Mots sélectionnés.
Liste de départ
A partir des 60 entrées lexicales polysémiques étudiées par Jean Véronis dans le cadre de la campagne d'évaluation en désambiguïsation sémantique Romanseval (visibles ICI), nous avons sélectionné dans un premier temps uniquement les Noms et Adjectifs, laissant ainsi de côté les verbes. Cela nous permettait ainsi de n'avoir plus que 40 mots.
Création de notre propre liste
Grâce à Lexico 3, nous avons ensuite pu étudier la fréquence de chacun de ces mots dans chacun de nos corpus respectifs. A ce stade du projet, nous avons travaillé sur le corpus complet, comprenant la surface et la profondeur.
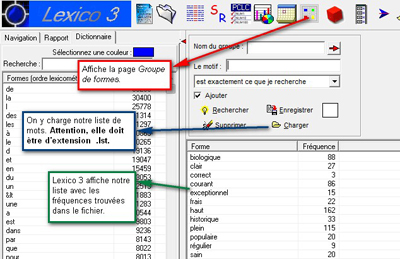
Chaque résultat a été copié et placé sous Excel. Classé par ordre de fréquence, chaque mot s'est vu attribué un rang (de 1 pour le plus fréquent à 40). Il nous a ensuite suffit de faire une moyenne des rangs de chaque mot. Nous n'avons alors pris que les 20 premiers. Ne pas se contenter de la fréquence et passer par le rang de chaque mot nous a permis de limiter l'impact de la taille de chaque fichier rubrique. En effet, les fichiers de surface peuvent varier entre 500 Ko et 2Mo.
Liste finale
|
Et maintenant, au boulot!
Haut de page