Cahier Des Charges
Définitions générales du projet Barrage
Il s'agit d'un script, en Perl ou en Bash, qui va prendre en entrée un fichier .txt dans lequel se trouvent des liens ordonnés pointant sur des sites contenant des informations relatives au mot barrage. Un seul lien pour chaque ligne du fichier, en d'autres termes, chaque lien est séparé par un retour-chariot. Le script devra pouvoir parcourir ce fichier, téléchargé les fichiers pointés par ces liens, les transformer en fichier .txt sans les balises, et enfin chercher un aperçu contenant l'occurence du mot barrage ainsi que son contexte. Le résultat sera présenté sous forme d'un tableau dans un fichier .html, composé de 4 colonnes, comprenant respectivement pour chaque ligne le lien original pointant sur un site, le lien pointant sur le fichier téléchargé correspondant, le lien pointant sur le fichier .txt correspondant, et enfin l'aperçu.
Notons une petite remarque concernant le processus d'automatisation. Il n'est pas possible de le rendre exhaustif. L'utilisateur devra intervenir à un moment ou à un autre. Ici, nous voyons clairement que l'utilisateur doit au préalable créer le fichier contenant la liste d'URLs qui l'interessent. Nous pourrions automatiser ceci également, mais il faudra tout de même bien définir quelles pages sont susceptibles d'être pertinantes ou non. Ce qui introduit évidemment une notion de sémantique dans ce référentiel, impossible à automatiser à 100%
Ce sont là, les principales fonctions du script. Cette définition est ouverte à toutes les optimisations possibles, parfois réalisées, parfois omises. Nous les définirons plus loin. Avant ceci, regardons de plus près l'environnement de travail, véritable carcan imposé dans le cadre de ce projet.
L'arborescence de travail
L'arborescence de travail, ainsi que ses répertoires sont précisément définis.
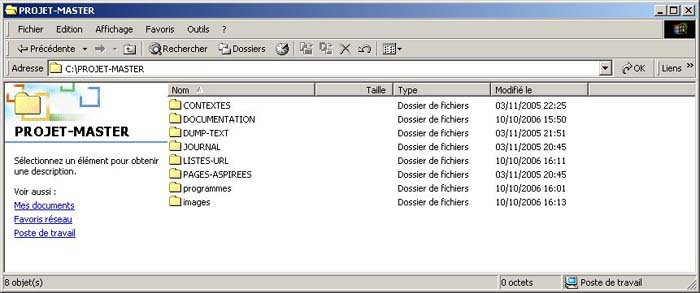
CONTEXTES: Ce repertoire contiendra les fichiers (si ils existent) relatifs à l'aperçu contenant le mot barrage et son contexte.
DOCUMENTATION: Contient toute la documentation, la page que vous visualisez en fait partie.
DUMP-TEXT: Contient le texte débalisé des pages téléchargées.
JOURNAL: Le journal de la constitution du projet, les traces interessantes à laisser.
LISTES-URL: Contient le ou les fichiers texte où sont stockés les listes d'URLs.
PAGES-ASPIREES: Contient les pages qui ont été téléchargées.
programmes: Contient le script, ainsi que le tableau html qu'il va produire.
images: Contient les diverses images nécessaires, comme celle que vous voyez juste au dessus.
optimisations diverses
Examinons les optimisations possibles, de la visibilité du résultat produit à la gestion d'erreurs éventuels. Traitées ou non, il demeure tout de même intéressant de les examiner.
Portabilité du code
La notion de portabilité d'un code se doit d'être définie succintement. Le script peut éventuellement être exporté sur d'autres machines, avec un système d'exploitation différent ou non, une architecture différente ou non, à des niveaux différents de l'arborescence de la machine, et peut être appellé de n'importe où dans cette arborescence. Si le programme respecte à 100% tous ces critères, on dira qu'il est portable partout sans exceptions. Mais en général, ce n'est jamais le cas, et seulement deux ou trois de ces conditions sont traités. Ce sera hélas, également le cas ici.
Présentation du résultat
En examinant le sujet, il est évident qu'il est offert une liberté relativement importante quant à la présentation du résultat. Il s'agit ici d'un simple tableau en html, rien de plus n'est précisé, ce qui laisse alors la porte ouverte aux âmes les plus imaginatives. Neanmoins, il ne faudrait guère oublier les considérations passées en standard, de lisibilité, de clarté et de ce qui est conforme à une morale générale. Il n'est pas question d'ajouter des éléments choquants, aussi efficace et esthétiques qu'ils soient.
Cela n'empèche pas certaines optimisations, comme par exemple établir plusieurs pages pour le tableau, qui afficheraient 20 lignes à la fois seulement, toutes liées entre elles de manières doublement chainées (pensez aux listes doublement chainées en C), qui pointeraient sur la page précédente et la page suivante seulement. Il est évident qu'un tableau de 1500 lignes est intraitable et indigeste pour l'estomac de notre cerveau.
On peut également réfléchir au design du tableau, avec un formatage de caractère, ou insérer des éléments graphiques. Mais la faisabilité de ce genre de chose est limitée par la structure du script qui le réalise. Nous le verrons en quoi.
Gestion d'erreurs diverses
Nous allons scinder les erreurs en deux catégories: celles liées à l'utilisateur et celles qui ne le sont pas.
Erreurs liées à l'utilisateur
Le script va demander l'intervention de l'utilisateur à deux reprises. Premièrement, il faudra qu'il indique le nom du fichier qui contient la liste d'URLs. Deuxièmement, il devra donner le nom du fichier html qui sera produit en résultat.
Pour ce qui est du fichier-liste, il se peut que l'utilisateur donne un nom erroné pour des raisons aussi diverses que variées (faute de frappe, inattention, Pedro le chat sur le clavier...). Que se passe-t-il dans ce cas là ? Comment le script devra réagir ?
Il peut également pour les même raisons (non pas Pedro le chat...) d'entrer un nom de fichier qui ne correspondra pas à la norme de nom de fichier du système d'exploitation.
Le script utilise la notion de chemin relatif, et abuse de la notion de répertoire courant. Par défaut, il considère qu'il a été appelé à partir du repertoire /programmes de l'arborescence de travail, qui sera donc considéré comme le répertoire courant. Mais rien n'empêche l'utilisateur (sur un OS-UNIX en tout cas) de l'appeler d'ailleurs en lui indiquant le chemin, et le repertoire courant ne sera pas le même. Résultat, ce sera la débandade...
Erreurs non-liées à l'utilisateur
Mis à part la panne de courant qui vous a fait perdre tout le travail de l'après midi car évidemment, vous n'avez pas sauvegardé avant, quels sont les facteurs extérieurs qui peuvent poser problème ?
"Le script va télécharger des pages webs". Oui, mais des pages webs, il en existe de plusieurs types. Et l'outil qu'on utilisera pour cette tâche ne fonctionne bien qu'avec les pages en HTML pur. Que ce passe-t-il si la page est en php sur base de données SQL, ou si elles utilisent des scripts obscures que nul ne connaît ? Parfois cela fonctionne, et parfois pas. Cela dépend de facteurs échappant à notre volonté et de ce fait, il est difficile de gérer cette erreur.
Dans le même registre, les redirections pourront également poser problème dans certains cas, mais pas dans d'autres. La préoccupation est que ce genre de procédés ne sont pas des exceptions, et demeurent largement implantés dans toute la toile.
Il ne faut pas oublier les liens qui ne fonctionnent plus du tout, pour lesquels le serveur qui hébergent la page en question est en panne, ou encore la page en elle-même n'est plus présente sur le dit serveur.