
Choix de la thématique et confection du corpus
Le choix d'une thématique pour le projet consistait à définir un thème et choisir un couple de langues (ou plus) sur lequel nous allions travailler. En repérant une cinquantaine d’URLs correspondant à la thématique choisie, il fallait constituer un ficher par langue au format TXT contenant les URLs des pages visées. Ces fichiers d’URLs seraient ensuite traités par une chaîne de traitement semi-automatique.
Lors de cette première phase, plusieurs idées ont été proposées. A titre d’exemple, la perception de la mort, les élections présidentielles et comment ces dernières sont vues dans différents pays, ainsi que le lien entre « république » et « démocratie » pour montrer la polysémie de ces concepts dans les langues choisies. Toutefois, après plusieurs discussions, nous avons décidé que notre thématique porterait sur le concept de l’américanisation tel qu’il est présenté dans la presse française, anglaise et grecque.
Pour plus de détails sur la question des choix des URLs, visitez notre blog !
Arborescence de travail
Dans le but de préparer notre environnement de travail, une arborescence de fichiers constituant le projet devait être créée ressemblant à la figure ci-dessous :

Chaque répertoire sert à contenir un type de fichier produit à chaque étape du projet :
Pour plus de détails sur la création de l'arborescence de travail, visitez notre blog !
Création d’un tableau de liens
Pour chaque langue les résultats de chaque étape du traitement sont présentés dans un seul tableau. A partir d'un répertoire de fichiers URLs, le premier script avait pour objectif de lire chaque ligne du fichier (correspondant à une URL) et d'écrire une première colonne contenant la liste de liens vers les pages web.
Plus de détails sur notre blog !
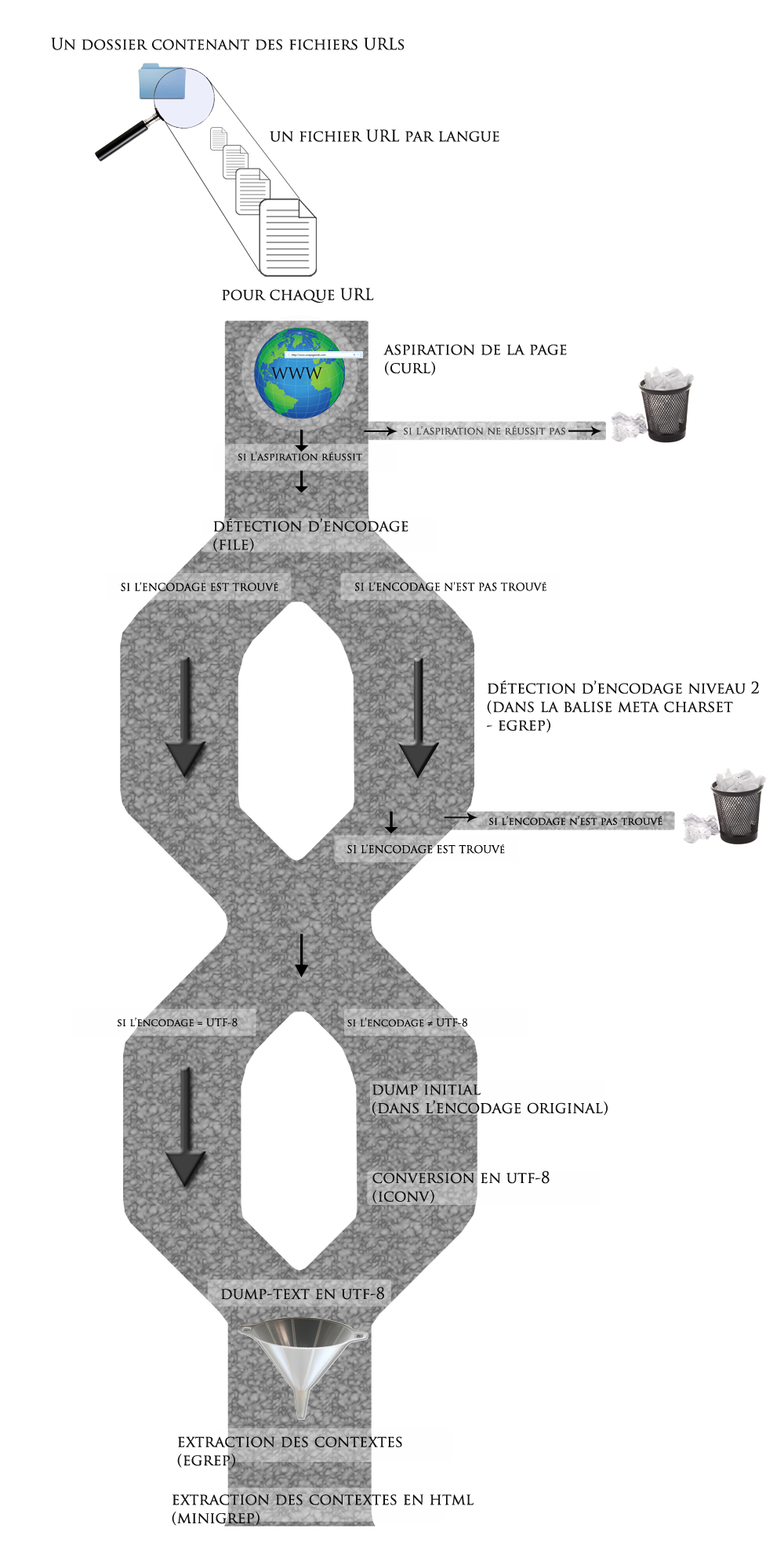
Aspiration des pages
L'aspiration des pages signifie le stockage local des pages web. Il existe deux commandes possibles pour effectuer l'aspiration : « wget » et « curl ». « Wget » s'est avérée moins performante que « curl », qui renvoyait moins d'erreurs.
La commande pour l'aspiration :
curl -s -o ./PAGES-ASPIREES/$filename/$i.html -w $link
où -s et -o sont les options « silencieux » et « output ». La première empêche le déroulement de « curl » d'être affiché dans le terminal. La seconde spécifie la sortie vers un endroit autre que STDOUT. A partir du lien vers le site ($link), la page était aspirée et stockée localement à l'endroit spécifié par le chemin.
Plus de détails sur notre blog !
Afin de pouvoir continuer le traitement à partir de ces pages aspirées, il fallait s'assurer que l'aspiration avait bien été effectuée. Le code retour de « curl » le permettant, nous l'avons récupéré en ajoutant le code suivant directement après la commande « curl » :
retourcurl=$?;
Pourtant, ce code ne suffisait pas, car il considérait que s'il y avait une réponse du serveur, la commande avait été effectuée correctement, malgré le fait que cette réponse puisse contenir un message d'erreur (ex: 404 Page not Found). Il était nécessaire de récupérer le code http pour vérifier les erreurs éventuelles. La commande « curl » dispose d'une option qui permet de renvoyer ce code que nous avons ajouté au code précédent :
retourhttp=$(curl -s -o ./PAGES-ASPIREES/$filename/$i.html -w %{http_code} $link); retourcurl=$?;
Pour les étapes suivantes, il était nécessaire de séparer les pages aspirées des pages non-aspirées, donc inexploitables. Un code retour de « curl » autre que 0 et un code http autre que 200 indiquaient une erreur et nous permettaient de faire ce tri.
Plus de détails sur notre blog !
Dump text
Le « dump text » est l'extraction du texte brut à partir de la page aspirée. Il s'agit de garder uniquement le texte du site, tel qu'il est affiché par le navigateur (sans les balises html). Cette étape utilise la commande dédiée « lynx -dump ».
lynx -dump -nolist -display_charset="$encodage" ./PAGES-ASPIREES/$filename/$i.html > ./DUMP-TEXT/$filename/$i-utf8.txt
Parmi les options figure -display_charset, qui permet de spécifier un encodage dans lequel sauvegarder le texte. Ceci est important car si un encodage n'est pas spécifié, le texte est « dumpé » dans l'encodage par défaut, et nous savions que les encodages des sites web ne sont pas tous identiques.
Alors, il a été d'abord nécessaire de détecter l'encodage des sites, pour ensuite effectuer l'extraction du texte. Il était important aussi de respecter l'environnement Unicode, afin d'obtenir pour chaque page un dump text en utf-8.
Si l'encodage était détecté comme étant de l'utf-8 (à un des deux niveaux), une extraction du texte brut était effectuée directement.
En revanche, si l'encodage n'était pas de l'utf-8, une conversion avec « iconv » était nécessaire. Un dump initial était effectué dans l'encodage initial et à partir de ce dump, le texte était converti en utf-8 sur la base de l'encodage détecté.
Dans le cas où la détection d'encodage échouait aux deux niveaux (c'est-à-dire que nous ne connaissions pas l'encodage), le fichier devenait inutilisable et il fallait abandonner la page. De même, si l'encodage était détecté mais n'était pas reconnu par « iconv », la page a dû être abandonnée.
Le résultat dans le tableau est une colonne pour le dump initial (si nécessaire) et une colonne pour le dump en utf-8.
Plus de détails sur notre blog !
Extraction des contextes
Cette étape consistait en l'extraction des contextes de notre motif choisi. En utilisant la commande « egrep », il était possible de rechercher et extraire uniquement les lignes du texte contenant un certain motif (défini par une expression régulière).
Avec cette expression régulière, il fallait résumer tous les mots associés avec l'américanisation (ex: américanisme, américanisé, américanisant...)
Le motif que nous avons choisi pour les trois langues est :
\b((am.ricani[sz])|(εξαμερικανισ)|(αμερικανοποί).*?)|(αμερικανισμός)\b
Pour chaque URL, le résultat de cette extraction était stocké dans un fichier texte dans le répertoire CONTEXTES.
egrep -i -n "\b((am.ricani[sz])|(εξαμερικανισ)|(αμερικανοποί).*?)|(αμερικανισμός)\b" ./DUMP-TEXT/$filename/$i-utf8.txt >> ./CONTEXTES/$filename/$i.txt;
Plus de détails sur notre blog !
Le résultat est une colonne dans le tableau avec un lien vers ce fichier. Nous avons aussi créé une colonne contenant le nombre d'occurrences du motif par page.
Une dernière étape était l'intégration du programme perl « minigrep » dans le script. « Minigrep » permet une présentation plus sophistiquée de cette étape. Le résultat est un fichier html avec une belle présentation des contextes, y compris les lignes précédentes et suivantes. Ces fichiers sont stockés dans le même répertoire que les fichiers textes et une colonne a été ajoutée au tableau avec des liens vers ces fichiers html.
Plus de détails sur notre blog !
Les nuages
La première étape de la phase 2 du projet consistait à faire des nuages de mots en utilisant des logiciels en ligne comme Wordle, Tagclouder ou WordItOut. Ces logiciels reposent sur la fréquence des mots dans le corpus et certains dépendent d’un dictionnaire qui permet à l'utilisateur d'éliminer les « mots vides » (en anglais "stop-words"). Les nuages servent ainsi à donner une représentation visuelle de la fréquence des mots qui apparaissent dans les contextes récupérés.
Plus de détails sur notre blog et les résultats via l'onglet Nuages !
Le Trameur
La seconde étape consistait à générer des nuages de mots contextualisés avec le Trameur. Le Trameur est un programme qui sert à l'analyse lexicométrique d'un texte. Il compte les unités d’un texte en tenant compte des éventuelles parties, afin d’évaluer par exemple l’évolution du vocabulaire dans une chronologie ou de comparer le vocabulaire des parties.
Plus de détails sur notre blog et les résultats via l'onglet Trameur !
Les problèmes principaux :