NÉGATION
Cette partie est consacrée à l'exploitation de nos corpus du point de vue de la négation. Après avoir présenté brièvement les raisons pour lesquelles nous nous intéressons à ce phénomène, nous montrons quelques données quantitatives obtenues à l'aide d'un script d'extraction et de calcul sur les phrases négatives. La suite de cette section présente les résultats d'une extraction de patrons grammaticaux relevant quelques aspects du phénomène de la négation.
Table des matières
Motivation
Pourquoi pas la négation?
Une observation des spécificités dans le corpus Discours à l'aide de Lexico3 révèle une forte disproportion dans l'emploi de la négation prédicative (identifiée d'après la fréquence des morphèmes ne et n) entre les différents candidats. Les fréquences relatives des formes ne, n et pas ainsi que le taux de la spécificité de chacune de ces formes pour chacun des candidats peuvent être bien observés que sur les graphiques suivants :
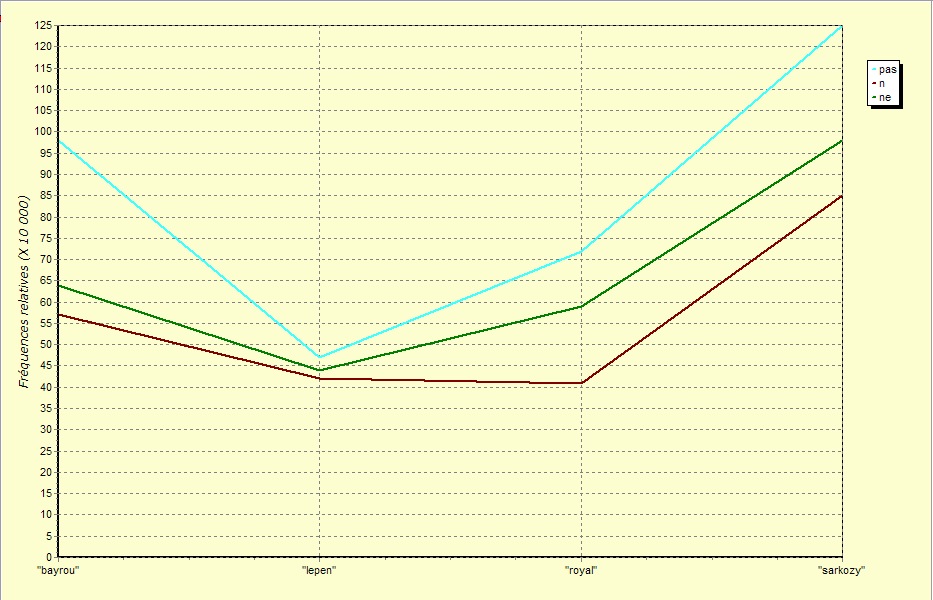
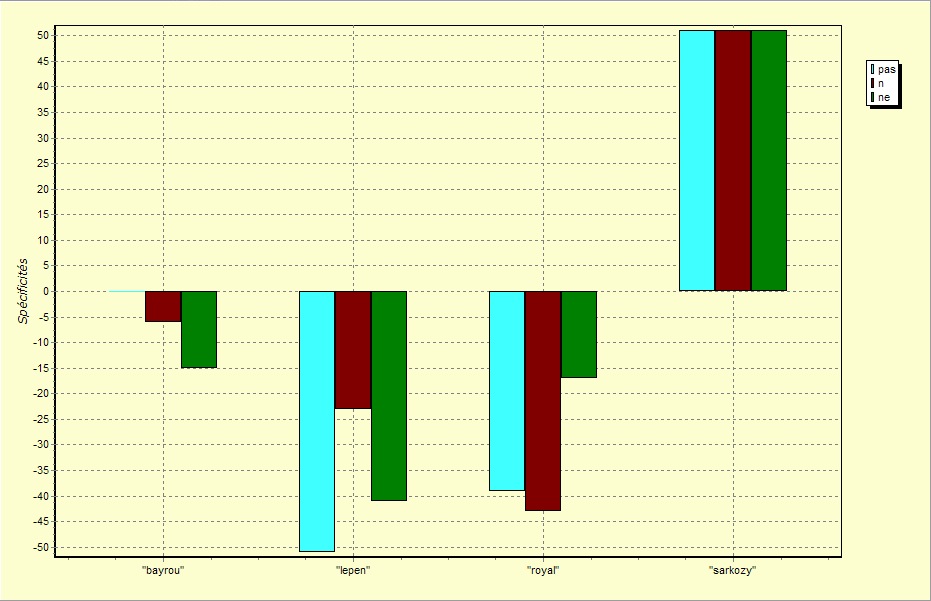
Nous n'allons pas faire une analyse des différents emplois de la négation qui peuvent être recensés dans notre corpus et nous n'essayerons pas non plus de les interpréter pour arriver à des conclusions qui ne seraient pas banales. Nous allons seulement extraire et présenter quelques informations que nous ne jugeons pas inintéressantes.
Définitions
Afin d'éviter toute confusion, nous devons définir les termes qui sont utilisés dans cet exposé :
- forme négative
- les suites de caractères ne ou n (morphème négatif). L'avantage de cette forme est qu'elle n'est pas ambiguë, nous pouvons alors baser notre extraction des phrases négatives sur la présence de cette forme dans une phrase donnée.
- phrase négative
- une suite de caractères terminée par un point (sous certaines restrictions, voir la problème de la segmentation en phrase dans la section Corpus) qui contient au moins une forme négative ne ou n.
Nous n'allons pas distinguer entre les différentes fonctions que peut avoir le morphème négatif : (1) négative ("Nous ne sommes pas d'accord !") ; (2) comparative ("Et en attendant, il faudra que l'Europe se protège et se protège beaucoup plus efficacement qu'elle ne le fait contre toutes ces formes de délocalisations et de destructions d'emplois, j'en fais ici le serment !") ; (3) explétive (Pierre a toujours peur que Marie ne s'en aille). - Rapport_ExtraitNeg_bayrou.txt
- Rapport_ExtraitNeg_lepen.txt
- Rapport_ExtraitNeg_royal.txt
- Rapport_ExtraitNeg_royal_db.txt
- Rapport_ExtraitNeg_sarkozy.txt
- Rapport_ExtraitNeg_sarkozy_db.txt
- Rapport_ExtraitNeg_pres.txt
- extraitNeg_bayrou.txt
- extraitNeg_lepen.txt
- extraitNeg_royal.txt
- extraitNeg_royal_db.txt
- extraitNeg_sarkozy.txt
- extraitNeg_sarkozy_db.txt
remonter
Extraction des phrases négatives
Script d'extraction
Nous étions intéressés par certaines informations liées à l'emploi de la négation (des formes négatives) dans nos corpus, notamment à la fréquence des phrases négatives et à la fréquence des formes négatives. Nous avons écrit un script Perl ExtraitNeg.pl (à télécharger ici) qui parcourt le fichier (contenant le texte brut segmenté en une phrase par ligne) passé en argument, imprime les phrases négatives extraites dans un fichier et imprime un rapport avec les informations suivantes :
Nombre de phrases dans le fichier Nombre de lignes vides Nombre de phrases négatives Pourcentage des phrases négatives Nombre de mots Nombre de formes négatives (ne ou n) Pourcentage des formes négatives (par rapport à la totalité des mots) Nombre moyen de formes négatives par phrase négative Phrase avec le plus de formes négatives
La boucle de lecture du fichier est la suivante :
foreach $ligne() { @slova = (); $j = 0; $jNeg = 0; if($ligne !~ /^$/) { $ph[$i] = $ligne; # EXTRACTION NEGATION if (($ligne =~ /.*\sne\s.*/) || ($ligne =~ /.*\sn'.*/)) { $phNeg[$iNeg] = $ligne; $iNeg++; print NEG $ligne; } chomp $ligne; $phlong[$i] = length($ligne); &Separate; @slova = split(/\s/,$ligne); foreach (@slova) { $mots[$k] = $_; $motslong[$k] = length($_); $k++; $j++; # EXTRACTION NEGATION if (($_ eq "ne") || ($_ eq "n")) { $kNeg++; $jNeg++; } } # EXTRACTION NEGATION if (($ligne =~ /.*\sne\s.*/) || ($ligne =~ /.*\sn\s.*/)) { $phnbNeg[$iNeg-1] = $jNeg; } $phnbmot[$i] = $j; $i++; } else { $iV++; } }
Cet algorithme, qui est basé sur la boucle du script StatsPhMot.pl utilisé pour les calculs dans la section Corpus (voir ici), structure les données dans la mémoire afin que l'on puisse extraire (par les calculs dans la seconde partie du script) les informations qui nous intéressent.
L'ensemble des rapports peut être visualisé ici :
Les fichiers contenant les phrases négatives de chaque candidat peuvent téléchargés ici :
remonter
Graphiques négation
Les informations extraites à l'aide du script décrit ci-dessus sont présentées à l'aide des graphiques dans la partie qui suit. Comme dans le cas des informations quantitatives concernant la longueur des phrases et des mots, nous n'allons pas interpréter les résultats.
La présence des formes négatives
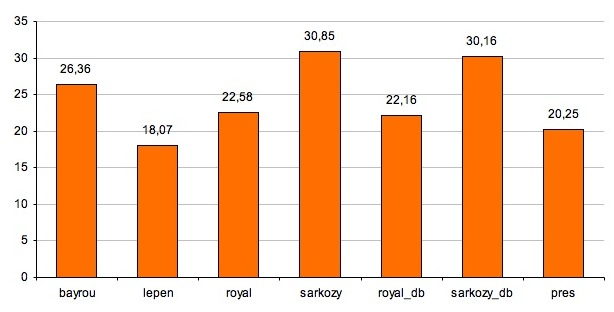
Le graphique suivant montre le taux de phrases négatives (contenant le morphème ne ou n) dans les partitions du corpus, c'est-à-dire que, par exemple, 26,36 % des phrases extraites des discours de Bayrou contiennent au moins un de ces morphèmes.
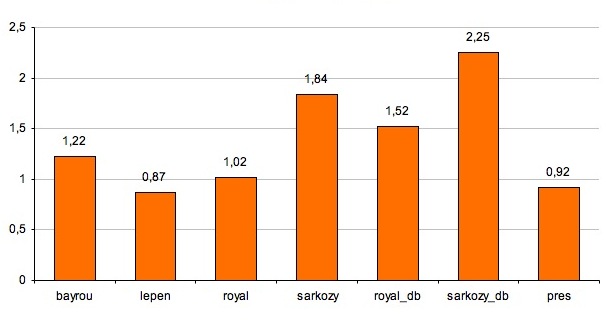
Le graphique suivant montre le taux de formes négatives (des morphèmes ne ou n) par rapport aux autres mots, c'est-à-dire que, par exemple, dans les discours de Bayrou, l'ensemble des formes ne ou n prononcées dans ses discours représentent 1,22 % de l'ensemble de tous les mots employés.
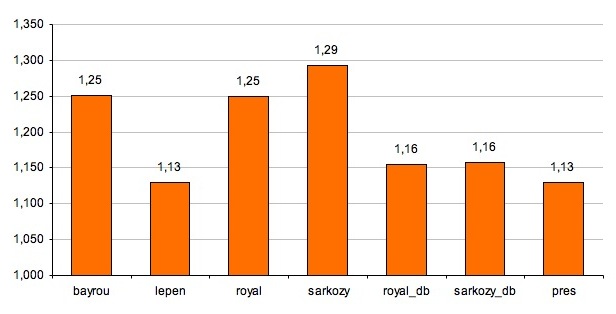
Le graphique suivant montre le nombre moyen de morphèmes ne ou n par une phrase négative, c'est-à-dire que, par exemple, une phrase négative dans les discours de Bayrou contient en moyenne 1,25 formes négatives. Ceci est un indice de la multiple négation utilisée dans une seule phrase (à ne pas confondre avec la double négation).
remonter
La longueur des phrases négatives
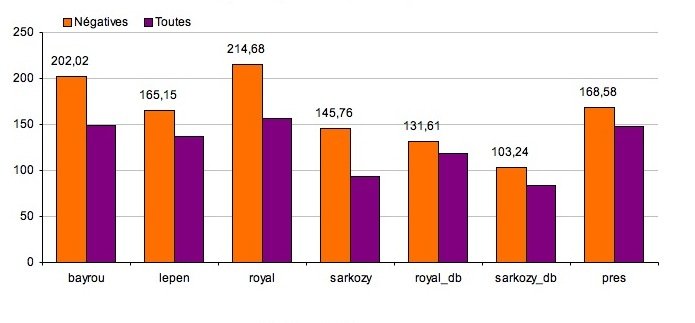
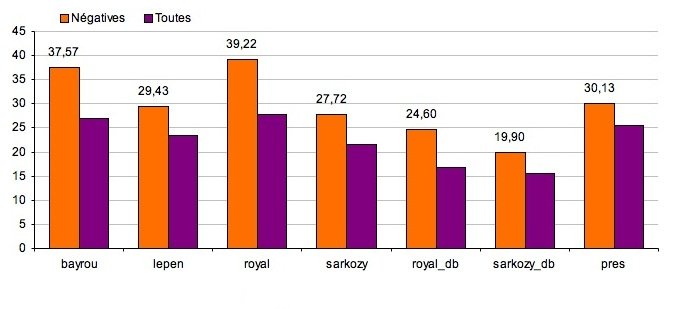
Les deux graphiques suivants montre la longueur moyenne d'une phrase négative en caractères et en mots en comparaison avec la longueur d'une phrase positive.
remonter
Extraction des patrons
Méthode
L'extraction des patrons et leur visualisation en forme de graphe avec le logiciel Pajek est une façon rapide et efficace d'exploiter un corpus.
En général, un patron peut être défini comme une suite de symboles (ou un motif) qui entre en correspondance avec certains tokens du corpus : par exemple, la suite des symboles maillot jaune (qui sont des tokens) est un patron qui est en correspondance avec toutes les suites de tokens maillot jaune présentes dans le corpus. L'extraction du patron maillot jaune aurait donc comme résultat la liste de toutes les occurrences de la suite de tokens maillot jaune dans le corpus.
La meilleure façon d'utiliser la méthode d'extraction des patrons est de se servir des suites des étiquettes linguistiques qui sont associées à chaque token (dans un corpus annoté morphologiquement, bien entendu). Ceci nous permet de faire abstraction de la forme des tokens et de travailler uniquement avec les catégories linguistiques. Dans ce cas, une suite de symboles Nom Adjectif (qui sont des étiquettes) est un patron qui permet d'extraire du corpus toutes les suites des tokens auxquelles sont associées les étiquettes correspondantes, c'est à dire par exemple maillot jaune, secrétaire nationale, étendards éternels, etc.
Si nous utilisons des patrons contenant les étiquettes linguistiques, nous sommes bien sûr à la merci des erreurs qui peuvent être faites par un étiqueteur (fausse attribution des étiquettes : du bruit ou du silence), néanmoins ceci est le prix à payer si nous voulons travailler avec des informations métalinguistiques générées automatiquement.
Le programme Pajek peut générer (à partir d'un fichier dans un format spécial) un graphe qui représente un ensemble des noeuds reliés par des arcs. Chaque noeud représente la valeur d'un token (ou de plusieurs tokens si leurs valeurs sont égales) qui a été extrait à l'aide d'un patron donné. Les arcs signifient que les deux noeuds qui sont reliés ensemble, sont membres de la suite (du couple) des tokens extraites du corpus. Pour donner un exemple, si avec un patron Nom Adjectif nous extrayons du corpus les suites maillot jaune, maillot blanc et étendards éternels, nous obtenons un graphe avec 5 noeuds (maillot, jaune, blanc, étendards, éternels) avec les arcs entre maillot et blanc, entre maillot et jaune, et finalement, entre étendards et éternels.
Dans cette partie, nous allons utiliser la méthode d'extraction des patrons basée sur des étiquettes linguistiques afin d'exploiter et de présenter certains aspects de l'emploi de la négation dans nos corpus, notamment dans les discours des quatre candidats à la Présidentielle 2007.
remonter
Choix de patrons
Afin d'obtenir un aperçu de l'emploi de la négation dans notre corpus, il fallait réfléchir au choix des patrons (suites des étiquettes linguistiques) qui pourraient donner l'information qui servirait le mieux à ce but. Ce choix doit être motivé, premièrement, par la pertinence des résultats obtenus et leur utilité pour une analyse plus détaillée ; et deuxièmement, par la lisibilité du graphe Pajek. En considérant ces critères, nous avons décidé d'observer deux constructions.
(1) Pronom personnel + Verbe présent : La première construction est le prédicat négatif ayant pour sujet un pronom personnel, par exemple : on n'écoute pas, nous ne sommes pas, il n'est pas, je ne crois pas, etc. Ceci peut donner une première impression de l'emploi de la négation au présent, bien que nous n'ayons aucune information sur le complément d'objet du prédicat (on n'écoute pas (QUOI?), je ne crois pas (QUOI?) et dans le cas des pronoms de la troisième personne (à part on qui est "omnipersonnels" et je, tu, nous, vous qui sont ancrés dans la situation communicationnelle de chaque discours) sur le référent du sujet (il (QUI?) ne croit pas). En plus, dans le cas des verbes être et avoir, nous ne disposons pas de l'information s'il s'agit d'un auxiliaire d'une forme verbale analytique.
(2) Verbe présent + Verbe infinitif : La seconde construction, plus spécifique, est le prédicat négatif au présent ayant pour sujet un des trois pronoms personnels je, nous ou on (pour assurer la connaissance du référent du sujet), suivi par un complément infinitif, par exemple : je ne peux pas accepter, nous ne pouvons pas ignorer, on ne peut pas travailler, etc. Même si le résultat est plus spécifique que dans le cas de la première construction, l'information n'est toujours pas complète car nous n'avons aucune information sur les compléments de l'infinitif (nous ne pouvons pas vouloir (QUOI?), nous ne pouvons pas laisser (QUOI?).
Les résultats que nous présentons peuvent servir surtout à montrer les possibilités de cette méthode et à donner une vision globale de l'emploi de la négation (ou plutôt de l'emploi des formes négatives) dans notre corpus. L'extraction d'informations plus concrètes (qu'est-ce qui est nié, au fait) devrait être le sujet d'une recherche plus approfondie.
remonter
Pronom personnel + Verbe présent
Outils d'extraction
Pour extraire la première construction, nous avons procédé de la façon suivante. Nous avons utilisé les fichiers XML contenant les discours de chaque candidat annotés par TreeTagger et à l'aide de la feuille de style extraitNegPatron.xsl (à télécharger ici) nous obtenons pour chaque candidat une liste de suites de tokens correspondants à la transformation XSL suivante :
<xsl:if test="(lm[(text()='ne')])and(following-sibling::e[1][tp[text()='VER:pres']])and
(preceding-sibling::e[1][tp[text()='PRO:PER']])">
<xsl:value-of select="preceding-sibling::e[1]/st"/><xsl:text> </xsl:text>
<xsl:value-of select="following-sibling::e[1]/lm"/>
</xsl:if>
Une partie du fichier de patrons obtenu à partir des discours de F. Bayrou est présenté ici :
on écouter nous pouvoir nous sommer|être il être il être ils participer on être on voter on être on être je avoir je croire elle être je voir
Nous allons utiliser les lemmes des verbes (lemmatisés par TreeTagger) pour rendre le graphe final plus clair - si nous nous étions servis des formes fléchies, le nombre de noeuds dans notre graphe pourrait être jusqu'à 6 fois plus important. En utilisant les lemmes, nous ne perdons pas d'information car chaque infinitif du verbe sera lié au pronoms personnel qui lui est associé dans le corpus. Cependant nous risquons d'amplifier certains problèmes de l'annotation automatique, car, comme on peut le voir dans l'extrait ci-dessus, certaines lemmatisations ne sont pas correctes ou ne sont pas désambiguïsées comme dans le cas de la forme sommes qui est lemmatisée en sommer | être (ce qui explique une présence relativement importante du verbe sommer dans nos graphes).
Les fichiers obtenus par la transformation XSL doivent être traités successivement par le script Perl patron2graphml.pl (à télécharger ici) et par une transformation XSL graphml2pajek.xsl (à télécharger ici) qui génèrent un fichier en format Pajek. Après quelques manipulations avec le programme Pajek qui servent principalement à l'amélioration de l'apparence visuelle du graphe, nous obtenons les graphes qui sont présentés plus bas.
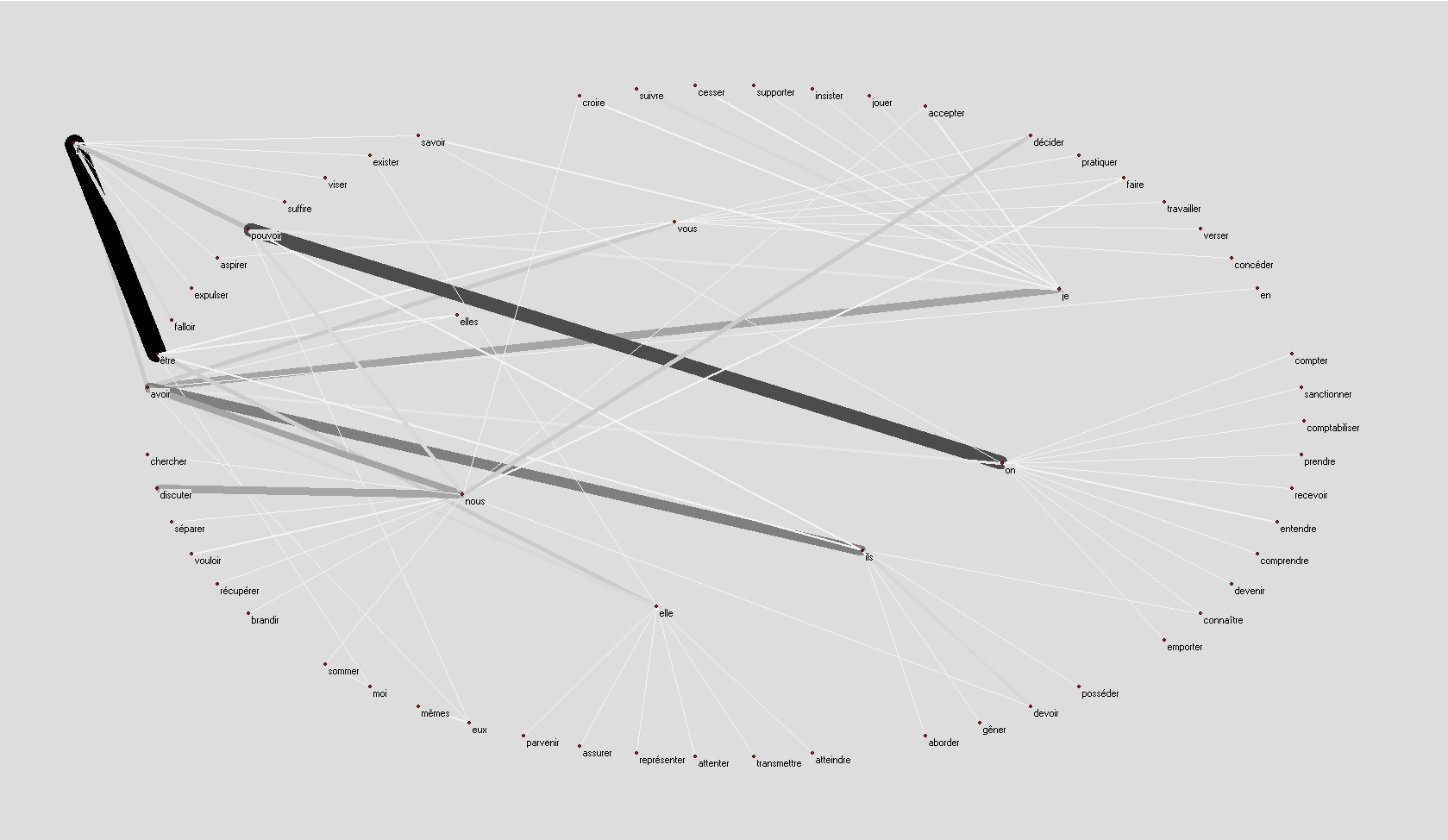
Les graphes doivent être lus de la façon suivante :
Le graphe à gauche contient tous les couples pronom personnel + infinitif du verbe qui figurent dans les constructions pronoms personnel + "ne" ou "n" + verbe au présent + adverbe négatif ("pas", "plus", "jamais", ...).
Le graphe à droite est identique au graphe à gauche, le nombre d'occurrences de chaque couple pronom personnel + verbe dans le corpus est exprimé par l'épaisseur de l'arc qui les relie, les arc les plus épais sont aussi les plus foncés.
Exemple : le noeud je relié par un arc avec le noeud croire représente la structure je ne crois (pas, rien, jamais, ...).
François Bayrou :


remonter
Jean-Marie Le Pen :

remonter
Nicolas Sarkozy :

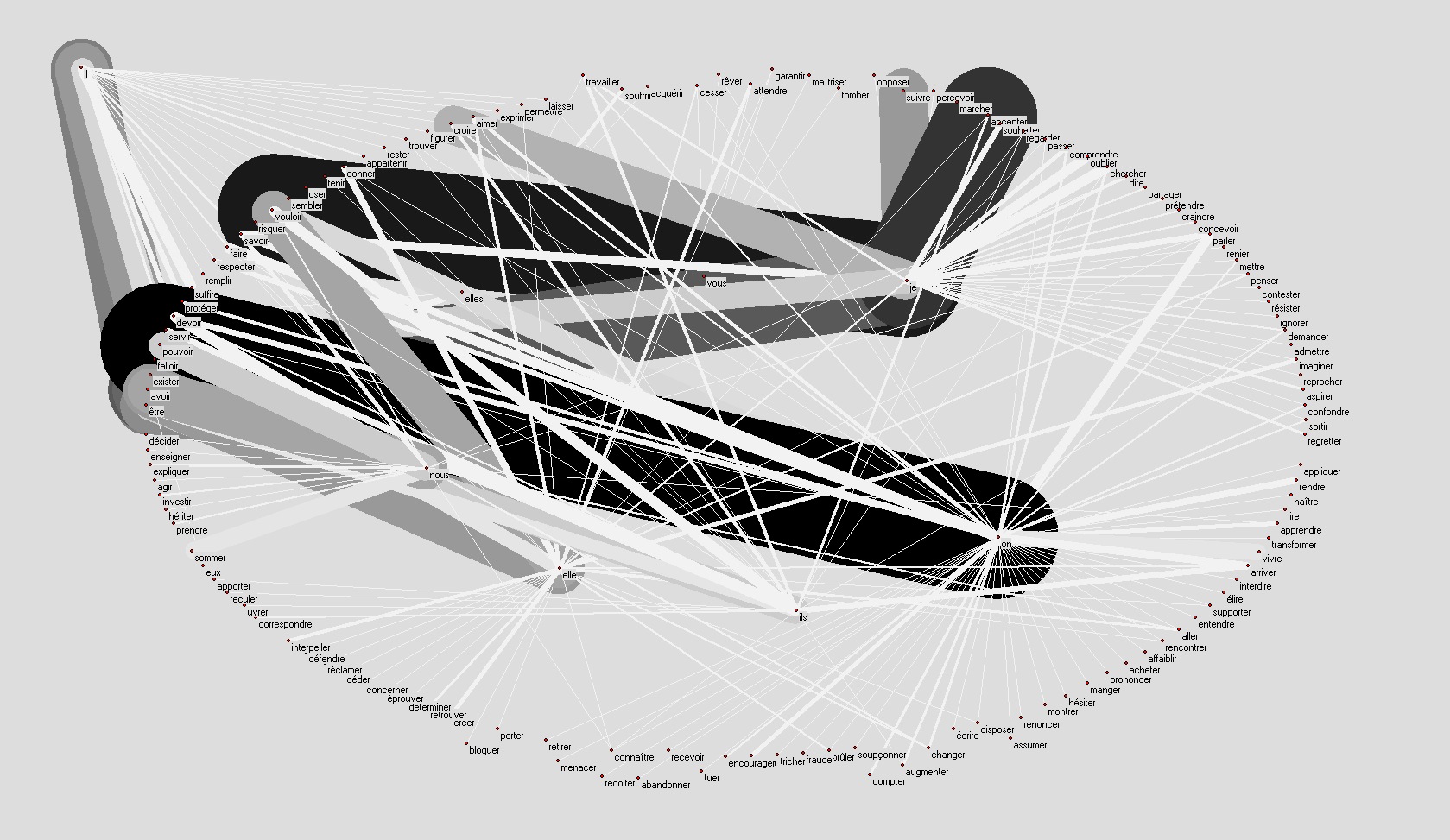
remonter
Ségolène Royal :

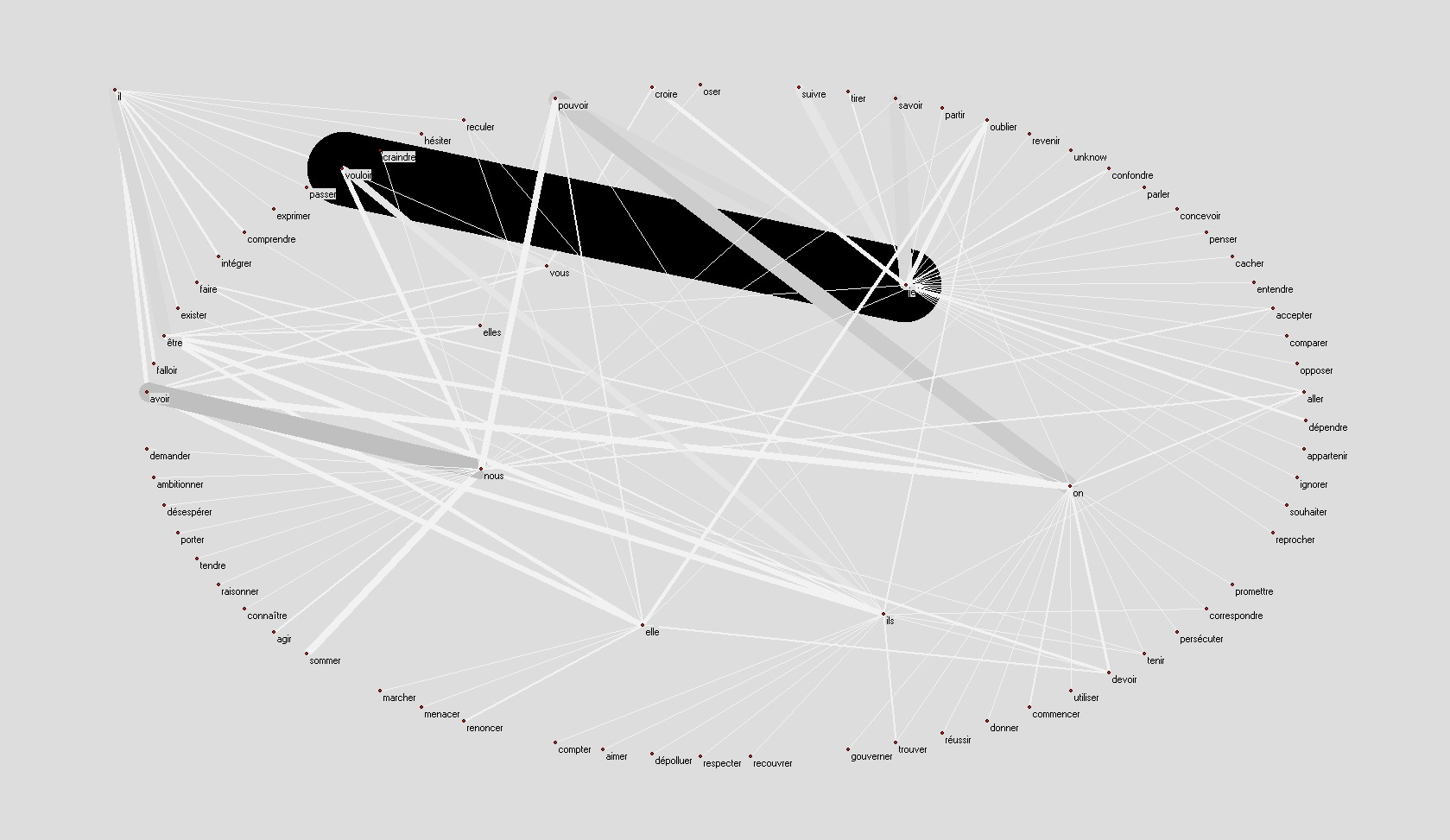
remonter
Verbe présent + Verbe infinitif
Outils d'extraction
Dans le cas de la seconde structure, nous avons travaillé directement avec les versions texte-brut du notre corpus annoté par TreeTagger, un fichier par candidat. L'objectif était d'extraire le patron PRO:PER ADV VER:pres ADV VER:infi et de préparer les fichiers de patrons ainsi obtenus pour un affichage avec Pajek.
L'extraction du patron a été faite par le script ExtraitPatronsLemme.pl (à télécharger ici) qui lit le fichier annoté par TreeTagger passé en premier argument et extrait les patrons inscrits dans le fichier qui est passé en tant que second argument de la commande.
Un extrait du fichier obtenu (fichier qui contient les suites extraites dans les discours d'un candidat) :
on ne pouvoir pas gouverner on ne pouvoir plus continuer on ne pouvoir pas continuer on ne pouvoir pas continuer nous ne pouvoir plus accepter on ne oser plus sortir nous ne pouvoir pas continuer nous ne pouvoir pas faire je ne vouloir pas finir on ne pouvoir pas créer
Le lemme du verbe prédicatif figure ici pour les mêmes raisons que dans la première structure. Un petit script bash (à télécharger ici) permet à partir de ce fichier d'obtenir trois fichiers ne contenant chacun que les patrons avec un pronom personnel donné (je, on, nous), comme par exemple (pour l'extrait du fichier ci-dessus) :
on ne pouvoir pas gouverner on ne pouvoir plus continuer on ne pouvoir pas continuer on ne pouvoir pas continuer on ne oser plus sortir on ne pouvoir pas créer
nous ne pouvoir plus accepter nous ne pouvoir pas continuer nous ne pouvoir pas faire
je ne vouloir pas finir
Chacun de ces fichiers est ensuite nettoyé par le script EnleveRubish.pl (à télécharger ici). Ce script, basé sur la segmentation du fichier d'entrée par les espaces, enlève le pronom personnel, le morphème négatif et l'adverbe négatif (pas, plus, ...) pour qu'on obtienne un fichier en format suivant (par exemple pour le pronom personnel on dans l'exemple ci-dessus:
pouvoir gouverner pouvoir continuer pouvoir continuer pouvoir continuer oser sortir pouvoir créer
Les fichiers ainsi prétraités peuvent être ensuite convertis en format Pajek, la procédure est identique à la première construction.
Nous obtenons ainsi trois graphes pour chaque candidat. Chaque graphe représente les patrons recensés pour un des trois pronoms personnels.
Les graphes doivent être lus de la façon suivante : un arc entre deux infinitifs représente une structure négative: Par exemple vouloir et faire reliés par un arc dans le premier graphe de Bayrou (le pronom personnel je) doit être lu je ne veux (pas, plus, jamais, ...) faire ou je ne fais (pas, plus, jamais, ...) vouloir, le choix de la bonne variante est clair dans la plupart des cas.
François Bayrou :
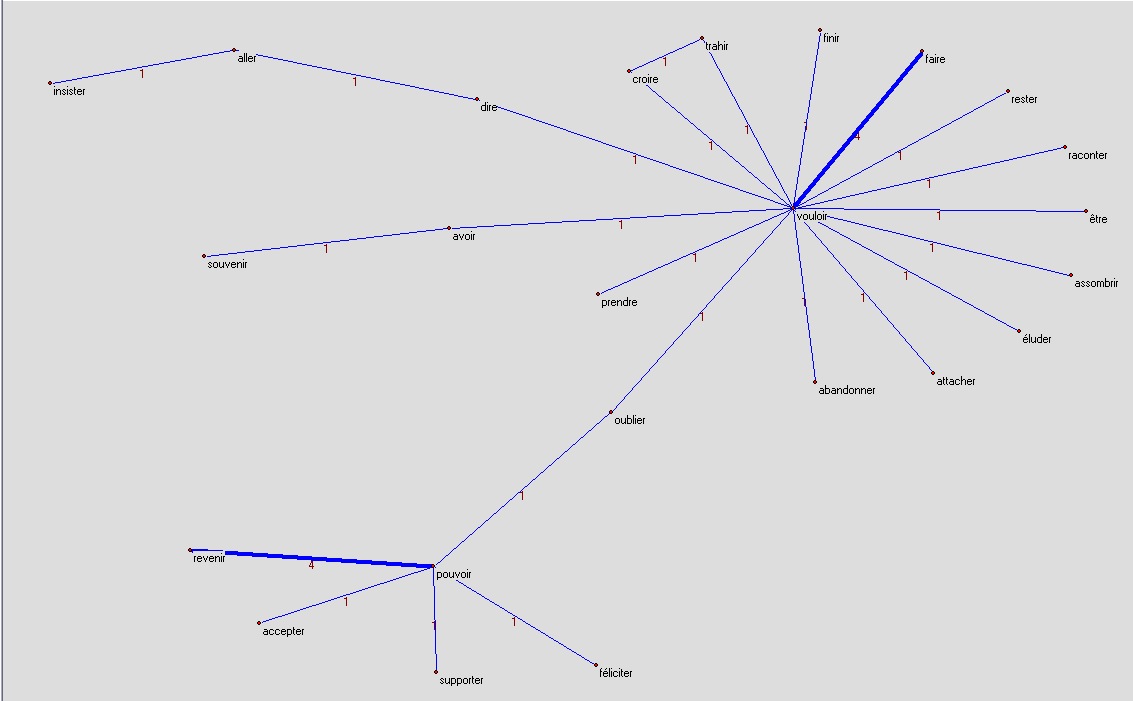 je
je
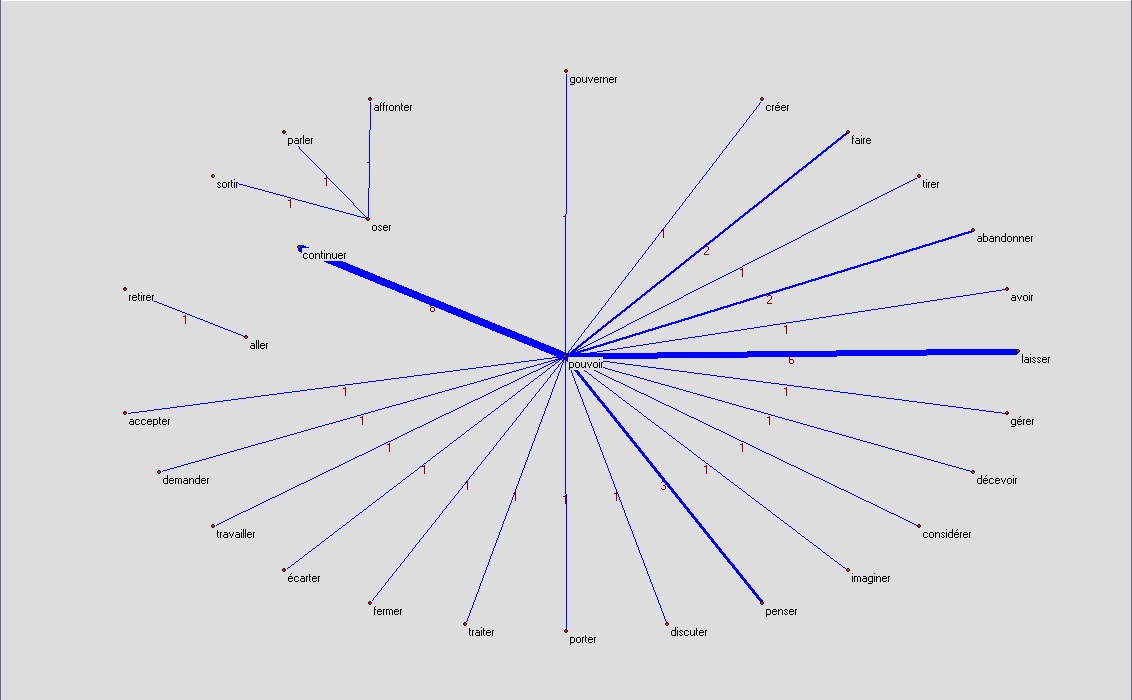 on
on
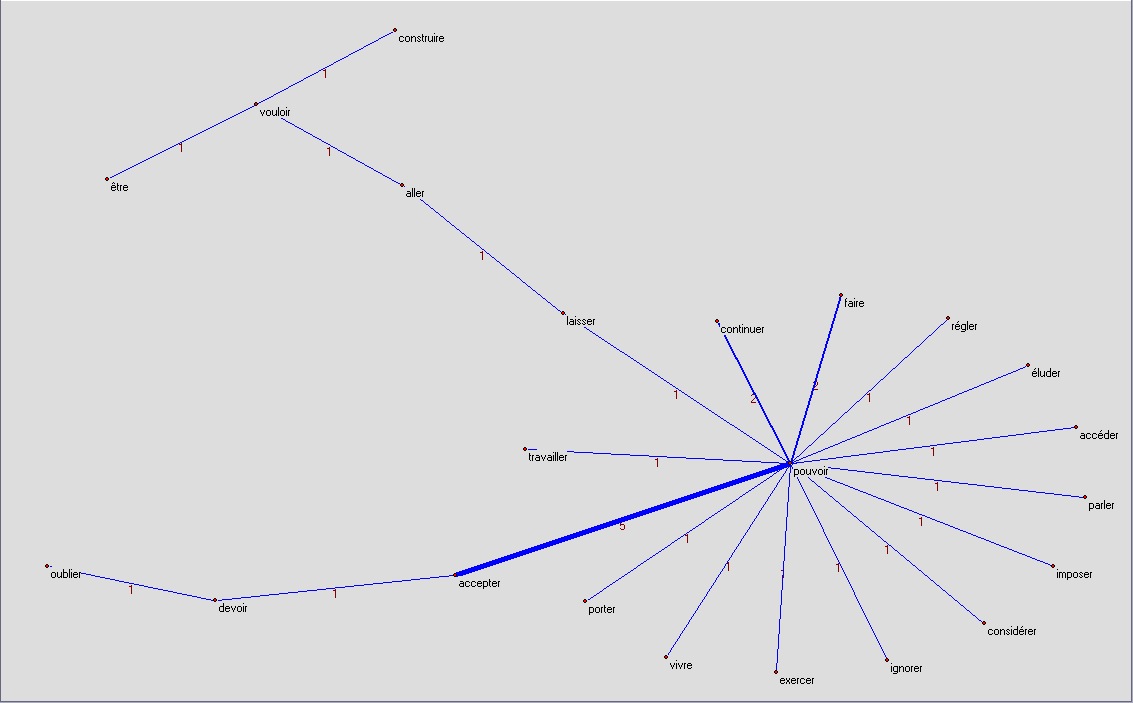 nous
nousje ne veux pas faire, je ne peux pas revenir ...
on ne peut pas continuer, on ne peut pas laisser, on ne peut pas penser ...
nous ne pouvons pas accepter, nous ne pouvons pas continuer, nous ne pouvons pas faire ...
remonter
Jean-Marie Le Pen :
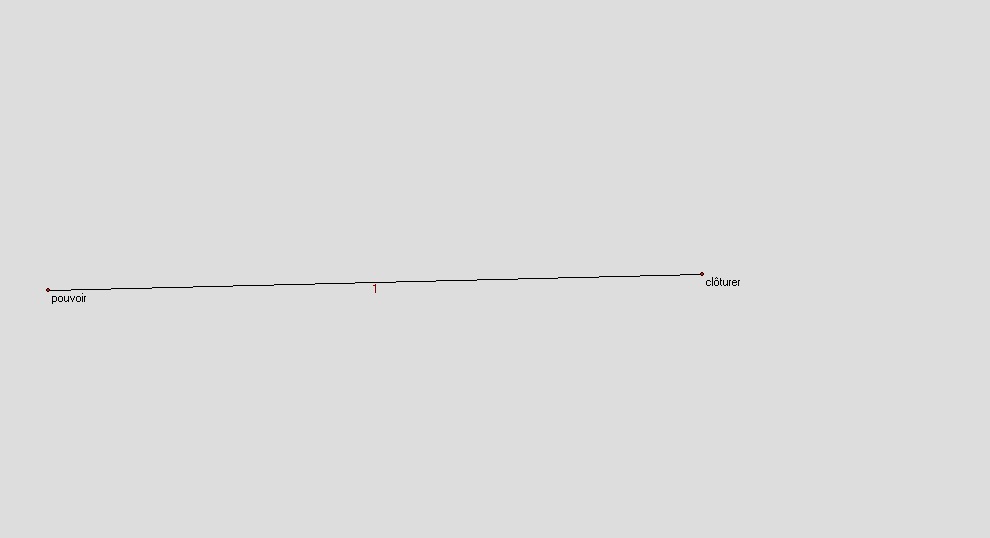 je
je
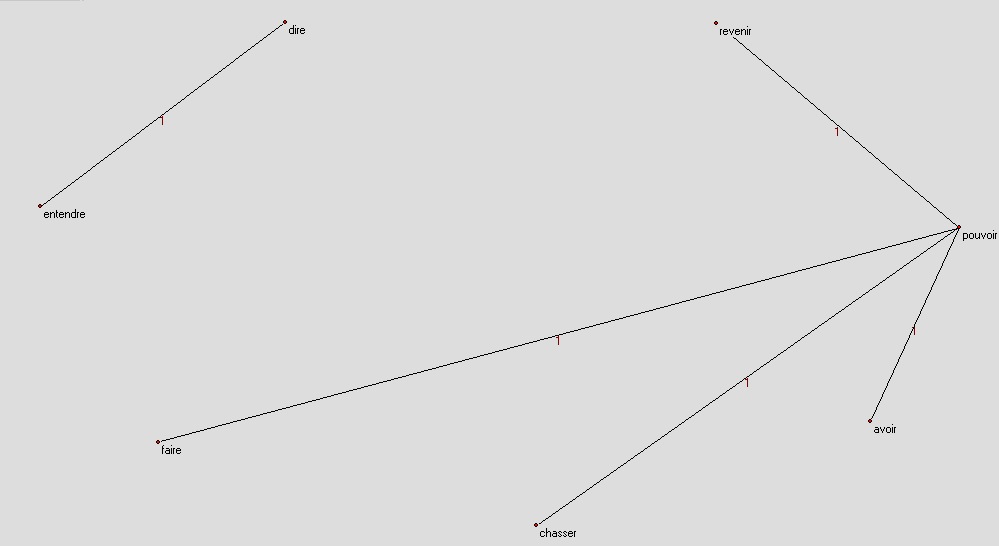 on
on
 nous
nousje ne peux pas clôturer
on n'entend pas dire, on ne peut pas revenir, on ne peut pas chasser
nous ne pouvons pas distraire
remonter
Nicolas Sarkozy :
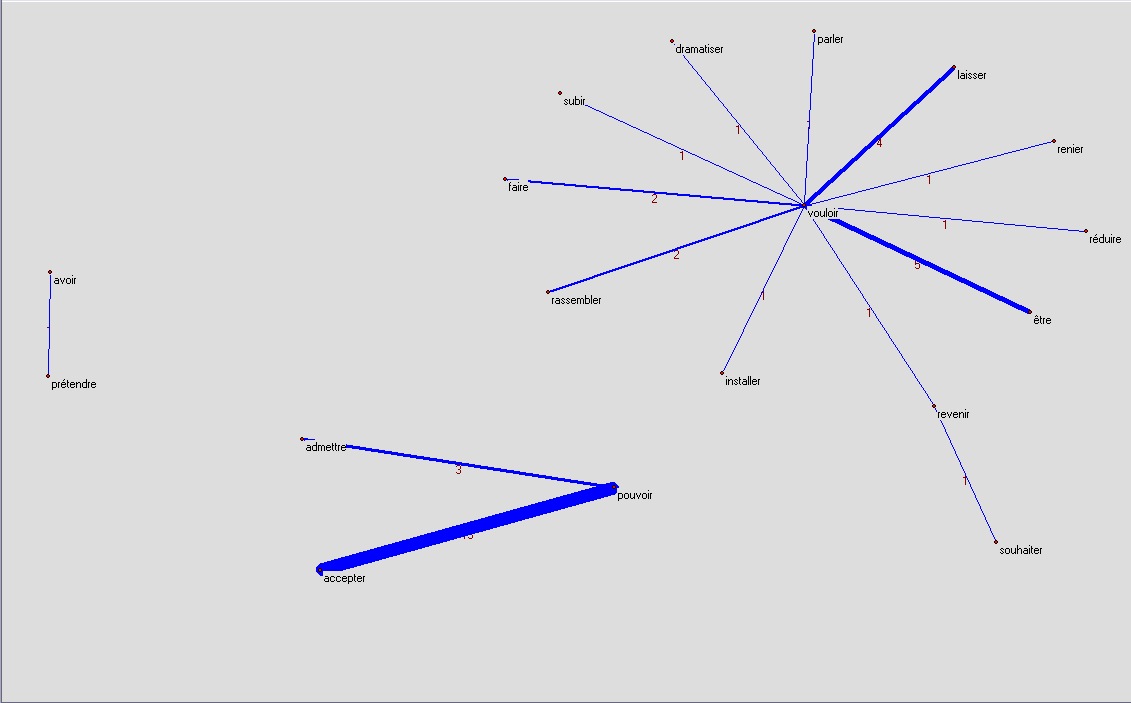 je
je
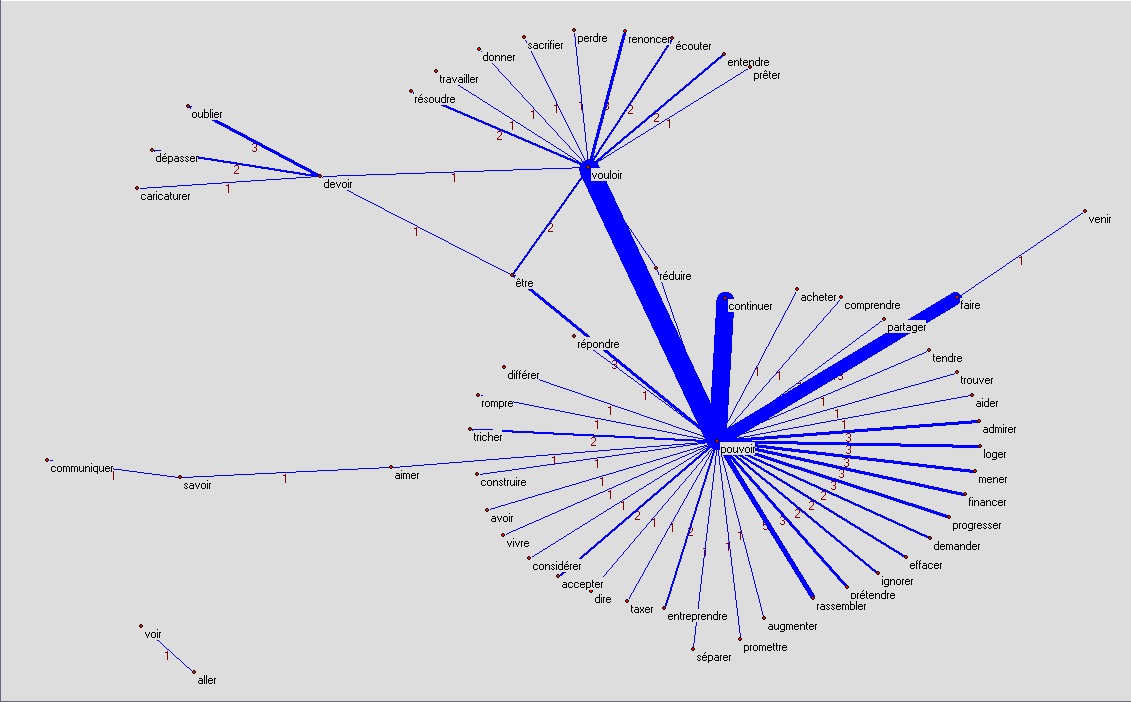 on
on
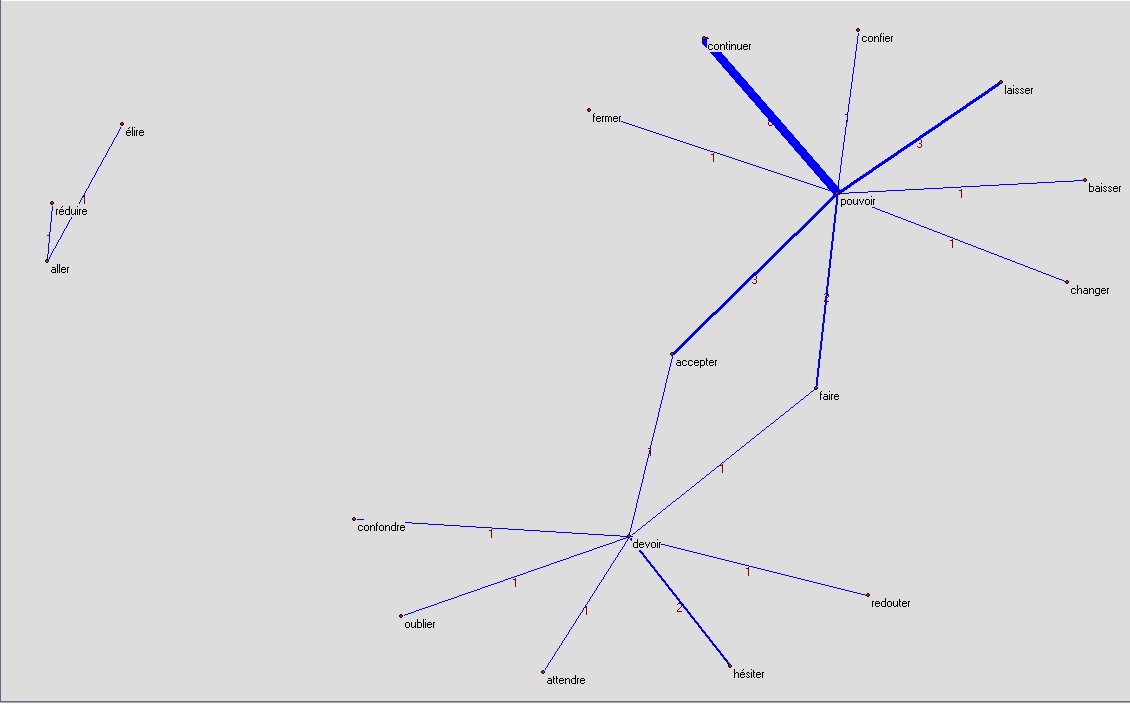 nous
nous
je ne peux pas accepter, je ne veux pas être, je ne veux pas laisser ...
on ne peut pas vouloir, on ne peut pas continuer, on ne peut pas faire ...
nous ne pouvons pas continuer, nous ne pouvons pas accepter, nous ne pouvons pas laisser ...
remonter
Ségolène Royal :
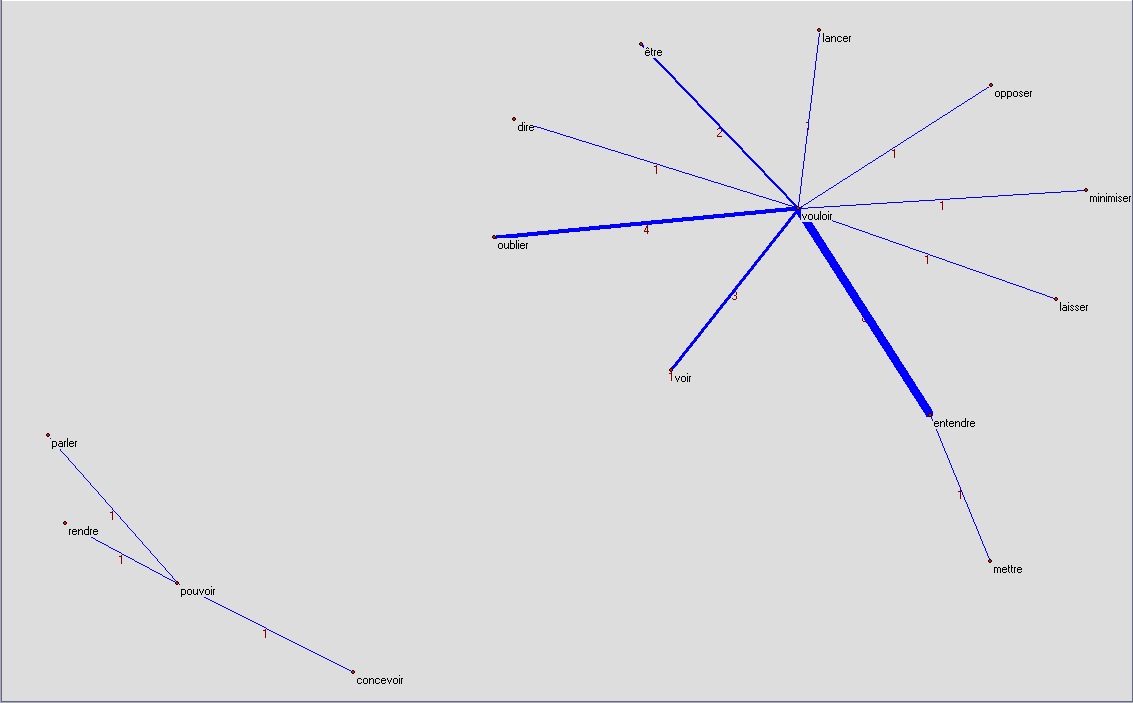 je
je
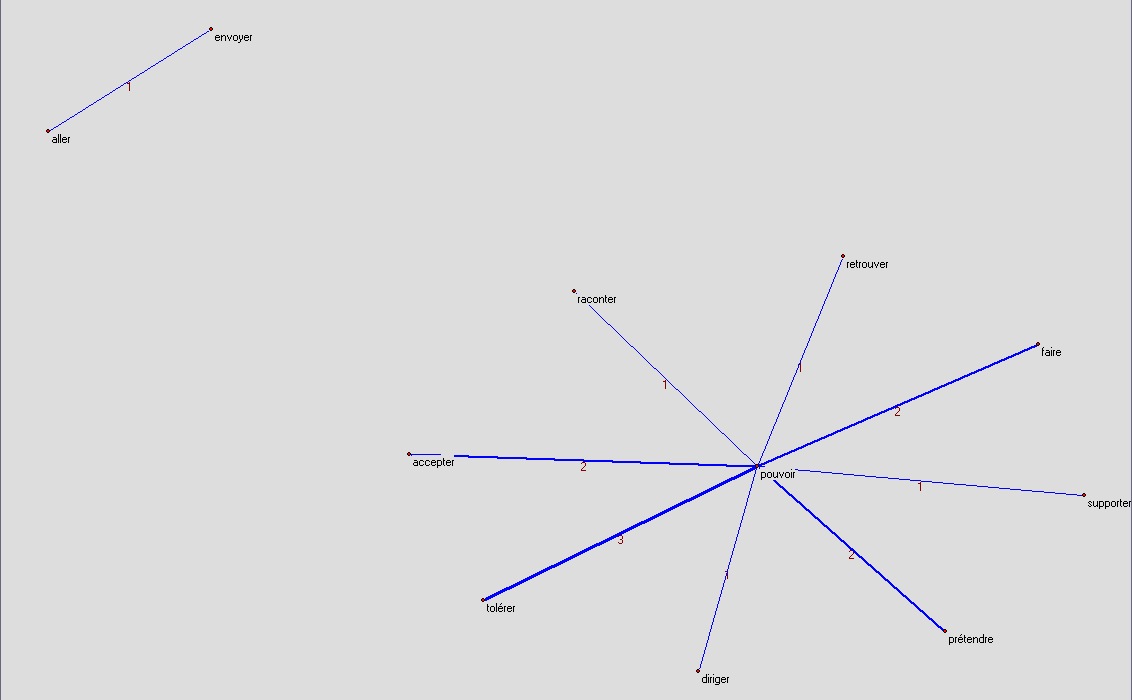 on
on
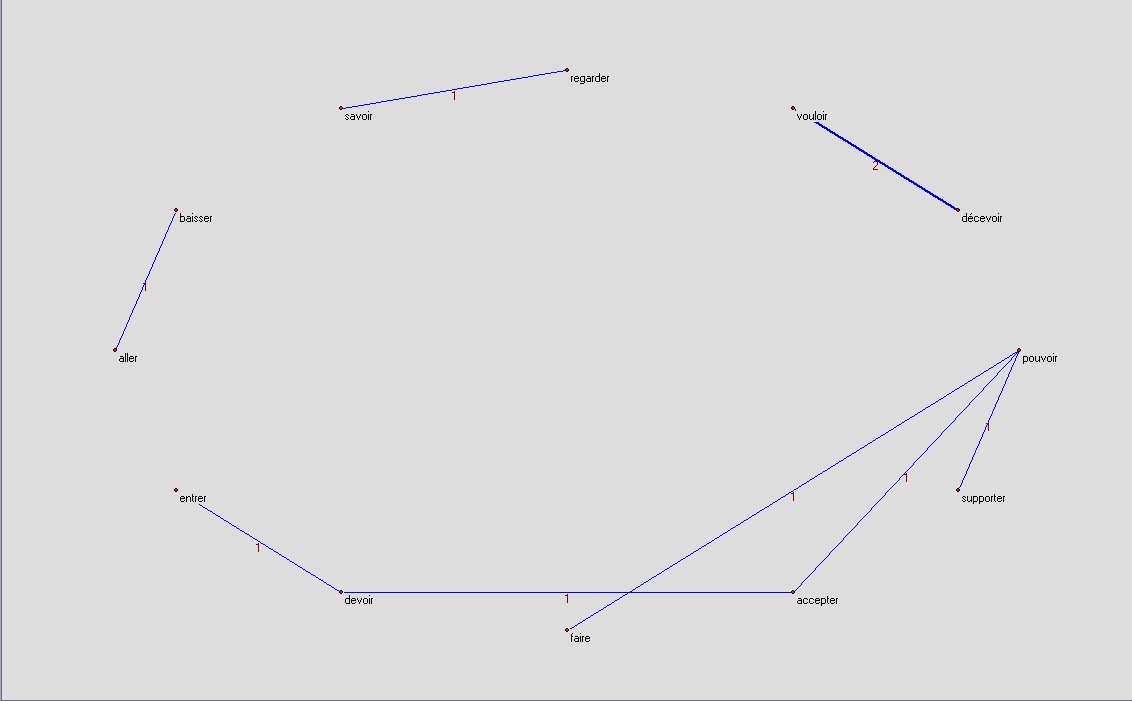 nous
nousje ne veux pas entendre, je ne veux pas oublier, je ne veux pas voir ...
on ne peut pas tolérer, on ne peut pas faire, on ne peut pas prétendre, on ne peut pas accepter ...
nous ne voulons pas décevoir ...