Démarche de travail
Le résumé de trois mois de travail... acharné !
L’idée principale était de trouver un terme polysémique afin d’en discerner les différents emplois et contextes d’utilisation. Et ce n’est pas une mince affaire…
Après moult réflexions sur les quelques mots que nous avions sélectionnés, notre choix s’est finalement arrêté sur le mot
Il faut dire que cela tombait sous le sens (!) :ses principales significations sont plutôt facilement isolables, permettant alors une meilleure manipulation du mot par la suite ;
au vu de leur nombre, il était possible de les traiter en totalité et donc d'obtenir un aperçu global et complet du mot (enfin presque…) ;
de plus, ce mot illustre à lui seul les phénomènes d’homonymie et de polysémie.
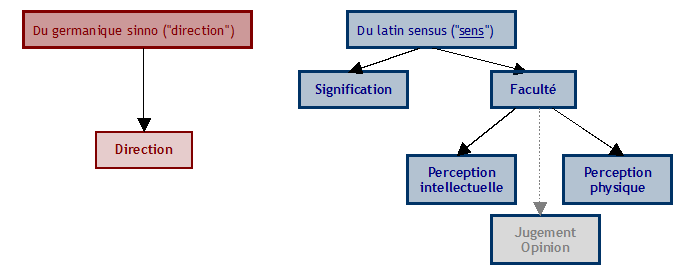
En tant que lexicographes amateurs, nous nous sommes basés sur plusieurs références et nous avons isolé cinq sens principaux (même si finalement nous n’avons gardé que les quatre premiers) :
Représentation arborescente des sens du mot "sens"
A partir de ces différents sens, nous avons commencé la fameuse étape de traduction. Pour ne pas tomber dans les méandres de la polysémie à l’intérieur des autres langues, nous avons tout de suite écarté les termes dont les sens ne correspondaient pas à ceux définis en français (notamment grâce à Ultralingua).
Cela nous a également permis de déterminer directement les contextes non voulus pour la future recherche d’URLs.
Propositions de traduction du mot
En ce qui concerne le chinois, le sinogramme
En effet, on a besoin d’au moins deux caractères pour former une des significations du mot "sens" vues précédemment, c’est-à-dire une unité qui possède un signifié plein.
Pour les sens physiques, le caractère "pivot" estsens gustatif =
sens de la vue =
Puisque nous n’avions pas défini les différents sens par domaine, nous avons fait en sorte de les regrouper dans notre sélection.
Par exemple, pour « direction », le contenu des URLs traite aussi bien de l’électricité (sens du courant), de la mécanique (sens d’un vecteur), que de la circulation (sens unique).
Enfin, de façon à obtenir un plus bel aperçu de la langue et de son emploi, nous avons tenté de diversifier le type de pages Web récupérées : articles encyclopédiques, études, actualités, blogs, forums…
Pour cela, nous avons également voulu diversifier l’utilisation des moteurs et méta-moteurs de recherche (bien que nous soyons tous trois adeptes de la recherche par Google).
Mais dans la jungle du Web, il n’est pas toujours aisé de trouver ce que l’on cherche, surtout avec un mot polysémique ! Il nous a donc fallu, en plus d’une bonne dose de patience, une attention toute particulière pour utiliser "le" bon mot et "les" bons termes associés pour obtenir le contexte voulu. Afin de travailler de façon plus claire et plus simple, nous avons regroupé toutes nos recherches dans un fichier Excel.
(2) Pour ce qui est des "sens extra-sensoriels", nous avons dû nous résigner à ne prendre que quelques expressions, car il était très difficile d’en retrouver plusieurs sur une même page ! Même le recours à la numérologie n’a pas payé...!
De plus, pour une même signification, l’allemand utilise dans ses mots composés différents mots pour représenter "sens" : la recherche a été donc d’autant plus minutieuse. On rejoint donc ici la problématique posée par le chinois.
Script de création de l'environnement de travail
Résultat de la création des répertoires
Nous avons décidé d’organiser nos URLs par langue, et dans chacun des répertoires, les URLs sont rassemblées par sens :
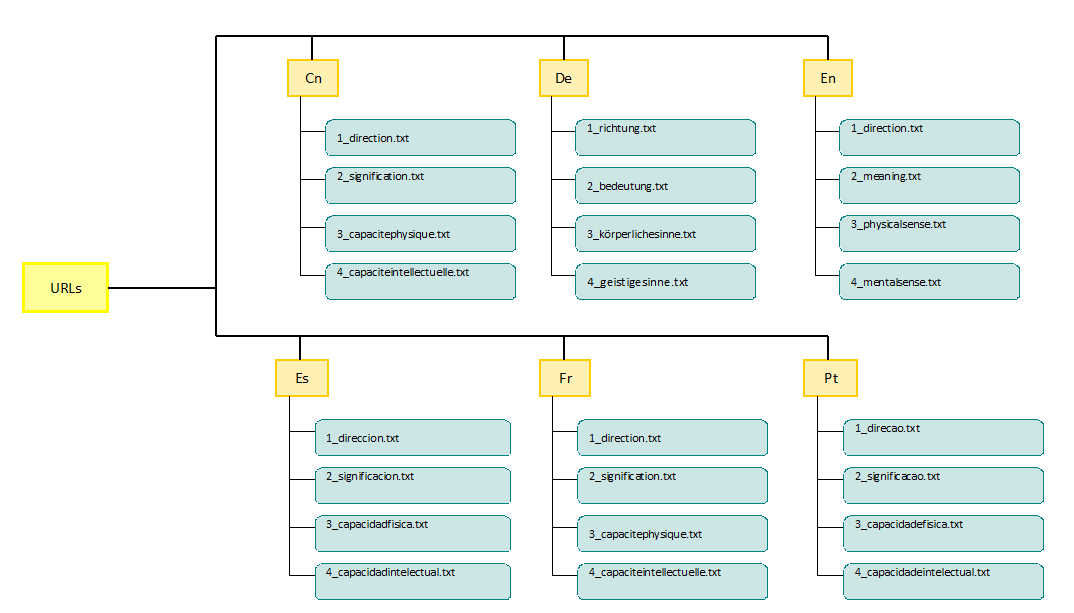
Arborescence du répertoire d'URLs
Pour plus de précisions sur les commandes utilisées dans les explications qui vont suivre, un lien cliquable leur est associé et renvoie à leur description de la partie FAQ.
Au final, nous devons créer un grand tableau, subdivisé par langue, et composé de 5 colonnes :La 1ère rassemble les différentes URLs, classées par sens dans chaque tableau (puisque nous avons nos URLs regroupées dans un fichier par sens, et ces fichiers regroupés dans un répertoire par langue) ;
La 2nde regroupe les pages aspirées localement ;
La 3ème regroupe le contenu textuel brut de chaque page aspirée ;
La 4ème et la 5ème regroupent les contextes du mot "sens" en format texte et en format HTML pour les rendre plus lisibles grâce à la mise en forme.
Pour nous faciliter la tâche, nous avons décidé d’automatiser la production des tableaux : pour cela, nous avons inséré une feuille de style CSS, qui détaille les caractéristiques des futurs tableaux : taille des cellules et du tableau, bordures, couleurs, polices, etc.
A partir de là, il suffit simplement d’introduire les balises HTML de colonnes (<td> </td>) et de lignes (<tr> </tr>) au moment où l’on veut rediriger les résultats des commandes, dont nous allons détailler le fonctionnement ci-dessous.
Dans la dernière version du script, nous avons intégré le CSS du tableau à la feuille de style générale du site, et modifié les paramètres pour que le script génère un joli tableau assorti au reste du site ! (plus exactement, le script génère la page tablo.html entière).
Afin d’anticiper les problèmes possibles d’encodage des caractères, nous avons utilisé une commande
S’il n’y a pas d’encodage spécifié, le script considérera un encodage par défaut, ISO-8859-1 (c’est-à-dire Latin-1), car c’est l’encodage le plus souvent utilisé dans nos pages (d'après nos vérifications).
Ce sera au moment de la récupération du texte brut (avec
ERROR 404
ERROR 403 : Forbidden
Voilà les erreurs que nous rencontrions chez nous pour les 3/4 des URLs si nous tentions d'aspirer les pages ! Frustrant...
C'est magnifique ! Enfin, en théorie.
Nous souhaitions à l'issue de cette étape ne plus travailler que sur du texte encodé en UTF-8. Plusieurs raisons ont motivé notre choix :l’encodage Unicode attribuant un point de codage unique à chaque caractère, il permet de n'utiliser qu'un seul encodage pour afficher toutes nos langues (quand un encodage comme Latin-1 ne nous aurait pas permis d'afficher des caractères chinois, et un encodage chinois comme GB-2312 des caractères latins accentués) ;
depuis le début du script, nous écrivons tout en UTF-8 : les commandes, le contenu des variables (donc les motifs à chercher plus tard dans les dumps), le code HTML du tableau final, etc ; d'où l'intérêt d'utiliser le même encodage dans les dumps pour ne pas avoir de "bizarreries d'affichage" à un quelconque endroit de la chaîne.
A l’aide de la commande
Le réencodage des dumps a été une étape laborieuse dans l'écriture du script. En effet, la commande
Oui mais non : dans la réalité, cette fonctionnalité n'est pas tout à fait au point, notamment quand on lui demande de réencoder des caractères chinois codés sur plusieurs octets. Et rajouter l'option "-display_charset=UTF-8" n'arrange rien à l'affaire.
Nous en sommes donc venu à nous tourner vers
La méthode est peut-être un peu laborieuse, mais le résultat est là ! Tout fonctionne !
Pour cela, un gigantesque
Les motifs (expressions régulières) :
Ensuite, nous avons créé deux types de fichiers de résultats : l’un en texte brut, qui nous servira pour les nuages de mots, et l’autre en HTML, pour pouvoir mettre en relief les mots recherchés.
La commande
Ainsi, pour prélever les occurrences des encodages sur les pages aspirées (et ce sans tenir compte de la casse), nous avons dû abandonner l'option
Il semble que ce bug ne soit plus présent dans les dernières versions de Cygwin, mais nous avons conservé la commande en l'état, pour que notre script tourne sans erreur à l'ILPGA (où les versions de Cygwin sont plus anciennes).
Ce type de problème s'est révélé en anglais, espagnol, français et portugais, qui utilisent fréquemment le même mot pour exprimer les différents sens. En outre, sur un corpus contenant autant d'URLs (plus de 200), cet inconvénient était tout simplement inévitable. Mais qu'importe : nous avons décidé d'implanter une sorte de dictionnaire des formes interdites dans le script !
Ainsi, nous avons ajouté à notre déjà gigantesque
Il nous semblait cependant intéressant de garder une trace de ces vilains "indésirables", qui prouvent que l'extraction automatique d'un motif précis n'est pas une mince affaire ! Aussi, plutôt que de ne pas les récupérer, nous avons décidé de les signaler grâce à des avertissements bien visibles dans les fichiers de contextes en HTML (en utilisation la commande
\!/ Attention ! Mon dictionnaire me dit que cette forme ne correspond sûrement pas au sens recherché ! Mais je peux me tromper... \!/
Trouver les formes à exclure s'est fait en deux étapes :
A partir de ces deux différentes concaténations, il sera possible de voir le contraste entre le nuage de mots propre au contexte et celui qui regroupe tous les mots de la page Web.
Nous avons fait deux types de concaténation, selon le nuage que l’on veut obtenir :Concaténation par sens à l’intérieur de chaque langue (dans la troisième boucle for)


Concaténation de tous les sens par langue (dans la deuxième boucle for, les fichiers concaténés par sens sont concaténés entre eux pour chaque langue)


Pour pouvoir être traités par le TreeCloud, ces fichiers sont ensuite nettoyés de leurs signes de ponctuation avec la commande
Pour stocker les fichiers ainsi créés, nous avons agrandi l’arborescence avec un dossier NUAGES, qui regroupe un répertoire par langue contenant les fichiers concaténés par sens (commandes
La commande
Le problème des applications existantes est qu'elles ne savent pas où placer les frontières de mots en chinois, puisqu'elles ne peuvent pas utiliser les blancs typographiques pour se repérer. Il faudrait donc qu'elles puissent intégrer un dictionnaire de tous les sinogrammes pour fonctionner correctement.
Pour les mêmes raisons, nous n'avons pas pu obtenir de nuages pour le chinois avec les autres applications.
Comme vous pourrez le constater, le résultat obtenu avec les dumps est bien différent de celui des fichiers de contextes : ils sont "parasités" par des mots n'ayant aucun rapport avec le sens étudié (voire même des mots d'une autre langue !) et le mot "sens" n'est pas forcément celui qui est le plus représenté !
Étapes initiales
À la recherche DU mot…
Pour pouvoir partir du bon pied dans cette aventure, il nous fallait choisir LE bon mot, celui qui allait nous occuper tout au long du semestre.L’idée principale était de trouver un terme polysémique afin d’en discerner les différents emplois et contextes d’utilisation. Et ce n’est pas une mince affaire…
Après moult réflexions sur les quelques mots que nous avions sélectionnés, notre choix s’est finalement arrêté sur le mot
sens
.Il faut dire que cela tombait sous le sens (!) :
En tant que lexicographes amateurs, nous nous sommes basés sur plusieurs références et nous avons isolé cinq sens principaux (même si finalement nous n’avons gardé que les quatre premiers) :
- 1. "Direction" : Dans quel sens est-ce que je dois tourner ?
- 2. "Signification" : Le mot "sens" possède plusieurs sens.
- 3. "Faculté"
- a. "capacité de perception physique" : Mon sens de l'odorat est très développé !
- b. "capacité de perception intellectuelle" : J'ai un super sens de l'humour.
- c. "jugement, opinion" : Je vais dans ton sens.
Représentation arborescente des sens du mot "sens"
A partir de ces différents sens, nous avons commencé la fameuse étape de traduction. Pour ne pas tomber dans les méandres de la polysémie à l’intérieur des autres langues, nous avons tout de suite écarté les termes dont les sens ne correspondaient pas à ceux définis en français (notamment grâce à Ultralingua).
Cela nous a également permis de déterminer directement les contextes non voulus pour la future recherche d’URLs.
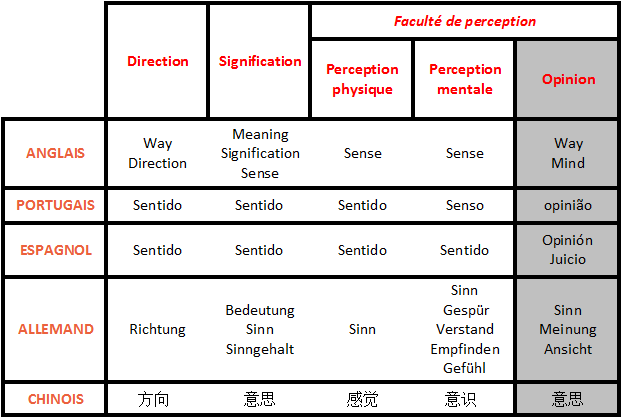
Propositions de traduction du mot
En ce qui concerne le chinois, le sinogramme
意
joue le rôle de « pivot » pour les traductions de signification et de perception mentale : il permet de représenter la partie sémantique commune sans pour autant signifier à lui seul "sens".En effet, on a besoin d’au moins deux caractères pour former une des significations du mot "sens" vues précédemment, c’est-à-dire une unité qui possède un signifié plein.
Pour les sens physiques, le caractère "pivot" est
觉
:味觉
;视觉
Embûche 1 :
Après avoir longuement trituré ce mot dans tous les sens (c’est le cas de le dire…), nous avons décidé de rallier le sens de jugement/opinion sous le sens de faculté (défini par le TFLi comme « manière de juger »). Bien qu’intuitivement une expression comme « aller dans ce sens » laisse à penser qu’il y aurait une idée de mouvement, ce n’est pas le cas pour « à mon sens » ou « en un sens », dont le sémantisme laisse clairement penser à une idée de capacité à voir les choses d’une certaine façon. On ne pourrait donc penser que cette signification découle de l’étymologie de « sens, direction ».Embûche 2 :
Finalement, après de multiples recherches d’urls, nous nous sommes rendu compte que ce 5ème sens posait énormément de problèmes quant à la traduction en espagnol, portugais, allemand et chinois, où il perd énormément de sémantisme (car plutôt apparenté au terme « opinion ») ; quant au français et à l’anglais, il n’est représenté que par deux ou trois expressions idiomatiques (« à mon sens », « in my way »), qui ne seraient pas du tout intéressantes à traiter… En effet, elles apparaissent comme connecteurs dans les discours et ce dans n’importe quel domaine : il n’y a donc aucun intérêt pour leur contexte linguistique ! Voir aussi ce post sur le blog, où nous en avions discuté._______________________
La récolte des URLs
En vue de la finalité du projet, à savoir la détection automatique des contextes linguistiques où apparaissent les différents sens de notre mot, nous avons cherché à rapatrier des urls contenant le maximum de collocations et de termes associés.Puisque nous n’avions pas défini les différents sens par domaine, nous avons fait en sorte de les regrouper dans notre sélection.
Par exemple, pour « direction », le contenu des URLs traite aussi bien de l’électricité (sens du courant), de la mécanique (sens d’un vecteur), que de la circulation (sens unique).
Enfin, de façon à obtenir un plus bel aperçu de la langue et de son emploi, nous avons tenté de diversifier le type de pages Web récupérées : articles encyclopédiques, études, actualités, blogs, forums…
Pour cela, nous avons également voulu diversifier l’utilisation des moteurs et méta-moteurs de recherche (bien que nous soyons tous trois adeptes de la recherche par Google).
Mais dans la jungle du Web, il n’est pas toujours aisé de trouver ce que l’on cherche, surtout avec un mot polysémique ! Il nous a donc fallu, en plus d’une bonne dose de patience, une attention toute particulière pour utiliser "le" bon mot et "les" bons termes associés pour obtenir le contexte voulu. Afin de travailler de façon plus claire et plus simple, nous avons regroupé toutes nos recherches dans un fichier Excel.
Embûche 3 :
(1) Pour le français notamment, il nous a fallu parcourir manuellement chaque page afin de vérifier qu’il ne s’y trouvait pas plusieurs significations de "sens" à l’intérieur du texte, ce qui aurait totalement biaisé nos contextes…(2) Pour ce qui est des "sens extra-sensoriels", nous avons dû nous résigner à ne prendre que quelques expressions, car il était très difficile d’en retrouver plusieurs sur une même page ! Même le recours à la numérologie n’a pas payé...!
Embûche 4 :
D’ailleurs, de ce côté-là, l’allemand nous en a fait voir de toutes les couleurs… C’est en effet une langue où la plupart des mots sont composés et il est alors quasi impossible de trouver ce que l’on cherche avec la "simple" traduction de "sens" !De plus, pour une même signification, l’allemand utilise dans ses mots composés différents mots pour représenter "sens" : la recherche a été donc d’autant plus minutieuse. On rejoint donc ici la problématique posée par le chinois.
_______________________
Création de l'environnement de travail
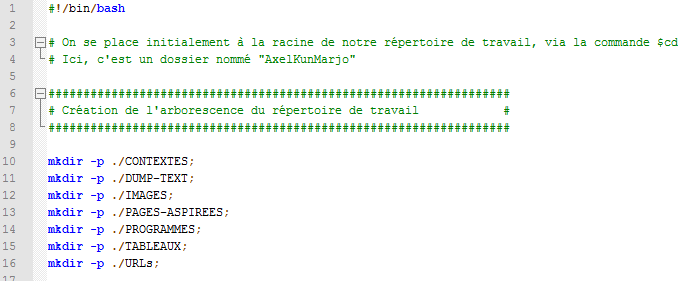
Les commandesmkdir
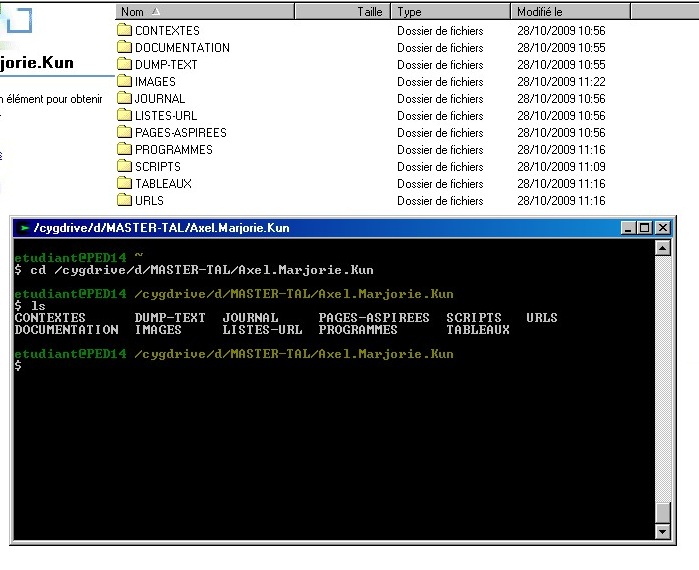
situées au début de notre script, nous ont permis de créer notre arborescence de travail :Script de création de l'environnement de travail
Résultat de la création des répertoires
Nous avons décidé d’organiser nos URLs par langue, et dans chacun des répertoires, les URLs sont rassemblées par sens :
Arborescence du répertoire d'URLs
______________________________________________________________
Phase 1/ Automatisation des tâches
Après avoir créé notre arborescence, nous sommes passés à l’élaboration du script qui nous permettra de présenter dans les différentes langues, sous forme de tableaux en HTML, les liens cliquables des URLs, des pages aspirées, des textes brut ("dump") et des contextes du mot "sens" dans ses différents emplois.Pour plus de précisions sur les commandes utilisées dans les explications qui vont suivre, un lien cliquable leur est associé et renvoie à leur description de la partie FAQ.
_______________________
Création d’un tableau en HTML
Afin de classer les futurs résultats, il nous a fallu créer un tableau en HTML à l’intérieur de notre script bash.Au final, nous devons créer un grand tableau, subdivisé par langue, et composé de 5 colonnes :
Pour nous faciliter la tâche, nous avons décidé d’automatiser la production des tableaux : pour cela, nous avons inséré une feuille de style CSS, qui détaille les caractéristiques des futurs tableaux : taille des cellules et du tableau, bordures, couleurs, polices, etc.
A partir de là, il suffit simplement d’introduire les balises HTML de colonnes (<td> </td>) et de lignes (<tr> </tr>) au moment où l’on veut rediriger les résultats des commandes, dont nous allons détailler le fonctionnement ci-dessous.
Dans la dernière version du script, nous avons intégré le CSS du tableau à la feuille de style générale du site, et modifié les paramètres pour que le script génère un joli tableau assorti au reste du site ! (plus exactement, le script génère la page tablo.html entière).
_______________________
Aspiration locale des pages : WGET
Après avoir redirigé le lien de chaque URL ligne par ligne (avec la deuxième bouclefor
), la commandewget
nous a permis d’automatiser l’aspiration des pages des différentes URLs sélectionnées, ainsi que leur enregistrement sur le disque local, dans le répertoire PAGES-ASPIREES préalablement créé.Afin d’anticiper les problèmes possibles d’encodage des caractères, nous avons utilisé une commande
egrep
pour récupérer l’encodage utilisé dans la page aspirée.S’il n’y a pas d’encodage spécifié, le script considérera un encodage par défaut, ISO-8859-1 (c’est-à-dire Latin-1), car c’est l’encodage le plus souvent utilisé dans nos pages (d'après nos vérifications).
Ce sera au moment de la récupération du texte brut (avec
lynx
) que ce procédé trouvera toute son utilité. Cependant, un bug de la commandeegrep
sous Cygwin nous a quelque peu compliqué la tâche.Embûche 5 :
Nous avons eu quelques problèmes d’aspiration "inexplicables", dans le sens où le script fonctionnait parfaitement à l’ILPGA, mais pas tout à fait correctement en rentrant bidouiller at home…ERROR 404
ERROR 403 : Forbidden
Voilà les erreurs que nous rencontrions chez nous pour les 3/4 des URLs si nous tentions d'aspirer les pages ! Frustrant...
_______________________
Récupération du texte brut des pages ("DUMP") : LYNX
La commandelynx
permet de récupérer le contenu textuel de la page aspirée et une redirection vers un fichier texte sauvegarde ces données dans le répertoire DUMP.C'est magnifique ! Enfin, en théorie.
Nous souhaitions à l'issue de cette étape ne plus travailler que sur du texte encodé en UTF-8. Plusieurs raisons ont motivé notre choix :
iconv
, nous avons donc réencodé tous les fichiers de texte brut, en spécifiant à la commande l’encodage d’origine récupéré dans la partie précédente (mémorisé sous la variable $encodage), et l'encodage de sortie : UTF-8.Embûche 6 :
Pourquoi faire simple, quand on peut faire compliqué ?Le réencodage des dumps a été une étape laborieuse dans l'écriture du script. En effet, la commande
lynx
nous a posé beaucoup de problèmes. Son comportement par défaut est d'encoder le dump en UTF-8. Magnifique, me direz-vous !Oui mais non : dans la réalité, cette fonctionnalité n'est pas tout à fait au point, notamment quand on lui demande de réencoder des caractères chinois codés sur plusieurs octets. Et rajouter l'option "-display_charset=UTF-8" n'arrange rien à l'affaire.
Nous en sommes donc venu à nous tourner vers
iconv
pour prendre le relai. Et pour éviter quelynx
ne tente de passer tous les dumps en UTF-8 en les corrompant, nous avons rajouté l'option "-display_charset=$encodage" pour que les fichiers de texte créés soient maintenus dans l'encodage d'origine des pages aspirées.La méthode est peut-être un peu laborieuse, mais le résultat est là ! Tout fonctionne !
_______________________
Récupération du contexte de sens dans le texte brut : EGREP
Avant de récupérer les contextes voulus du mot "sens" par la commandeegrep
, il nous a fallu définir les motifs propres à chaque langue.Pour cela, un gigantesque
if
distribue des motifs (variable $motif) et des définitions (variable $def) par langue et par sens. La visualisation de la définition se fera dans le fichier de contexte en HTML.Les motifs (expressions régulières) :
- 1/ Français : tout simplement (\b)sens(\b), puisque nous ne voulions pas récupérer de dérivés dont la signification pourrait être attachée à une autre signification de "sens" (par exemple, il est possible de trouver dans une même page le mot "sens" dans une signification précise, et également des mots comme "sensibilité" ou "sensation" qui n’auraient pas forcément de rapport).
- 2/ Anglais : les mots représentant "sens" diffèrent selon les significations, et nous avons donc plusieurs termes à rechercher pour extraire les contextes. Ils peuvent tous comporter éventuellement un "s" au pluriel (pour représenter l’optionalité : …s?) et pour la signification de "direction", il est possible de trouver des mots composés : pour retrouver widthway(s) ou one-way par exemple, on utilisera (\b)(\w)+-ways?(\b).
- 3 / Allemand : puisque la quasi-totalité des mots sont des formes composées (à partir d’un pivot représentant "sens" dans ses différentes significations) et que ces mêmes mots, suivant leur position dans la phrase, sont marqués d’un cas différent, on utilisera une expression régulière qui ne
comporte pas de délimitation de mot (pas de (\b)), c’est-à-dire les mots eux-mêmes; afin de les récupérer en entier, nous avons entouré le motif recherché par l'expression régulière (\w)*. Pour éviter le silence dans les résultats, nous avons anticipé des erreurs d’accents sur les voyelles ü et ä
(peu probables toutefois, sauf si l’encodage d’origine n’était pas adapté) : Gesp(ü|u)r. Nous avons également ajouté quelques expressions spécifiques n’utilisant pas le pivot attendu.
- 4 / Chinois : les caractères ne sont pas non plus délimités puisqu’ils peuvent se retrouver attachés dans des mots plus grands, et ce à n’importe quel endroit. Comme indiqué plus haut, il y a également un motif par sens, selon le sinogramme "pivot" attendu et les signes qui le suivent.
- 5 / Espagnol : comme en français, une seule forme recoupe tous les sens envisagés : sentido(s). Les seules contraintes à fixer sont de ne pas récupérer des mots composés (souvent par préfixation, comme resentido) et de permettre le pluriel, d'où l'expression régulière : (\b)sentidos?.
- 6/ Portugais : de la même façon qu'on espagnol, on recontre la forme sentido(s) pour tous les sens sauf pour celui de "capacité intellectuelle", où on trouve plutôt senso(s). Mêmes contraintes qu'en espagnol, ce qui donne l'expression régulière : ((\b)sentidos?|(\b)sensos?).
Ensuite, nous avons créé deux types de fichiers de résultats : l’un en texte brut, qui nous servira pour les nuages de mots, et l’autre en HTML, pour pouvoir mettre en relief les mots recherchés.
La commande
egrep
va rechercher les motifs spécifiés précédemment (stockés dans la variable $motif) et envoyer son résultat à la commandesed
, qui va mettre le motif en forme et séparer les contextes (composés d’une ligne au-dessus et d’une ligne en-dessous) par des sauts de ligne pour que le tout soit plus lisible.Embûche 7 :
Un bug deegrep
sous Cygwin empêche que l'on puisse utiliser les options-i
(insensible à la casse) et-o
(prélever les occurrences du motif) en même temps.Ainsi, pour prélever les occurrences des encodages sur les pages aspirées (et ce sans tenir compte de la casse), nous avons dû abandonner l'option
-i
et réécrire les expressions régulières pour rajouter manuellement toutes les combinatoires possibles. Fastidieux !Il semble que ce bug ne soit plus présent dans les dernières versions de Cygwin, mais nous avons conservé la commande en l'état, pour que notre script tourne sans erreur à l'ILPGA (où les versions de Cygwin sont plus anciennes).
_______________________
Bonus $dico !
En toute fin de projet, nous avons constaté que certaines formes non-désirées étaient prélevées dans plusieurs pages, et ce malgré nos efforts préalables pour filtrer leur contenu (choix de pages ne contenant qu'un seul des sens recherchés, expressions régulières précises et peu "gourmandes", etc).Ce type de problème s'est révélé en anglais, espagnol, français et portugais, qui utilisent fréquemment le même mot pour exprimer les différents sens. En outre, sur un corpus contenant autant d'URLs (plus de 200), cet inconvénient était tout simplement inévitable. Mais qu'importe : nous avons décidé d'implanter une sorte de dictionnaire des formes interdites dans le script !
Ainsi, nous avons ajouté à notre déjà gigantesque
if
une variable $dico qui liste grâce à des expressions régulières les formes que l'on ne voudrait idéalement pas repêcher dans les pages pour chaque sens dans chaque langue.Il nous semblait cependant intéressant de garder une trace de ces vilains "indésirables", qui prouvent que l'extraction automatique d'un motif précis n'est pas une mince affaire ! Aussi, plutôt que de ne pas les récupérer, nous avons décidé de les signaler grâce à des avertissements bien visibles dans les fichiers de contextes en HTML (en utilisation la commande
sed
) :\!/ Attention ! Mon dictionnaire me dit que cette forme ne correspond sûrement pas au sens recherché ! Mais je peux me tromper... \!/
Trouver les formes à exclure s'est fait en deux étapes :
- 1/ En anticipant des phénomènes d'homonymie, comme en français par ex, où "sens" est aussi le verbe "sentir" à la première et deuxième personne du singulier du présent de l'indicatif ;
- 2/ En vérifiant chaque page de contextes obtenue, pour trouver manuellement, au cas par cas, les indésirables restant
______________________________________________________________
Phase 2/ Création des nuages de mots
Étape préparatoire
Avant tout chose, il nous fallait concaténer les fichiers dump (contenu textuel entier des pages aspirées) et les fichiers texte des contextes où apparaît le mot "sens" (d’où l’intérêt de les avoir gardés au chaud, malgré la version html des contextes) à l’aide de la commandecat
.A partir de ces deux différentes concaténations, il sera possible de voir le contraste entre le nuage de mots propre au contexte et celui qui regroupe tous les mots de la page Web.
Nous avons fait deux types de concaténation, selon le nuage que l’on veut obtenir :
Pour pouvoir être traités par le TreeCloud, ces fichiers sont ensuite nettoyés de leurs signes de ponctuation avec la commande
sed
et convertis en ISO-8859-1, en dehors du script.Pour stocker les fichiers ainsi créés, nous avons agrandi l’arborescence avec un dossier NUAGES, qui regroupe un répertoire par langue contenant les fichiers concaténés par sens (commandes
mkdir
au début de la deuxième bouclefor
: pour chaque $fichiersens d’URLs de chaque $dossierlangue).La commande
rm
, placée en début de script dans l’étape dite « de préparation », permet d’effacer les fichiers concaténés s’ils existent déjà à chaque fois que l’on relance le script, et ainsi éviter la concaténation infinie… !_______________________
Les nuages
- Sous Wordle :
http://www.wordle.net/
C’est une application accessible via Internet qui permet de générer des nuages de tags (mots-clés) non dynamiques en fonction du contenu textuel ou d’une adresse de page Web que l’on lui donne.
Plus la fréquence d’un mot-clé est importante dans le texte, plus il apparaîtra grand. Quelques options permettent d’améliorer le rendu visuel du nuage selon ses propres goûts (couleurs, polices, direction des mots clés).
Embûche 8 :
Le site ne reconnaissant pas les caractères du chinois, nous avons cherché s’il existait des applications similaires sur des sites chinois. Malheureusement, après de nombreux mails envoyés et de recherches infructueuses, nous n’avons trouvé aucune solution…Le problème des applications existantes est qu'elles ne savent pas où placer les frontières de mots en chinois, puisqu'elles ne peuvent pas utiliser les blancs typographiques pour se repérer. Il faudrait donc qu'elles puissent intégrer un dictionnaire de tous les sinogrammes pour fonctionner correctement.
Pour les mêmes raisons, nous n'avons pas pu obtenir de nuages pour le chinois avec les autres applications.
- Sous TreeCloud :
http://www.lirmm.fr/~gambette/ProgTreeCloud.php
Cette application permet de construire des nuages arborés, pour, entre autres, visualiser le contenu global d'un texte (selon la fréquence des mots).
Nous l’avons utilisée pour créer les nuages à partir des fichiers concaténant les différents sens par langue (« nuage général par langue »). Nous avons ainsi obtenu deux nuages arborés par langue : celui des dumps, et celui des contextes. Au fil des branches, on voit ainsi se détacher différents regroupements de mots pour chaque sens.
- Sous Le Trameur :
Ce logiciel a pour objectif de compter les éléments (mots ou groupes de mots) d’un texte qu’il annote à l’aide de Treetagger, pour construire un système de coordonnées sur la séquence textuelle sous forme arborée.
Nous l'avons également utilisé pour obtenir une représentation arborée des polycooccurrents du mot "sens".
Comme vous pourrez le constater, le résultat obtenu avec les dumps est bien différent de celui des fichiers de contextes : ils sont "parasités" par des mots n'ayant aucun rapport avec le sens étudié (voire même des mots d'une autre langue !) et le mot "sens" n'est pas forcément celui qui est le plus représenté !