorpusSitesWeb/CorpusTypweb.xml.VerifieCaracteres
- CorpusSitesWeb/corp-jura.speleo1.xml
- CorpusSitesWeb/corp-jura.speleo1.xml.Ascii
- CorpusSitesWeb/corp-jura.speleo1.xml.Caracteres
- CorpusSitesWeb/corp-jura.speleo1.xml.VerifieCaracteres
- CorpusSitesWeb/corp-lexicoWWW.xml
- CorpusSitesWeb/corp-mairie.aureilhan1-sansDTD.xml
- CorpusSitesWeb/corp-mairie.aureilhan1.xml
- CorpusSitesWeb/corp-mairie.aureilhan1.xml.Ascii
- CorpusSitesWeb/corp-mairie.aureilhan1.xml.Caracteres
- CorpusSitesWeb/corp-mairie.aureilhan1.xml.modification
- CorpusSitesWeb/corp-mairie.aureilhan1.xml.modified
- CorpusSitesWeb/corp-siteDemo-sansDTD.xml
- CorpusSitesWeb/corp-siteDemo.xml
- CorpusSitesWeb/corp-siteDemo.xml.Ascii
- CorpusSitesWeb/corp-siteDemo.xml.Caracteres
- CorpusSitesWeb/typweb.dtd
- CorpusSitesWeb/jura/jura-038.png
- CorpusSitesWeb/jura/Jura-038-schema/jura-038.html
- CorpusSitesWeb/jura/Jura-038-schema/jura-038_p1.png
- CorpusSitesWeb/jura/Jura-038-schema/jura-038_p10.png
- CorpusSitesWeb/jura/Jura-038-schema/jura-038_p11.png
- CorpusSitesWeb/jura/Jura-038-schema/jura-038_p12.png
- CorpusSitesWeb/jura/Jura-038-schema/jura-038_p13.png
- CorpusSitesWeb/jura/Jura-038-schema/jura-038_p14.png
- CorpusSitesWeb/jura/Jura-038-schema/jura-038_p15.png
- CorpusSitesWeb/jura/Jura-038-schema/jura-038_p16.png
- CorpusSitesWeb/jura/Jura-038-schema/jura-038_p17.png
- CorpusSitesWeb/jura/Jura-038-schema/jura-038_p18.png
- CorpusSitesWeb/jura/Jura-038-schema/jura-038_p19.png
- CorpusSitesWeb/jura/Jura-038-schema/jura-038_p2.png
- CorpusSitesWeb/jura/Jura-038-schema/jura-038_p20.png
- CorpusSitesWeb/jura/Jura-038-schema/jura-038_p21.png
- CorpusSitesWeb/jura/Jura-038-schema/jura-038_p22.png
- CorpusSitesWeb/jura/Jura-038-schema/jura-038_p23.png
- CorpusSitesWeb/jura/Jura-038-schema/jura-038_p24.png
- CorpusSitesWeb/jura/Jura-038-schema/jura-038_p25.png
- CorpusSitesWeb/jura/Jura-038-schema/jura-038_p26.png
- CorpusSitesWeb/jura/Jura-038-schema/jura-038_p27.png
- CorpusSitesWeb/jura/Jura-038-schema/jura-038_p28.png
- CorpusSitesWeb/jura/Jura-038-schema/jura-038_p29.png
- CorpusSitesWeb/jura/Jura-038-schema/jura-038_p3.png
- CorpusSitesWeb/jura/Jura-038-schema/jura-038_p30.png
- CorpusSitesWeb/jura/Jura-038-schema/jura-038_p31.png
- CorpusSitesWeb/jura/Jura-038-schema/jura-038_p32.png
- CorpusSitesWeb/jura/Jura-038-schema/jura-038_p33.png
- CorpusSitesWeb/jura/Jura-038-schema/jura-038_p34.png
- CorpusSitesWeb/jura/Jura-038-schema/jura-038_p35.png
- CorpusSitesWeb/jura/Jura-038-schema/jura-038_p36.png
- CorpusSitesWeb/jura/Jura-038-schema/jura-038_p37.png
- CorpusSitesWeb/jura/Jura-038-schema/jura-038_p38.png
- CorpusSitesWeb/jura/Jura-038-schema/jura-038_p39.png
- CorpusSitesWeb/jura/Jura-038-schema/jura-038_p4.png
- CorpusSitesWeb/jura/Jura-038-schema/jura-038_p40.png
- CorpusSitesWeb/jura/Jura-038-schema/jura-038_p41.png
- CorpusSitesWeb/jura/Jura-038-schema/jura-038_p42.png
- CorpusSitesWeb/jura/Jura-038-schema/jura-038_p43.png
- CorpusSitesWeb/jura/Jura-038-schema/jura-038_p44.png
- CorpusSitesWeb/jura/Jura-038-schema/jura-038_p45.png
- CorpusSitesWeb/jura/Jura-038-schema/jura-038_p46.png
- CorpusSitesWeb/jura/Jura-038-schema/jura-038_p47.png
- CorpusSitesWeb/jura/Jura-038-schema/jura-038_p48.png
- CorpusSitesWeb/jura/Jura-038-schema/jura-038_p49.png
- CorpusSitesWeb/jura/Jura-038-schema/jura-038_p5.png
- CorpusSitesWeb/jura/Jura-038-schema/jura-038_p50.png
- CorpusSitesWeb/jura/Jura-038-schema/jura-038_p51.png
- CorpusSitesWeb/jura/Jura-038-schema/jura-038_p6.png
- CorpusSitesWeb/jura/Jura-038-schema/jura-038_p7.png
- CorpusSitesWeb/jura/Jura-038-schema/jura-038_p8.png
- CorpusSitesWeb/jura/Jura-038-schema/jura-038_p9.png
- CorpusSitesWeb/jura/res243(jura.speleo1)/StatWordByFile.txt
- CorpusSitesWeb/jura/res243(jura.speleo1)/StatWordFull.txt
- CorpusSitesWeb/jura/res243(jura.speleo1)/corp-jura.speleo1.txt
- CorpusSitesWeb/jura/res243(jura.speleo1)/corp-jura.speleo1.xml
- CorpusSitesWeb/jura/res243(jura.speleo1)/indexFile.txt
- CorpusSitesWeb/jura/res243(jura.speleo1)/trace.txt
- CorpusSitesWeb/jura/res243(jura.speleo1)/trash.txt
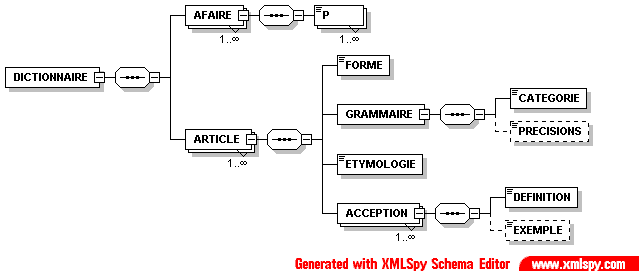
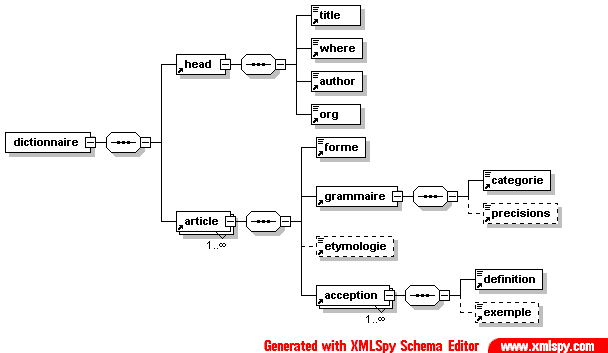
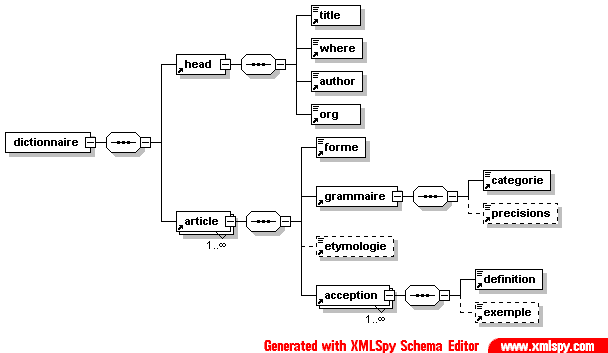
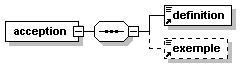
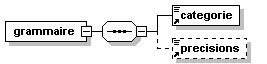
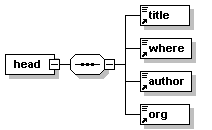
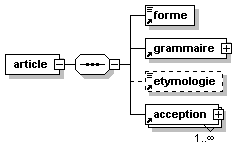
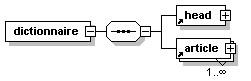
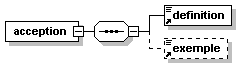
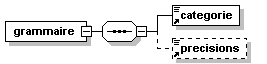
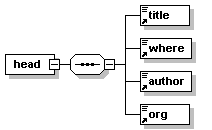
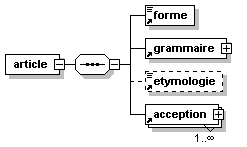
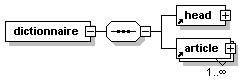
- Dico/Petit_fictionnaire.xml
- Dico/articles.xml
- Dico/dico.dtd
- Dico/dico.png
- Dico/dico.svg
- Dico/dico.xml
- Dico/dico2001-sansDTD.xml
- Dico/dico2001-ssdtd.png
- Dico/dico2001.dtd
- Dico/dico2001.png
- Dico/dico2001.xml
- Dico/dicoHarumi.dtd
- Dico/dicoHarumi.txt
- Dico/fliction.dtd
- Dico/dico2001-schema/dico2001.html
- Dico/dico2001-schema/dico2001_p1.png
- Dico/dico2001-schema/dico2001_p10.png
- Dico/dico2001-schema/dico2001_p11.png
- Dico/dico2001-schema/dico2001_p12.png
- Dico/dico2001-schema/dico2001_p13.png
- Dico/dico2001-schema/dico2001_p14.png
- Dico/dico2001-schema/dico2001_p15.png
- Dico/dico2001-schema/dico2001_p2.png
- Dico/dico2001-schema/dico2001_p3.png
- Dico/dico2001-schema/dico2001_p4.png
- Dico/dico2001-schema/dico2001_p5.png
- Dico/dico2001-schema/dico2001_p6.png
- Dico/dico2001-schema/dico2001_p7.png
- Dico/dico2001-schema/dico2001_p8.png
- Dico/dico2001-schema/dico2001_p9.png
- Dico/dico2001-schema-dtd/dico2001.html
- Dico/dico2001-schema-dtd/dico2001_p1.png
- Dico/dico2001-schema-dtd/dico2001_p10.png
- Dico/dico2001-schema-dtd/dico2001_p11.png
- Dico/dico2001-schema-dtd/dico2001_p12.png
- Dico/dico2001-schema-dtd/dico2001_p13.png
- Dico/dico2001-schema-dtd/dico2001_p14.png
- Dico/dico2001-schema-dtd/dico2001_p15.png
- Dico/dico2001-schema-dtd/dico2001_p2.png
- Dico/dico2001-schema-dtd/dico2001_p3.png
- Dico/dico2001-schema-dtd/dico2001_p4.png
- Dico/dico2001-schema-dtd/dico2001_p5.png
- Dico/dico2001-schema-dtd/dico2001_p6.png
- Dico/dico2001-schema-dtd/dico2001_p7.png
- Dico/dico2001-schema-dtd/dico2001_p8.png
- Dico/dico2001-schema-dtd/dico2001_p9.png
- Duch/duchcnr.png
- Duch/duchcr.xml
- Miterrand/texte.dtd
- Miterrand/texte.svg
- Miterrand/texte.xml
- Miterrand/texte.xml.mod.xml
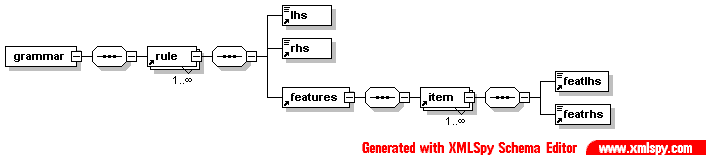
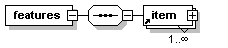
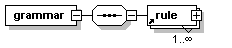
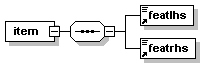
- PatrXML/gramPATR.dtd
- PatrXML/grammPATR-2rule.xml
- PatrXML/grammPATR-onerule.xml
- PatrXML/grammPATR-onerule.xml.mod.xml
- PatrXML/grammPATR.xml
- PatrXML/grammPATR.xml.mod.xml
- PatrXML/grammPATRavecDTD.xml
- PatrXML/grammaire.png
- PatrXML/grammaireCorrigee.grm
- PatrXML/grammpatr.dtd
- PatrXML/lexiqueCorrigee.lex
- PatrXML/lexiquePATR.xml
- PatrXML/grammaire-schema/grammaire.html
- PatrXML/grammaire-schema/grammaire_p1.png
- PatrXML/grammaire-schema/grammaire_p2.png
- PatrXML/grammaire-schema/grammaire_p3.png
- PatrXML/grammaire-schema/grammaire_p4.png
- PatrXML/grammaire-schema/grammaire_p5.png
- PatrXML/grammaire-schema/grammaire_p6.png
- PatrXML/grammaire-schema/grammaire_p7.png
- PatrXML/grammaire-schema/grammaire_p8.png
- Prem/p96-2001-precordial.cnr-avantcorrection
- Prem/p96-2001-precordial.cnr-corrige
- Prem/p96-2001-precordial.xml
- Prem/p96-2001-precordial2xml.xml
- Prem/p96-2001-versionSlide.xml
- Prem/p96-2001.cnr
- Prem/p96-2001.dtd
- Prem/p96-2001.xml
- Prem/p96.xml
- Prem/prem2001.png
- Prem/prema96-bh.xml
- Prem/premature96.dtd
- Prem/prem2001-schema/prem2001.html
- Prem/prem2001-schema/prem2001_p1.png
- Prem/prem2001-schema/prem2001_p10.png
- Prem/prem2001-schema/prem2001_p11.png
- Prem/prem2001-schema/prem2001_p12.png
- Prem/prem2001-schema/prem2001_p13.png
- Prem/prem2001-schema/prem2001_p14.png
- Prem/prem2001-schema/prem2001_p15.png
- Prem/prem2001-schema/prem2001_p16.png
- Prem/prem2001-schema/prem2001_p17.png
- Prem/prem2001-schema/prem2001_p18.png
- Prem/prem2001-schema/prem2001_p19.png
- Prem/prem2001-schema/prem2001_p2.png
- Prem/prem2001-schema/prem2001_p20.png
- Prem/prem2001-schema/prem2001_p21.png
- Prem/prem2001-schema/prem2001_p22.png
- Prem/prem2001-schema/prem2001_p23.png
- Prem/prem2001-schema/prem2001_p24.png
- Prem/prem2001-schema/prem2001_p25.png
- Prem/prem2001-schema/prem2001_p26.png
- Prem/prem2001-schema/prem2001_p27.png
- Prem/prem2001-schema/prem2001_p28.png
- Prem/prem2001-schema/prem2001_p29.png
- Prem/prem2001-schema/prem2001_p3.png
- Prem/prem2001-schema/prem2001_p30.png
- Prem/prem2001-schema/prem2001_p31.png
- Prem/prem2001-schema/prem2001_p32.png
- Prem/prem2001-schema/prem2001_p33.png
- Prem/prem2001-schema/prem2001_p34.png
- Prem/prem2001-schema/prem2001_p35.png
- Prem/prem2001-schema/prem2001_p36.png
- Prem/prem2001-schema/prem2001_p37.png
- Prem/prem2001-schema/prem2001_p38.png
- Prem/prem2001-schema/prem2001_p39.png
- Prem/prem2001-schema/prem2001_p4.png
- Prem/prem2001-schema/prem2001_p40.png
- Prem/prem2001-schema/prem2001_p41.png
- Prem/prem2001-schema/prem2001_p42.png
- Prem/prem2001-schema/prem2001_p43.png
- Prem/prem2001-schema/prem2001_p5.png
- Prem/prem2001-schema/prem2001_p6.png
- Prem/prem2001-schema/prem2001_p7.png
- Prem/prem2001-schema/prem2001_p8.png
- Prem/prem2001-schema/prem2001_p9.png
- PremHTML/bebes.html
- PremHTML/etats.html
- PremHTML/index.html
- PremHTML/inf.html
- PremHTML/intro.html
- PremHTML/prematu.html
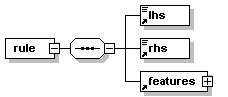
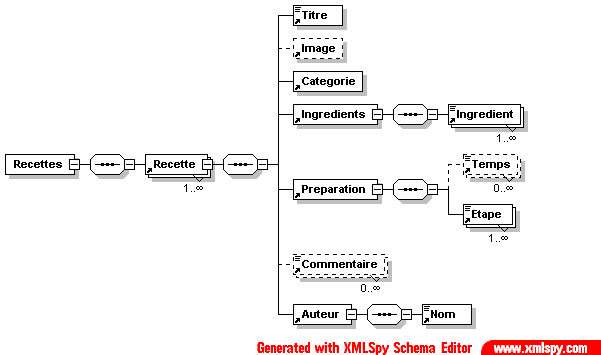
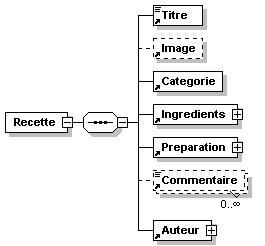
- Recettes/recettes.png
- Recettes/recettes.xml
- Recettes/recettes-schema/recettes.html
- Recettes/recettes-schema/recettes_p1.png
- Recettes/recettes-schema/recettes_p10.png
- Recettes/recettes-schema/recettes_p11.png
- Recettes/recettes-schema/recettes_p12.png
- Recettes/recettes-schema/recettes_p13.png
- Recettes/recettes-schema/recettes_p2.png
- Recettes/recettes-schema/recettes_p3.png
- Recettes/recettes-schema/recettes_p4.png
- Recettes/recettes-schema/recettes_p5.png
- Recettes/recettes-schema/recettes_p6.png
- Recettes/recettes-schema/recettes_p7.png
- Recettes/recettes-schema/recettes_p8.png
- Recettes/recettes-schema/recettes_p9.png
- Saintex/PRINC_BON.DTD
- Saintex/pp.png
- Saintex/pp.xml
- Saintex/saintex.png
- Saintex/saintex.xsl
- Saintex/saintexCorrige.dtd
- Saintex/saintexCorrige.xml
- Saintex/scripts.js
- Saintex/style.xsl
- Saintex/pp-schema/saintex.html
- Saintex/pp-schema/saintex_p1.png
- Saintex/pp-schema/saintex_p10.png
- Saintex/pp-schema/saintex_p11.png
- Saintex/pp-schema/saintex_p12.png
- Saintex/pp-schema/saintex_p13.png
- Saintex/pp-schema/saintex_p14.png
- Saintex/pp-schema/saintex_p15.png
- Saintex/pp-schema/saintex_p16.png
- Saintex/pp-schema/saintex_p17.png
- Saintex/pp-schema/saintex_p18.png
- Saintex/pp-schema/saintex_p19.png
- Saintex/pp-schema/saintex_p2.png
- Saintex/pp-schema/saintex_p3.png
- Saintex/pp-schema/saintex_p4.png
- Saintex/pp-schema/saintex_p5.png
- Saintex/pp-schema/saintex_p6.png
- Saintex/pp-schema/saintex_p7.png
- Saintex/pp-schema/saintex_p8.png
- Saintex/pp-schema/saintex_p9.png
- Saintex/saintex-schema/saintex.html
- Saintex/saintex-schema/saintex_p1.png
- Saintex/saintex-schema/saintex_p10.png
- Saintex/saintex-schema/saintex_p11.png
- Saintex/saintex-schema/saintex_p12.png
- Saintex/saintex-schema/saintex_p13.png
- Saintex/saintex-schema/saintex_p14.png
- Saintex/saintex-schema/saintex_p15.png
- Saintex/saintex-schema/saintex_p16.png
- Saintex/saintex-schema/saintex_p17.png
- Saintex/saintex-schema/saintex_p18.png
- Saintex/saintex-schema/saintex_p19.png
- Saintex/saintex-schema/saintex_p2.png
- Saintex/saintex-schema/saintex_p3.png
- Saintex/saintex-schema/saintex_p4.png
- Saintex/saintex-schema/saintex_p5.png
- Saintex/saintex-schema/saintex_p6.png
- Saintex/saintex-schema/saintex_p7.png
- Saintex/saintex-schema/saintex_p8.png
- Saintex/saintex-schema/saintex_p9.png
- dh89/atrace.txt
- dh89/cordial2lexico.dic
- dh89/cordial2lexico.loc.sr
- dh89/cordial2lexico.num
- dh89/cordial2lexico.par
- dh89/cordial2lexico.txt
- dh89/cordialCateg.txt
- dh89/cordialFormCat.txt
- dh89/cordialForme.txt
- dh89/cordialLemCat.txt
- dh89/cordialLemme.txt
- dh89/cordial_format1.txt
- dh89/cordial_format2.txt
- dh89/cordial_format3.txt
- dh89/cordial_format4.txt
- dh89/cordial_format5.txt
- dh89/dh89.htm
- dh89/dh89.png
- dh89/dh89.xml
- dh89/dh89Articles.cnr
- dh89/dh89Articles.txt
- dh89/dh89ArticlesEtiq3.txt
- dh89/dh89-schema/dh89.html
- dh89/dh89-schema/dh89_p1.png
- dh89/dh89-schema/dh89_p2.png
- dh89/dh89-schema/dh89_p3.png
- dh89/dh89-schema/dh89_p4.png
- dh89/dh89-schema/dh89_p5.png
- dh89/dh89-schema/dh89_p6.png
- dh89/dh89-schema/dh89_p7.png
- dh89/dh89-schema/dh89_p8.png
- dh89/dh89-schema/dh89_p9.png
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
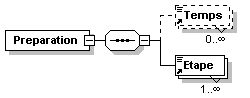{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Ressources pour les COURS/TDs
- bibliographie.dtd
- bibliographie.htm
- bibliographie.png
- bibliographie.xml
- bibliographie.xsl
- bibliographieTypee.dtd
- bibliographieTypee.xml
- bibliographieTypee.xsl
- france-inter980428-v2.xml
- france-inter980428.xml
- france-inter980428.xsl
- p96-2001-precordial.cnr-avantcorrection
- p96-2001-precordial.cnr-corrige
- p96-2001-precordial2xml.xml
- repertoire.dtd
- repertoire.xml
- repertoire.xsl
- repertoireSF-2.html
- repertoireSF-2.xsl
- repertoireSF.dtd
- repertoireSF.xml
- repertoireSF.xsl
- saintex-cordial2xml.xml
- saintex-francais.cnr
- saintex-francais.txt
- trans-13-v2.dtd
- trans-13.dtd
{kind=link}
Le père duchesne
- Présentation : Corpus Historique associé à Lexico1/2/3
- version TXT
- version XML (extrait) établie par O. Rincon Becerra (Etudiant du secteur TAL)
- Corpus XML complet en ligne (sur le site pereduchesne) établie par O. Rincon Becerra (Etudiant du secteur TAL), Père Duchesne : Corpus XML en ligne (ressources locales)
- Corpus XML complet en ligne avec étiquetage établie par O. Rincon Becerra (Etudiant du secteur TAL), Corpus XML complet en ligne avec étiquetage (ressources locales)
- version HTML
- version catégorisée pour Lexico3 avec forme, catégorie et lemme(1)
- version catégorisée pour Lexico3 avec forme, catégorie et lemme(2)
Site Web Lexico 3
- Présentation : ce document XML rassemble toutes les pages construites sur le site de Lexico3 (préparation réalisée via les outils du projet TypWeb)
- version XML tous les accents ont été supprimés
La bête humaine
- Présentation : ...
- version XML (à corriger sur certains caractères)
Corpus Boeing
- Présentation :
- Le corpus traité ici a été construit à partir des ressources textuelles disponibles sur le Web à l'adresse suivante : http://www.boeing.com/news/speeches/current/archive.html. Cette page est une des pages du site du constructeur d'avion américain Boeing. Elle regroupe des discours de dirigeants de la société aéronautique. Nous avons dans un premier temps traité l'ensemble des données disponibles sur cette page pour constituer un corpus de référence (le corpus XML infra). Nous avons ensuite extrait de ces données un ensemble de textes corresponadnt à certains auteurs. Le site Boeing a été partiellement aspiré à partir de la page d'entrée des discours. Cette aspiration a été réalisé avec l'aspirateur "Web Devil 5.0" sous Macintosh. L'arborescence initiale du site (à partir de la page d'entrée donnée) a été reconstitué localement. A partir de cet état off-line du corpus, nous avons utilisé des outils existants pour normaliser et archiver ces données. Ces outils sont intégrés dans un prototype de manipulation de données textuelles qui regroupent des outils utilisés par exemple dans la gestion de corpus construit sur Internet. Cet outil, nommé MKCORPUS, permet de réaliser des opérations élémentaires sur des corpus textuels. Il permet aussi de générer, à partir d'un corpus aspiré sur le Web, un corpus normalisé (au format XML) de ce corpus initial. Pour les textes (1) et (3) on dispose d'un extrait du corpus complet, il regroupe les interventions d'un seul intervenant sur plusieurs mois et sur plusieurs années (1998-2000).
- Descriptif du codage utilisé pour ces fichiers: Chaque balise (que l'on appelle via le nom utilisé par l'item nomBalise) est construire de la manière suivante : <nomBalise=valeurBalise>. Les valeurs des balises utilisées sont les suivantes.
- La balise aut est associé à l'auteur du discours.
- La balise autanregroupe les informations suivantes : auteur, date (année)
- La balise anaut regroupe les informations suivantes : date (année), auteur
- La balise autanmois regroupe les informations suivantes : auteur, date (année, mois)
- La balise anmois regroupe les informations suivantes : date (année, mois)
- La balise an regroupe les informations suivantes : date (année)
- Les majuscules ont été recodées sous la forme suivante : le caractère * suivi de la même lettre en minuscule. Chaque paragraphe est introduit via le caractère §.
- version TXT (1) (balisée pour Lexico3) une partie des interventions du site XML complet
- version TXT partie textuelle du corpus XML infra
- version HTML (3) une partie des interventions du corpus XML infra
- version XML le site des archives de Boeing construit via les outils Typweb
Corpus Prématurés 1996
- Prématurés 1996 version HTML complète locale (préparation initiale Benoît Habert)
- Prématurés 1996 version HTML complète avec rapport d'analyse complet (responsable Benoît Habert)
- Plusieurs versions sont utilisables :
- la première, brute (p96.tab), est issue d'un tableur (un tableur manipule des cellules organisées en lignes et colonnes, et permet de faire calculer la valeur d'une cellule à partir du contenu d'une ou de plusieurs autres cellules). C'est la version qui a été constitué dans le service de réanimation néonatale à partir des fiches papier remplies par les infirmières. Dans ce fichier, le nombre débutant la ligne concatène le numéro de bébé, celui du jour de l'observation et celui de l'observation dans la journée.
- la seconde (p96.bal) nomme les différentes informations contenues dans une fiche sur un bébé un jour donné à un moment déterminé. On dispose aussi de (p96.fic) qui regroupe toutes les fiches. Enfin, on dispose de (p96.tag) qui correspond à une version étiquetée du corpus bébé
- La première version (p96.tab) est disponible (au format HTML) : visualisation p96tab.htm.
- La seconde version (p96.bal) est disponible (au format HTML) : visualisation p96bal.htm.
- La première version (p96.tab) est disponible (au format TXT) : visualisation p96.tab.
- La seconde version (p96.bal) est disponible (au format TXT) : visualisation p96.bal.
- La version (p96.fic) est disponible (au format TXT) : visualisation p96.fic.
- La version (p96.tag) est disponible (au format TXT) : visualisation p96.tag.
Les 4 derniers fichiers dans une archive : Prem96.zip
- Pour la visualisation des versions textuelles brutes, une étape de téléchargement est parfois nécessaire. Si tel est le cas placer le fichier cherché dans votre envirionnement de travail avant de le manipuler.
- Présentation de la version hypertextuelle
- la présentation générale du corpus
- les précisions sur l'état de départ du corpus
- les indications sur la prématurité
- Plusieurs versions distinctes du corpus sont données :
- par bébé (avec indication du jour et de l'observation) ;
- par infirmière ;
- catégorisé par un étiqueteur avec les catégories mises en évidence par des changements de couleur (visualisables ou non selon la machine utilisée) ou par des changements de police (gras, italiques, etc.).
- Versions complémentaires
- version XML du site Prématurés 96 (local) construit avec les outils typweb
- version catégorisée pour Lexico3 (forme, catégorie, lemme) - contient des parties textuelles relatives aux corpus bébé (corpus pour SLOV5/6)
- version catégorisée pour Lexico3 (forme, catégorie, lemme) du corpus XML précédent (corpus pour SLFN7/8)
- Présentation des versions textuelles
Corpus Prématurés 2000
- Présentation : voir la présentation faite sur le site infra
- version complète et rapport d'analyse (responsable Benoît Habert)
La déclaration des droits de l'homme 1789
- Présentation : ...
- version TXT
- version HTML
- version XML
- version catégorisée pour Lexico3
shakespeare 2000
- Présentation : nous reproduisons ici le contenu de la présentation faite par l'auteur dans la distribution de ces textes
- a_and_c.xml
- all_well.xml
- as_you.xml
- com_err.xml
- coriolan.xml
- cymbelin.xml
- dream.xml
- hamlet.xml
- hen_iv_1.xml
- hen_iv_2.xml
- hen_v.xml
- hen_vi_1.xml
- hen_vi_2.xml
- hen_vi_3.xml
- hen_viii.xml
- j_caesar.xml
- john.xml
- lear.xml
- lll.xml
- m_for_m.xml
- m_wives.xml
- macbeth.xml
- merchant.xml
- much_ado.xml
- othello.xml
- pericles.xml
- r_and_j.xml
- rich_ii.xml
- rich_iii.xml
- t_night.xml
- taming.xml
- tempest.xml
- timon.xml
- titus.xml
- troilus.xml
- two_gent.xml
- win_tale.xml
Jon Bosak (bosak@eng.sun.com)
July 15, 1999This is shaksper.200, a set of the plays of William Shakespeare marked up for electronic publication. The set began as ASCII files put into the public domain by Moby Lexical Tools in 1992. They were marked up in 1992 as a beginner's exercise in SGML DTD and stylesheet design (originally using the DynaText proprietary stylesheet language) and in 1996 were released along with a companion set of publicly available religious texts as the earliest examples of real documents marked up in (early) XML. The current distribution conforms to the XML 1.0 Recommendation released February 8, 1998.
Caveat regarding Shakespeare scholarship
Every time I have occasion to compare the text of these files with a modern edition of Shakespeare (usually when someone points out a problem that requires me to check against a printed text), I wonder where in the world the Moby folks got the original. They must have used OCR to scan in a printed edition that had gone out of copyright, which means that the source could have been published no later than World War I. My guess is that it was a late Victorian edition, but it might have been much older.
In any case, the editorial style of the set is very different from that of modern editions, and on general principles I strongly doubt the critical accuracy of the text. The set is provided, as it always has been, purely as a learning exercise in SGML/XML markup, as a benchmark for comparing the performance of SGML/XML processors, and as a resource for testing stylesheet and search methodologies. The text is enjoyable reading, but the present edition should not be relied upon for scholarly purposes.
Copyright
While the text has been in the public domain since 1992, the status of the markup hasn't been clear. For purposes of legal simplicity (I think), I'm now asserting copyright over the markup to discourage the circulation of variant versions while still allowing free distribution. Each play now includes the following notice:
ASCII text placed in the public domain by Moby Lexical Tools, 1992.
SGML markup by Jon Bosak, 1992-1994.
XML version by Jon Bosak, 1996-1999.
The XML markup in this version is Copyright © 1999 Jon Bosak. This work may freely be distributed on condition that it not be modified or altered in any way.What's new
Unlike the companion 2.x version of the religious texts, Shakespeare 2.00 does not differ significantly from the previous release, version 1.10. The main difference is that the DTD and the XML declarations have at last been revised to conform to the final XML 1.0 Recommendation. I've also corrected about 50 lines of bad tagging in Henry IV Part 2 (Act 2, Scene 1) and de-Americanized the spelling of the word "Labour" in the title "Love's Labour's Lost" (yes, there are properly two apostrophes!). My thanks to Michael Kay for pointing out these errors. None of the changes should significantly affect comparisons with processing tests run against earlier versions.
I had originally intended to supply a set of DSSSL stylesheets for the plays just as I did for the religious texts -- hence the delay in making this set available. I have given up on finding the time to do this right now. Hopefully I will include stylesheets in a future release; I have left in a few small ancillary files in anticipation of this.
Manifest
This distribution includes the following files, all of which should be installed in the same directory:
shaksper.htm this file play.dtd DTD for testaments scripts for batch validation using nsgmls: vs a bash script for validating a play as SGML vx a bash script for validating a play as XML ancillary files left in for future DSSSL processing (these are not needed for most generic XML processing): catalog SGML Open (OASIS) catalog for public identifiers dsssl.dtd DSSSL DTD fot.dtd FOT (flow object tree) DTD style-sheet.dtd DTD for DSSSL stylesheets xml.dcl XML SGML declaration xml.soc XML catalogthe plays are the thing:
Running the scripts
The files in this set were built and tested in Windows 95 using scripts running under the Gnu bash shell. DOS batch files should work equally well, but I don't have the patience to deal with them.
Assuming that nsgmls (part of the Jade distribution) has been installed and is in the search path, the scripts named vs and vx are typically run under bash like this:
for i in *.xml; do echo $i; vs $i; done for i in *.xml; do echo $i; vx $i; doneThe first command line performs a validity check of all the plays as SGML files, and the second performs a validity check of all the plays as XML files. Note that both scripts change the values of SP environment variables.
Jon Bosak
Los Altos, California
July 1999
Ressources sur le web
- Le grand dictionnaire terminologique (http://www.granddictionnaire.com/)est un ouvrage de référence unique rassemblant un fonds terminologique d'envergure de 3 millions de termes français et anglais dans 200 domaines d'activité. Il est le compagnon indispensable de tous ceux et celles qui doivent traduire, réviser ou rédiger des textes impeccables. Elaboré et produit par l'office de la langue francaise
- Le TLF : le Trésor de la Langue Française Informatisé http://atilf.atilf.fr/. INCONTOURNABLE
- Le dictionnaire de l'Académie : http://atilf.atilf.fr/academie9.htm. "La rencontre entre une tradition de plusieurs siècles et l'informatique n'allait pas de soi", a reconnu Hélène Carrère d'Encausse, secrétaire perpétuel de l'Académie, lors de la présentation, jeudi 24 juin, de la version informatisée du dictionnaire. Mais elle a salué une "initiative qui marque une date pour la lexicographie française".
- Dicos en tout genre : http://www.dicorama.com
- Encyclopédie en ligne entièrement gratuite (Editions Atlas) : http://www.webencyclo.com
- Textes en lignes (2600 œuvres du XVIème au XXème) en français et en anglais : http://humanities.uchicago.edu/ARTFL/ARTF.html
- Archivage de données linguistiques textuelles et sonores : Le Programme Archivage (sur le site du LACITO). "Le Programme Archivage a pour but : (1) L'archivage de documents linguistiques associant son et texte dans un format qui en assure la pérennité et l'accessibilité (2) La diffusion de tels documents dans le monde scientifique, ou chez les populations concernées. (3) Le développement de formats et d'outils informatiques. Les documents archivés, pour la plupart des enregistrements de parole spontanée dans des langues sans écriture, ont servi, et servent encore, de base aux recherches sur les langues et les cultures concernées. L'aspect texte des documents comprend, au minimum, la transcription et la traduction libre, et souvent des gloses interlinéaires. Des méthodes de codage et d'exploitation informatique de documents texte/son synchronisés ont été développés selon les normes informatiques internationalement reconnues, XML et Unicode. L'utilisateur accède simultanément aux données sonores et textuelles, en utilisant un browser standard. L'architecture du système est conçue pour être indépendante de la plate-forme et de tout logiciel propriétaire. Par ailleurs, les outils, scripts, feuilles de style, applets, etc., développés par le programme Archivage sont ouverts et librement disponibles. Les documents archivés peuvent être soit consultés en ligne soit téléchargés pour une consultation en local ou pour des traitements non prévus sur notre serveur."
- BIBELEC : Bibliothèque Electronique des Etudiants (http://www.bibelec.com). Un outil de recherche avancée est désormais disponible sur la Bibelec. Il vous permet d'affiner vos requêtes selon les critères de votre choix (mots clés, nom de l'auteur, matière, type de document et langue) tout en personnalisant l'affichage et le tri des résultats.
- Une grammaire en ligne : http://www.fse.ulaval.ca/fac/grammaire-bepp/
- 450 bases de données gratuites sur internet : http://urfist.univ-lyon1.fr/gratuits/index.html
- LITTERALIA. Un répertoire très complet des éditeurs francophones (plus de 600 d'entre eux sont recensés), avec accès à leur site web, information sur les salons du livre, les programmes littéraires à la télévision, etc. Lien :http://www.francofil.net/fr/bibliotheques/biblilibr_fr.html
- RÉPERTOIRE DES BASES DE DONNÉES BIBLIOGRAPHIQUES ET FACTUELLES SUR INTERNET. Cette page réalisée par un professionnel québécois de la bibliothéconomie, recense discipline par discipline, puis commente, toutes les bases de données scientifiques accessibles sur Internet. (http://www.francofil.net/fr/bibliographie/busqgen_fr.html)
- RÉPERTOIRE DES BASES DE DONNÉES BIBLIOGRAPHIQUES ET FACTUELLES SUR INTERNET. Cette page réalisée par un professionnel québécois de la bibliothéconomie, recense discipline par discipline, puis commente, toutes les bases de données scientifiques accessibles sur Internet. (http://www.francofil.net/fr/bibliographie/busqgen_fr.html)
- GRAND DICTIONNAIRE TERMINOLOGIQUE DE LA LANGUE FRANÇAISE. Résultat des travaux de l'Office de la langue française (Québec), le GDT est un outil incomparable pour les traducteurs, terminologues et linguistes. Ses notices français-anglais sont consultables gratuitement en ligne. En prime, le téléchargement d'un petit outil permet d'accéder facilement, depuis son ordinateur, à une multitude d'autres ressources linguistiques. (http://www.francofil.net/fr/fle/refdic_fr.html)
- INSTITUT NATIONAL DE LA LANGUE FRANÇAISE (INALF). L'INaLF a développé des programmes de recherche sur la langue française, principalement sur son vocabulaire. Les données (lexicales et textuelles), traitées par des systèmes informatiques spécifiques et originaux, portent sur divers registres du français: langue littéraire (du XIVe au XXe siècle), langue courante (écrite, parlée), langue scientifique et technique (terminologies), régionalismes. Plusieurs bases de données, telles que Frantext (textes littéraires) et Borneo (néologismes), sont à la disposition des chercheurs moyennement abonnement. D'autres sont réservées. (http://www.francofil.net/fr/fle/reslin_fr.html)
- CATALOGUE CRITIQUE DES RESSOURCES TEXTUELLES SUR INTERNET (CCRTI).Ce catalogue, réalisé par l'Institut National de la Langue Française (INALF), a pour but d'aider les internautes en quête de textes littéraires en langue française à sélectionner, parmi les nombreux sites qui diffusent des ressources textuelles en ligne sur la Toile, ceux qui présentent les caractères les plus sérieux tant sur le plan du traitement éditorial que numérique des textes. (http://www.francofil.net/fr/fle/reslit_fr.html)
- Linguistic Data Consortium (UPENN)
- CRATER Multilingual Aligned Annotated Corpus
- British National Corpus (BNC)
- WordNet An Electronic Lexical Database
- Verb Index of [Beth Levin 93] L'index du livre English Verb Classes And Alternations: A Preliminary Investigation de Beth Levin
- The SGML/XML Web PageStandard Generalized Markup Language & Extensible Markup Language
- TEI Home Page Text Encoding Initiative
- Rank Xerox Europe Research Centre
- Hyperbase (Etienne Brunet - laboratoire Bases, corpus et langage
- Summer Institute of Linguistics, pointeurs vers logiciels
- Base de données lexicales CELEX(at LDC)
- Étiqueteur du français(Université de Caen) CAEN
- Étiqueteur et parseur de l'anglais Helsinki tools
- Base de données lexicales, segmenteur... MULTEXT
- Distribution SMART (ftp)
- Langage de requête pour SGML SgmlQL
- Concordance sur textes divers
- Voycabulary : online dictionnary/thesaurus reference tool
- Clicnet : site culturel et francophone, ressources virtuelles en français
- ABU : Association des Bibliophiles Universels
- Dictionnaire des synonymes univ-caen
- WWWebster Dictionary/Thesaurus- Search screen
- Electronic Dictionaries
- Dictionnaires français sous forme électronique (état des ressources)
- Serveur Interactif pour la Langue Française, son Identité, sa Diffusion et son Etude
- INALF
- Encyclopédie Universalis (La plus complète...))
TEXTES DIVERS
- Textes en Français
- ARTFL Project : Recueil de textes appartenant au "trésors de la langue française".
- Club des Poètes : Poésie, Spectacles, Literature
- Shakespeare : Les oeuvres complètes de Shakespeare.
- ARTFL Project: French-English Dictionary Form : Un dictionnaire Français - Anglais.
- The WWW Bible Gateway : La bible en Allemand, Suédois, Latin, Français, Espagnol, ...
- Ethnologue Database : Pas de texte, mais des renseignements concernant les langages : géographie, d&ecacute;mographie, ....
- Linguistics Resources
