Préambule
Répertoire et arborescence de travail
Chaque dossier porte un nom donnant une indication sur le type de fichiers qu'il contiendra :
• Le dossier CONTEXTES regroupe les fichiers issus de l'extraction contextuelle par egrep des mots
traités dans les fichiers du dossier DUMP-TXT.
• Le dossier DUMP-TEXT regroupe les fichiers issus du traitement par lynx sur les pages aspirées
du dossier PAGES-ASPIREES.
• Le dossier PAGES-ASPIREES regroupe les fichiers issus de l'"aspiration" par wget des urls
contenues dans les fichiers situés dans le dossier URLS.
• Le dossier PROGRAMMES regroupe l'ensemble des scripts construits pour ce projet.
• Le dossier TABLEAUX regroupe l'ensemble des tableaux construits par les scripts, ces tableaux
regroupant in fine 4 colonnes : l'url initiale, la page aspirée, le dump textuel, le contexte.
• Le dossier URLS regroupe les fichiers contenant les urls à traiter.
• etc.
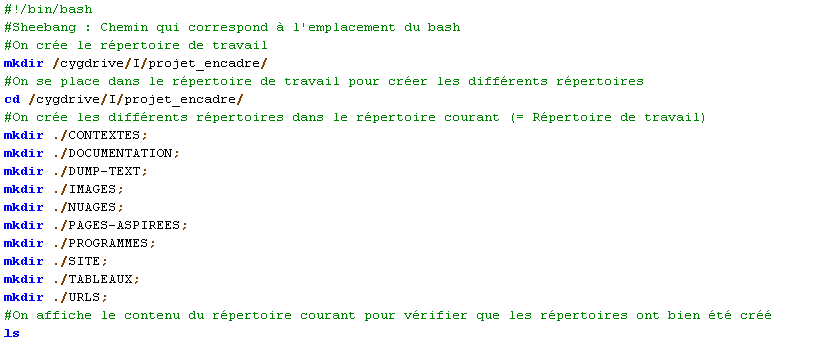
Création de l'arborescence de travail dans un script
En prenant comme modèle l'arborescence de travail décrite ci-dessus, on a écrit un script qui a construit cette arborescence.
Télécharger le script : prepare-environnement-projet.rar
On lance le script afin de créer l'arborescence. Pour cela, on se place dans le dossier qui contient le script :

On exécute le script :

Résultat :

